一、比赛地址:
2020第六届百度&西安交大大数据竞赛暨IKCEST第二届“一带一路”国际大数据竞赛
二、比赛简介:
竞赛背景:
本届大数据竞赛在中国工程院、教育部高等学校大学计算机课程教学指导委员会及丝绸之路大学联盟的指导下,由联合国教科文组织国际工程科技知识中心(IKCEST)、中国工程科技知识中心(CKCEST)、百度公司及西安交通大学共同主办,旨在放眼“一带一路”倡议沿线国家,通过竞赛方式挖掘全球大数据人工智能尖端人才,实现政府—产业—高校合力推动大数据产业研究、应用、发展的目标,进一步夯实赛事的理论基础与实践基础,加快拔尖AI创新人才培养。
传染病(Contagious Diseases)的有效防治是全人类面临的共同挑战,如何通过大数据,特别是数据的时空关联特性,来精准预测传染病的传播趋势和速度,将极大有助于人类社会控制传染病,保障社会公共卫生安全。希望借助此次竞赛,充分发挥全球选手的聪明才智,运用大数据技术助力传染病的传播预测和控制,增强人类社会合作抗风险的意识和能力。
任务描述:
针对赛题所构造的若干虚拟城市,构造传染病群体传播预测模型,根据该地区传染病的历史每日新增感染人数、城市间迁徙指数、网格人流量指数、网格联系强度和天气等数据,预测群体未来一段时间每日新增感染人数。
赛题共涉及11个虚拟城市90天的感染情况,每个城市有若干重点区域。初赛要求针对所提供的5个城市,利用每个城市各区域前45天的样本数据进行训练,预测每个城市各区域后30天每天的新增感染人数。复赛要求针对包含初赛城市在内的11个城市,利用每个城市各区域前60天的样本数据进行训练,预测每个城市各区域后30天每天的新增感染人数。
三、数据提取:
这里暂时先只提取了每个地区每天的新增感染数:
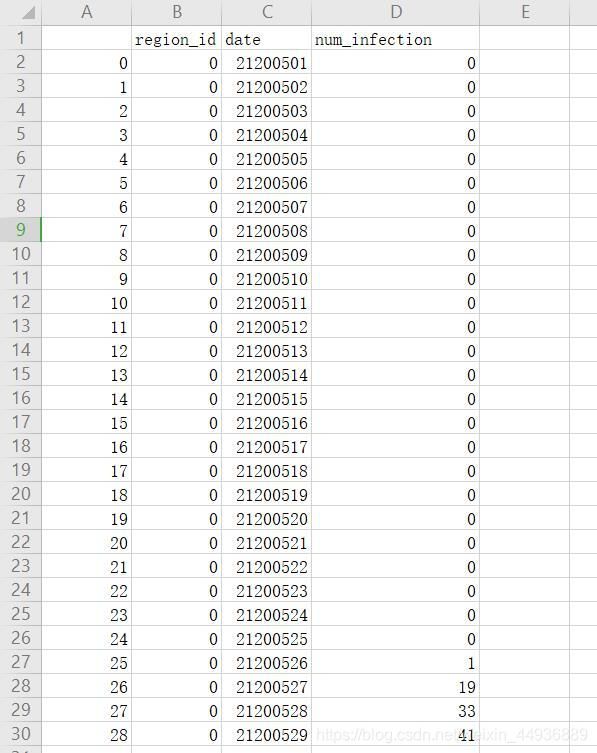
读取数据:
import pandas as pd
data = pd.read_csv('./data.csv', header=0, index_col=0)
headers = list(data.columns.values)
city = ['city_id_'+v for v in ['A', 'B', 'C', 'D', 'E']]
print(city)
raw_datas = []
drop = ['region_id', 'date']
city_region_list = []
for c in city:
city_data = data[data[c] == 1]
ids = list(city_data['region_id'].values)
max_num = max(ids)
for i in range(max_num+1):
new = city_data[city_data['region_id'] == i]
new = new.drop(drop, axis=1)
raw_datas.append(new.values)
city_region_list.append((c.split('_')[-1], i))
train_data = []
train_lbls = []
test_data = []
for value in raw_datas:
lbls = value[:, 0]
x = value[:15]
y = lbls[15:45]
train_data.append(x)
train_lbls.append(y)
四、训练模型:
使用LSTM:
import matplotlib.pyplot as plt
from keras.models import Sequential
from keras import layers
from keras import regularizers
import os
import keras
import keras.backend as K
import numpy as np
from keras.callbacks import LearningRateScheduler
data = train_data
target = train_lbls
print(len(data), data[0].shape)
print(len(target), target[0].shape)
dims = data[0].shape[2]
model = Sequential()
model.add(layers.LSTM(64, input_shape=(15, 1))
model.add(layers.Dense(30))
model.summary()
save_path = './model.h5'
# if os.path.isfile(save_path):
# model.load_weights(save_path)
# print('reloaded.')
adam = keras.optimizers.adam(0.002)
model.compile(optimizer=adam,
loss="mean_squared_logarithmic_error")
# 计算学习率
def lr_scheduler(epoch):
# 每隔100个epoch,学习率减小为原来的0.5
if epoch % 100 == 0 and epoch != 0:
lr = K.get_value(model.optimizer.lr)
K.set_value(model.optimizer.lr, lr * 0.5)
print("lr changed to {}".format(lr * 0.5))
return K.get_value(model.optimizer.lr)
lrate = LearningRateScheduler(lr_scheduler)
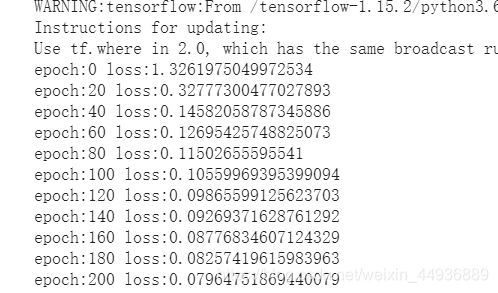
history = model.fit(np.array(data), np.array(target), epochs=200,
batch_size=64, validation_split=0.1,
verbose=1, callbacks=[lrate], shuffle=True)
训练结果: