上一讲中,我们大概的分析了下KafkaProducer消息发送流程,本节将从源码的角度深入分析消息发送过程。
消息发送之前的准备工作都已经在客户端KafkaProducer的构造器中完成,包括:配置项加载、序列器初始化、消息收集器初始化、消息发送线程初始化等等。而消息的发送入口在send()方法中:
Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback);
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
// intercept the record, which can be potentially modified; this method does not throw exceptions
ProducerRecord<K, V> interceptedRecord = this.interceptors == null ? record : this.interceptors.onSend(record);
return doSend(interceptedRecord, callback);
}
1、拦截器
拦截器ProducerInterceptor是一个接口,我们可以自定义实现,在客户端KafkaProducer的构造器中会去查找ProducerInterceptor的实现并加载到集合中:
// 客户端KafkaProducer构造器初始化拦截器
List<ProducerInterceptor<K, V>> interceptorList = (List) (new ProducerConfig(userProvidedConfigs, false)).getConfiguredInstances(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,ProducerInterceptor.class);
this.interceptors = interceptorList.isEmpty() ? null : new ProducerInterceptors<>(interceptorList);
在消息发送之前,我们可以使用拦截器对消息进行处理:
ProducerInterceptors.onSend()
public ProducerRecord<K, V> onSend(ProducerRecord<K, V> record) {
ProducerRecord<K, V> interceptRecord = record;
for (ProducerInterceptor<K, V> interceptor : this.interceptors) {
try {
// 自定义的拦截器执行逻辑
interceptRecord = interceptor.onSend(interceptRecord);
} catch (Exception e) {
// 省略...
}
}
return interceptRecord;
}
一般没有拦截处理的逻辑就不需要实现该接口。
2、元数据更新,获取最新Cluster集群数据
Metadata封装了Kafka集群Cluster对象,并且保存Cluster数据的最后更新时间、版本号、是否需要更新数据等字段。
由于集群中分区数量、Leader副本是可能随时变化的,所以在发送消息之前,需要确认发送到topic对应的metadata的分区是可用的(有可能过期或者不存在等等),返回最新的集群数据。
- metadata添加当前topic,不存在说明是新topic,调用requestUpdateForNewTopics,将needUpdate设置为true表示需要更新最新数据;
- 尝试获取topic对应分区的详细信息,存在即返回集群信息cluster;
- 不存在最新topic的分区信息,唤醒sender线程更新Metadata中保存的Kafka集群元数据Cluster.
- 调用metadata.awaitUpdate等待sender线程更新完元数据;
- 若未获取到topic对应的分区信息,继续循环上面2个步骤,直至超时抛出异常;
private ClusterAndWaitTime waitOnMetadata(String topic, Integer partition, long maxWaitMs) throws InterruptedException {
// metadata添加当前topic,不存在说明是新topic,需要更新最新数据
metadata.add(topic);
// 从元数据中获取topic对应的分区信息, cluster维护了topic与分区的关系、leader/follower等关系
Cluster cluster = metadata.fetch();
Integer partitionsCount = cluster.partitionCountForTopic(topic);
// 如果集群中分区存在并且, 大于之前的分区(说明是最新的数据),直接返回一个ClusterAndWaitTime,包含了cluster信息
if (partitionsCount != null && (partition == null || partition < partitionsCount))
return new ClusterAndWaitTime(cluster, 0);
// 如果cluster不存在分区信息或者是过期数据,就唤醒sender线程去更新metadata数据
long begin = time.milliseconds();
long remainingWaitMs = maxWaitMs;
long elapsed;
do {
log.trace("Requesting metadata update for topic {}.", topic);
metadata.add(topic);
int version = metadata.requestUpdate();
// 唤醒sender线程, 更新metadata
sender.wakeup();
try {
// 阻塞等待元数据更新完
metadata.awaitUpdate(version, remainingWaitMs);
} catch (TimeoutException ex) {
throw new TimeoutException("Failed to update metadata after " + maxWaitMs + " ms.");
}
cluster = metadata.fetch();
elapsed = time.milliseconds() - begin;
if (elapsed >= maxWaitMs)
throw new TimeoutException("Failed to update metadata after " + maxWaitMs + " ms.");
if (cluster.unauthorizedTopics().contains(topic))
throw new TopicAuthorizationException(topic);
remainingWaitMs = maxWaitMs - elapsed;
partitionsCount = cluster.partitionCountForTopic(topic);
} while (partitionsCount == null);
if (partition != null && partition >= partitionsCount) {
throw new KafkaException(
String.format("Invalid partition given with record: %d is not in the range [0...%d).", partition, partitionsCount));
}
return new ClusterAndWaitTime(cluster, elapsed);
}
再回到Sender线程中,看看Sender线程是如何更新Metadata中的cluster数据的:
主线程通过wakeup()唤醒Sender线程,间接调用间接唤醒 NetworkClient 的poll()去服务端拉取Cluster信息:
NetworkClient.poll(long timeout, long now):
public List<ClientResponse> poll(long timeout, long now) {
// ...
