在我java做数据结构的题时,对于java运行效率一直都很费解!!!
看似改进了代码,但是运存和运行时间并没改变!
“改进”前的代码:
import java.util.*;
public class Main {
//初始数组
public static int[] array;
//维护set集合的list
public static List<Set<Integer>> setArray=new ArrayList<>();
public static void main(String[] args) {
//提前声明,避免在循环中声明占内存
int z,a,b;
//创建一个文本扫描器检测键盘输入
Scanner scanner=new Scanner(System.in);
//N个元素
int N=scanner.nextInt();
//M个操作
int M=scanner.nextInt();
//初始化array,确保下标即为对应的值
array=new int[N+1];
for (int i=0;i<N+1;i++){
array[i]=i;
}
//循环操作
for (int i=0;i<M;i++){
z=scanner.nextInt();
a=scanner.nextInt();
b=scanner.nextInt();
if (z==1){
merge(a,b);
}else if (z==2){
findTwo(a,b);
}
}
}
/**
* 1.首先在数组中查找,找到则说明不在一起
* 2.若未找到则到list中遍历查找,返回所在集合(若在数组中则返回null)
* 注意:不必遍历,因为每个数组的下标即为它的值
* @param a
* @return
*/
private static Set<Integer> findOne(int a){
if (array[a]!=0){
return null;
}
//在维护set集合的数组中遍历
for (Set<Integer> set:setArray){
//调用contain方法,若存在则返回该集合
if (set.contains(a)){
return set;
}
}
//这道题不可能执行到这步,除非系统想搞我们!当然我们也不怕
return null;
}
/**
* 1.调用findOne查找a所在集合
* 2.在集合中查找是否存在b
* 3.若有则输出打印Y,没有则N
* @param a
* @param b
*/
public static void findTwo(int a,int b){
Set<Integer>set=findOne(a);
if (set==null){
//集合为空时,即a在数组中时输出N
System.out.println("N");
}else if (set.contains(b)){
System.out.println("Y");
}else{
//不包含时输出N
System.out.println("N");
}
}
/**
* 1.用私有方法findOne查询a,b所在集合
* 2.合并
* @param a
* @param b
*/
public static void merge(int a,int b){
Set<Integer> set1=findOne(a);
Set<Integer> set2=findOne(b);
//分别讨论几种情况
if (set1==null&&set2!=null){
set2.add(a);
//原来数组的值清0
array[a]=0;
}else if (set1!=null&&set2==null){
set1.add(b);
array[b]=0;
}else if (set1==null&&set2==null){
//此时需要创建一个set集合,并清0
Set<Integer> set=new HashSet<Integer>();
set.add(a);
set.add(b);
//别忘了加入list集合,粗心的我就忘了!汗。。。
setArray.add(set);
array[a]=0;
array[b]=0;
}else {
//判断两个集合是否相等
if (set1!=set2){
//确保小的集合加入大的集合
if (set1.size()<set2.size()){
set2.addAll(set1);
//把多余的set集合清出list,粗心的我又忘了......