// 判断是否需要更新Metadata
long metadataTimeout = metadataUpdater.maybeUpdate(now);
try {
this.selector.poll(Utils.min(timeout, metadataTimeout, requestTimeoutMs));
} catch (IOException e) {
log.error("Unexpected error during I/O", e);
}
// process completed actions
long updatedNow = this.time.milliseconds();
List<ClientResponse> responses = new ArrayList<>();
handleCompletedSends(responses, updatedNow);
// 处理已完成的接收响应, 包括Metadata数据
handleCompletedReceives(responses, updatedNow);
// ...
return responses;
}
3、消息序列化
获取到需要发送的topic对应的分区、cluster信息后,紧接着就需要对消息进行序列化,将其变成字节数组:
byte[] serializedKey;
// 3. 序列化key/value
try {
serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
} catch (ClassCastException cce) {
// ...
}
byte[] serializedValue;
try {
serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());
} catch (ClassCastException cce) {
// ...
}
keySerializer 和 valueSerializer已经在客户端KafkaProducer构造器中初始化过。
默认提供的序列化类如下,我们也可以自己拓展:
4、消息分区
消息经过序列化变成字节流之后,需要确定消息发往哪个分区,即:消息分区。
我们知道,分区在Kafka Cluster集群中有多个副本,1个Leader Replica(LR) 和多个Follower Replica(FR),其中LR只会存在一个Broker上。生产者需要确定将消息发送到哪个分区,常见的分区算法有:
- 轮询策略
- 随机策略
- Key-ordering 策略
- 自定义分区策略
(1)轮询策略
轮询策略也叫Round-robin 策略,按分区顺序分配。比如一个主题有3个分区,那么第1条消息被发送到分区0,第2条消息被发送到分区1,第3条消息被发送到分区2,第4条消息被发送到分区0,依次类推。
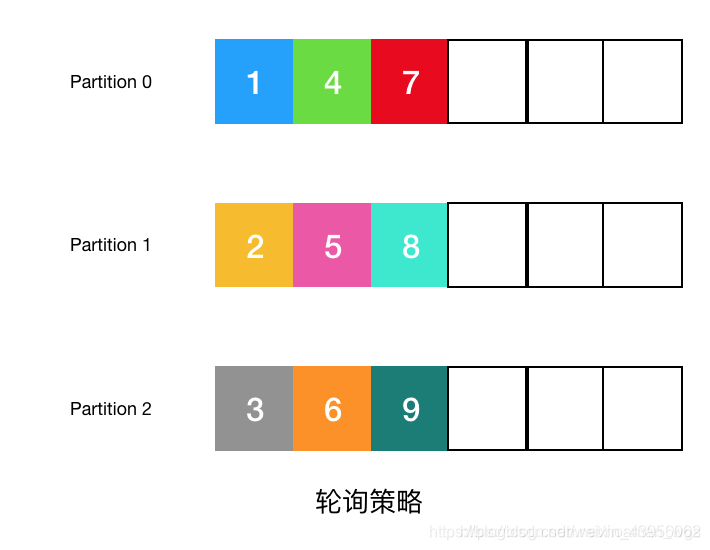
轮询策略有很优秀的负载均衡的作用,保证消息最大限度被平均分配到所有分区上,所以轮询策略是Kafka默认的分区算法。
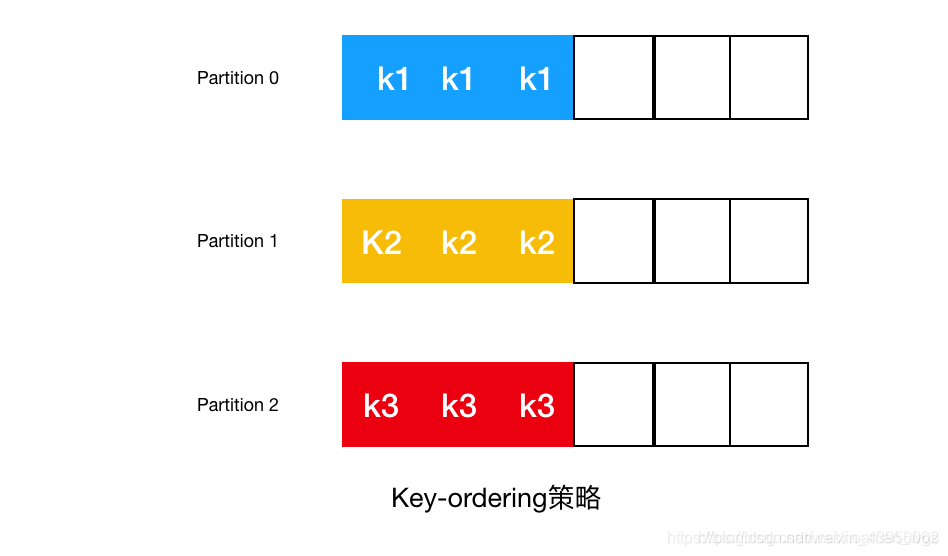
(2)Key-ordering 策略
Key-ordering 策略是指如果指定了key,同一个key会被发送到同一个分区上。这种策略比较常用,一般如果需要保证消息的有序性,可以使用该策略。
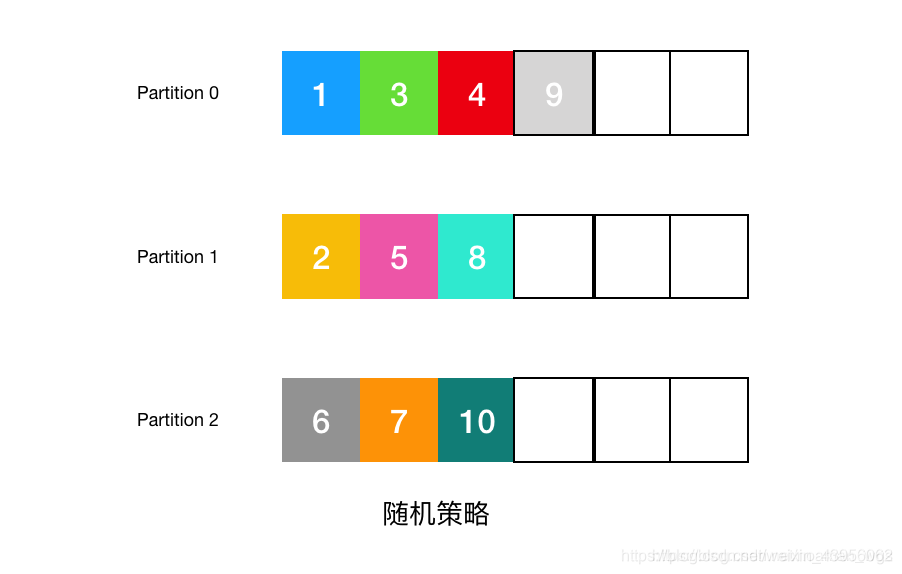
(3)随机策略
随机策略也称 Randomness 策略,即消息会被任意发送到任一个分区上。
(4)自定义分区策略
我们可以自定义分区策略,只要实现org.apache.kafka.clients.producer.Partitioner接口,并显示配置生产者端的参数partitioner.class即可。
现在来看看KafkaProducer中的分区是如何实现的:
int partition = partition(record, serializedKey, serializedValue, cluster);
tp = new TopicPartition(record.topic(), partition);
分区选择实现Partitioner接口中,默认实现在DefaultPartitioner中:
- 首先获取topic对应的分区总数量numPartitions,注意,该值跟availablePartitions不同,availablePartitions是可用分区数量,因为有些分区可能不可用;availablePartitions>0,取availablePartitions;若availablePartitions<=0,表示未可用分区,那么取numPartitions值
- 如果未指定key,使用轮询策略,每次返回一个递增的值(nextValue)后对分区总数进行取模获取一个分区;
- 如果指定key,对key进行hash后再对分区总数就取模运算,只要key、分区数不变,则消息都会发往同一个分区。
DefaultPartitioner.partition()
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
// numPartitions-总分区; availablePartitions-可用分区
int numPartitions = partitions.size();
// 未指定key,使用轮询策略(每次分区+1);
if (keyBytes == null) {
int nextValue = nextValue(topic);
// 获取topic可用分区数量
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
// 可用分区数>0
if (availablePartitions.size() > 0) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// 无可用分区数,返回总分区数(即使此时的分区都是不可用)
return Utils.toPositive(nextValue) % numPartitions;
}
} else {
// 指定key,对key进行hash后选择分区
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
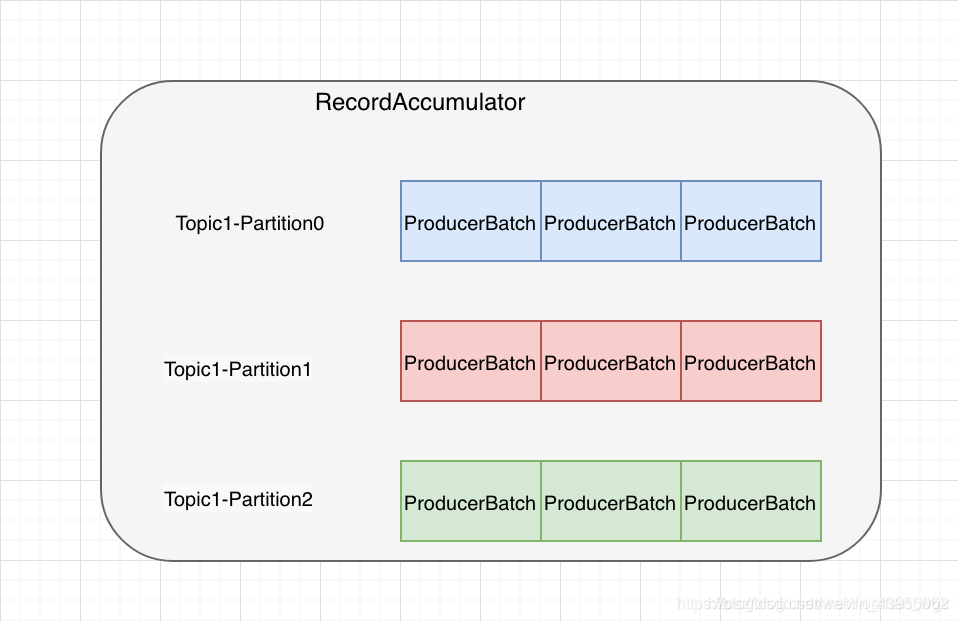
5、消息缓存
消息在发送之前会被缓存在RecordAccumulator中,队列中消息满了之后就唤醒Sender线程,将消息发送出去。
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey, serializedValue, headers, interceptCallback, remainingWaitMs);
首先根据分区创建一个队列,数据结构为:TopicPartition <—> Deque
队列Deque中保存多个ProducerBatch批记录,每个ProducerBatch中包含分区TopicPartition、用于存放数据MemoryRecordsBuilder等字段。
private Deque<ProducerBatch> getOrCreateDeque(TopicPartition tp) {
// 如果分区tp对应的队列已存在,直接返回
Deque<ProducerBatch> d = this.batches.get(tp);
if (d != null)
return d;
d = new ArrayDeque<>();
// 先尝试着往batches中put(putIfAbsent:key存在, 返回key对应value, key不存在,返回null)
// 如果存在,就返回已创建的队列;不存在就返回新建的d
Deque<ProducerBatch> previous = this.batches.putIfAbsent(tp, d);