setArray.remove(set1);
}else {
set1.addAll(set2);
setArray.remove(set2);
}
}
}
}
}
时间效率如下图:
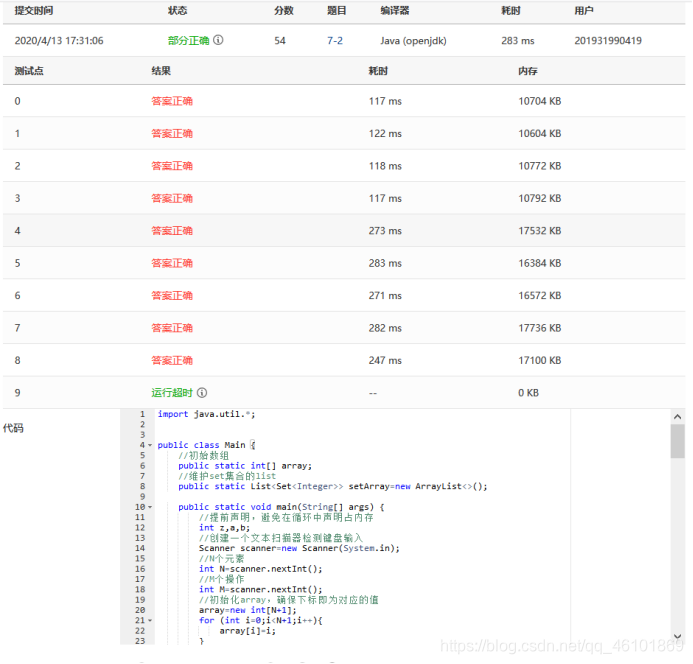
我做出了改进,缩短了很多代码,而且避开使用封装好的类,尽量写底层代码,以争取尽可能好的效果
可是。。。。。。。
以下是我“改进后”代码:
import org.w3c.dom.Node;
import java.util.*;
public class Main {
//此数组下标即为其data
public static int[] array;
public static void main(String[] args) {
//提前声明,避免在循环中声明占内存
int z,a,b;
//创建一个文本扫描器检测键盘输入
Scanner scanner=new Scanner(System.in);
//N个元素
int N=scanner.nextInt();
//M个操作
int M=scanner.nextInt();
//初始化array,确保下标即为对应的值
array=new int[N+1];
for (int i=0;i<N+1;i++){
//初始化数组,-1表示根节点,且该集合规模为1(根节点值得绝对值表示该树的大小,负号表示根节点),即初始化时每个数都是单个集合
array[i]=-1;
}
//循环操作
for (int i=0;i<M;i++){
z=scanner.nextInt();
a=scanner.nextInt();
b=scanner.nextInt();
if (z==1){
merge(a,b);
}else if (z==2){
check(a,b);
}
}
}
/**
*
* @param a
* @return
*/
private static int findOne(int a){
if (array[a]<0){
return a;
}else{
//先把值存下来以便按秩递归
int temp=array[a];
//据说是伪递归,编译的时候会自动写成循环,不知道jvm会不会这么做
//存疑
return array[a]=findOne(temp);
}
}
/**
* 1.调用findOne查找a所在集合
* 2.在集合中查找是否存在b
* 3.若有则输出打印Y,没有则N
* @param a
* @param b
*/
public static void check(int a,int b){
int m=findOne(a);
int n=findOne(b);
if (m!=n){
System.out.println("N");
}else {
System.out.println("Y");
}
}
/**
* 1.用私有方法findOne查询a,b所在集合
* 2.合并
* @param a
* @param b
*/
public static void merge(int a,int b){
int m=findOne(a);
int n=findOne(b);
if (m!=n){
if (array[m]<=array[n]){
array[n]+=array[m];
array[m]=n;
}else{
array[m]+=array[n];
array[n]=m;
}
}
}
}
结果如图:
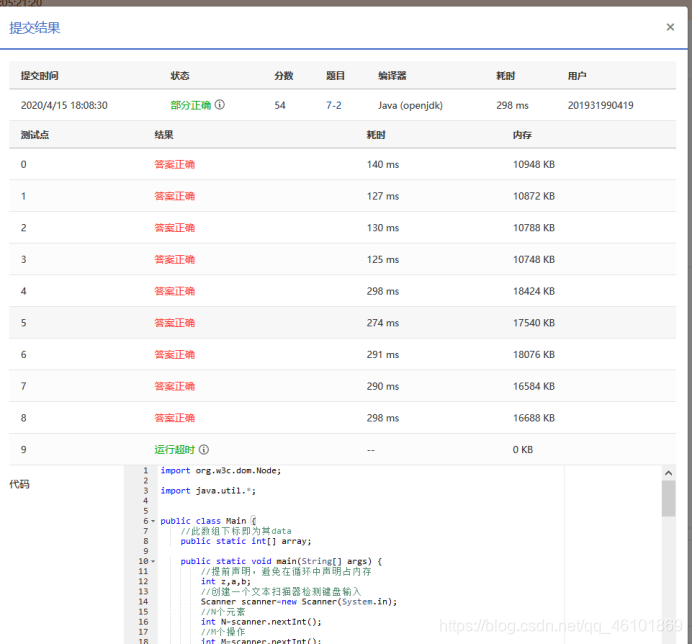
可以发现结果并没有什么改进,甚至比原来的运行效率还要低,这就是我不能理解的地方,希望有能力的大佬能解答一下。
谢谢!