if (previous == null)
return d;
else
return previous;
}
紧接着就往新分区对应的队列中append数据:
// 由于多线程操作需要先检查是否已有创建的分区对应的队列
Deque<ProducerBatch> dq = getOrCreateDeque(tp);
synchronized (dq) {
if (closed)
throw new IllegalStateException("Cannot send after the producer is closed.");
// 先尝试着往队列中append数据
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq);
if (appendResult != null)
return appendResult;
}
获取队列中最后一个ProducerBatch,往里面append数据:
private RecordAppendResult tryAppend(long timestamp, byte[] key, byte[] value, Header[] headers,
Callback callback, Deque<ProducerBatch> deque) {
// 获取队列中最后一个批记录,往该batch中添加数据
ProducerBatch last = deque.peekLast();
// 往最后一个ProducerBatch中append数据
if (last != null) {
FutureRecordMetadata future = last.tryAppend(timestamp, key, value, headers, callback, time.milliseconds());
if (future == null)
last.closeForRecordAppends();
else
return new RecordAppendResult(future, deque.size() > 1 || last.isFull(), false);
}
return null;
}
ProducerBatch.tryAppend()是最核心的方法,功能是将消息添加到当前RecordBatch中缓存:
public FutureRecordMetadata tryAppend(long timestamp, byte[] key, byte[] value, Header[] headers, Callback callback, long now) {
// 空间不足,直接返回
if (!recordsBuilder.hasRoomFor(timestamp, key, value, headers)) {
return null;
} else {
//向MemoryRecords中添加数据
Long checksum = this.recordsBuilder.append(timestamp, key, value, headers);
this.maxRecordSize = Math.max(this.maxRecordSize, AbstractRecords.estimateSizeInBytesUpperBound(magic(),recordsBuilder.compressionType(), key, value, headers));
this.lastAppendTime = now;
FutureRecordMetadata future = new FutureRecordMetadata(this.produceFuture, this.recordCount,timestamp, checksum,key == null ? -1 : key.length, value == null ? -1 : value.length);
// we have to keep every future returned to the users in case the batch needs to be
// split to several new batches and resent.
//将用户自定义Callback和FutureRecordMetadata封装成Thunk,保存到thunks集合中
thunks.add(new Thunk(callback, future));
this.recordCount++;
return future;
}
}
如果由于内存不够导致append数据失败后,会加锁进行重试:
// 执行到此步可能表示队列中ProducerBatch的内存不够或者为空, 创建一个并append数据
byte maxUsableMagic = apiVersions.maxUsableProduceMagic();
int size = Math.max(this.batchSize, AbstractRecords.estimateSizeInBytesUpperBound(maxUsableMagic, compression, key, value, headers));
log.trace("Allocating a new {} byte message buffer for topic {} partition {}", size, tp.topic(), tp.partition());
buffer = free.allocate(size, maxTimeToBlock);
// 再次加锁,提高吞吐量,防止一个线程由于分配buffer占用锁时间过长
synchronized (dq) {
// Need to check if producer is closed again after grabbing the dequeue lock.
if (closed)
throw new IllegalStateException("Cannot send after the producer is closed.");
// 加锁, 再次tryAppend
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq);
if (appendResult != null) {
// 添加成功, 直接返回
return appendResult;
}
// 新创建ProducerBatch, 并将其添加到Batches集合dq中
MemoryRecordsBuilder recordsBuilder = recordsBuilder(buffer, maxUsableMagic);
ProducerBatch batch = new ProducerBatch(tp, recordsBuilder, time.milliseconds());
FutureRecordMetadata future = Utils.notNull(batch.tryAppend(timestamp, key, value, headers, callback, time.milliseconds()));
dq.addLast(batch);
incomplete.add(batch);
// Don't deallocate this buffer in the finally block as it's being used in the record batch
buffer = null;
return new RecordAppendResult(future, dq.size() > 1 || batch.isFull(), true);
append完数据之后,满足一定条件后唤醒Sender线程进行发送:
// RecordAccumulator队列消息已满或者新创建了batch
if (result.batchIsFull || result.newBatchCreated) {
// ...
// 唤醒sender线程,执行run中逻辑读取队列中内容将消息发送至broker集群
this.sender.wakeup();
}
6、消息发送
唤醒Sender线程之后,会进行消息发送的流程。消息发送的过程分为以下几个步骤:
- 获取所要发送数据对应的Leader节点和未知节点的分区;
- 对于节点未知的分区,调用metadata.requestUpdate()强制更新;
- 将所有批次数据按将要发送到节点进行归类,即:Node Id < --> List
- 按Node进行网络连接,发送网络请求
(1)获取已经准备好的Broker节点
唤醒Sender线程之后,就会执行run()中的逻辑,首先是根据分批数据获取到所有将要发送的节点信息。
// 获取元数据中保存的集群信息
Cluster cluster = metadata.fetch();
// get the list of partitions with data ready to send
// 获取所有准备发往到分区的消息集合
RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now);
// 获取Leader节点存在的node,对于Leader节点未知的分区先标记起来,后续再去请求其信息
public ReadyCheckResult ready(Cluster cluster, long nowMs) {
// 存放将要发送的数据Node
Set<Node> readyNodes = new HashSet<>();
long nextReadyCheckDelayMs = Long.MAX_VALUE;
// 如果某些分区对应的leader未知,数据会先存放到这里,kafka会强制更新元数据获取这些分区对应的leader信息
Set<String> unknownLeaderTopics = new HashSet<>();
boolean exhausted = this.free.queued() > 0;
for (Map.Entry<TopicPartition, Deque<ProducerBatch>> entry : this.batches.entrySet()) {
TopicPartition part = entry.getKey();
Deque<ProducerBatch> deque = entry.getValue();
// 获取将要发送的数据对应的Leader Replica
Node leader = cluster.leaderFor(part);
synchronized (deque) {
if (leader == null && !deque.isEmpty()) {
// 标记对应的Leader Replica不存在的分区
unknownLeaderTopics.add(part.topic());
} else if (!readyNodes.contains(leader) && !muted.contains(part)) {
ProducerBatch batch = deque.peekFirst();
if (batch != null) {
long waitedTimeMs = batch.waitedTimeMs(nowMs);
boolean backingOff = batch.attempts() > 0 && waitedTimeMs < retryBackoffMs;
long timeToWaitMs = backingOff ? retryBackoffMs : lingerMs;
boolean full = deque.size() > 1 || batch.isFull();
boolean expired = waitedTimeMs >= timeToWaitMs;
boolean sendable = full || expired || exhausted || closed || flushInProgress();
if (sendable && !backingOff) {
readyNodes.add(leader);
} else {
long timeLeftMs = Math.max(timeToWaitMs - waitedTimeMs, 0);
nextReadyCheckDelayMs = Math.min(timeLeftMs, nextReadyCheckDelayMs);
}
}
}
}
}
return new ReadyCheckResult(readyNodes, nextReadyCheckDelayMs, unknownLeaderTopics);
}
(2)对于Leader节点未知的分区,强制更新元数据:
// 如果有分区的leader未知,强制更新元数据metadata
if (!result.unknownLeaderTopics.isEmpty()) {
for (String topic : result.unknownLeaderTopics)
this.metadata.add(topic);
this.metadata.requestUpdate();
}
(3)所有将要发送的批次数据,通过drain()方法按照要发往的node节点进行归类,形成NodeId <==> List的数据结构:
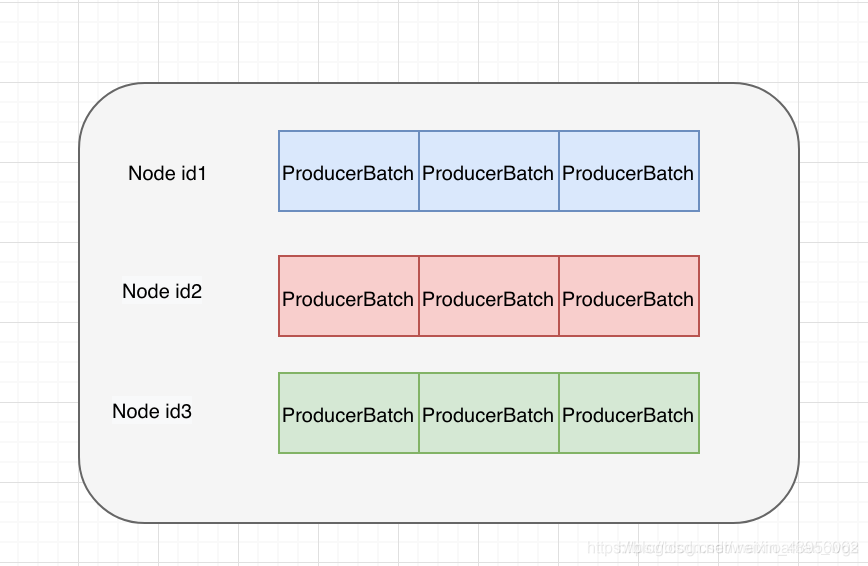
// 将所有批次数据, 按将要发往的分区所在的leader node.id 进行归类
Map<Integer, List<ProducerBatch>> batches = this.accumulator.drain(cluster, result.readyNodes,this.maxRequestSize, now);
public Map<Integer, List<ProducerBatch>> drain(Cluster cluster,
Set<Node> nodes,
int maxSize,
long now) {
if (nodes.isEmpty())
return Collections.emptyMap();
// key: leader broker.id; value: List<ProducerBatch>
Map<Integer, List<ProducerBatch>> batches = new HashMap<>();
for (Node node : nodes) {
int size = 0;
// (1)获取每个broker id上的分区: List<PartitionInfo>
List<PartitionInfo> parts = cluster.partitionsForNode(node.id());
List<ProducerBatch> ready = new ArrayList<>();
/* to make starvation less likely this loop doesn't start at 0 */
int start = drainIndex = drainIndex % parts.size();
do {
// (2)遍历所有分区, 获取分区上对应的批次数据ProducerBatch
PartitionInfo part = parts.get(drainIndex);
TopicPartition tp = new TopicPartition(part.topic(), part.partition());
// Only proceed if the partition has no in-flight batches.
if (!muted.contains(tp)) {
Deque<ProducerBatch> deque = getDeque(tp);
if (deque != null) {
synchronized (deque) {
ProducerBatch first = deque.peekFirst();
if (first != null) {
boolean backoff = first.attempts() > 0 && first.waitedTimeMs(now) < retryBackoffMs;
// Only drain the batch if it is not during backoff period.
if (!backoff) {
if (size + first.estimatedSizeInBytes() > maxSize && !ready.isEmpty()) {
// ...
break;
} else {
// ... 省略部分内容
batch.close();
size += batch.records().sizeInBytes();
ready.add(batch);
batch.drained(now);
}
}
}
}
}
}
this.drainIndex = (this.drainIndex + 1) % parts.size();
} while (start != drainIndex);
// (3)安装节点、批次数据进行归类: NodeId <==> List<ProducerBatch>
batches.put(node.id(), ready);
}
return batches;
}
(4)分别与Node节点建立网络连接,将数据发送出去。
sendProduceRequests(batches, now);
private void sendProduceRequests(Map<Integer, List<ProducerBatch>> collated, long now) {
for (Map.Entry<Integer, List<ProducerBatch>> entry : collated.entrySet())
sendProduceRequest(now, entry.getKey(), acks, requestTimeout, entry.getValue());
}
private void sendProduceRequest(long now, int destination, short acks, int timeout, List<ProducerBatch> batches) {
if (batches.isEmpty())
return;
Map<TopicPartition, MemoryRecords> produceRecordsByPartition = new HashMap<>(batches.size());
final Map<TopicPartition, ProducerBatch> recordsByPartition = new HashMap<>(batches.size());
for (ProducerBatch batch : batches) {
TopicPartition tp = batch.topicPartition;
MemoryRecords records = batch.records();
// ...
if (!records.hasMatchingMagic(minUsedMagic))
records = batch.records().downConvert(minUsedMagic, 0, time).records();
produceRecordsByPartition.put(tp, records);
recordsByPartition.put(tp, batch);
}
// ...
String nodeId = Integer.toString(destination);
ClientRequest clientRequest = client.newClientRequest(nodeId, requestBuilder, now, acks != 0, callback);
client.send(clientRequest, now);
log.trace("Sent produce request to {}: {}", nodeId, requestBuilder);
}
数据的发送由NetworkClient去完成发送,涉及到NIO网络模型等操作,后续会单独讲解,在此就不再讲解。
————————————————
版权声明:本文为CSDN博主「是Guava不是瓜娃」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/noaman_wgs/article/details/105646505