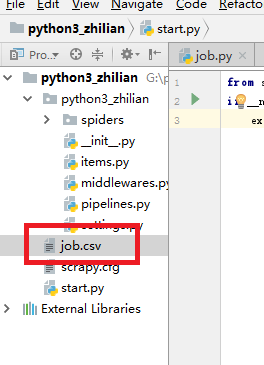
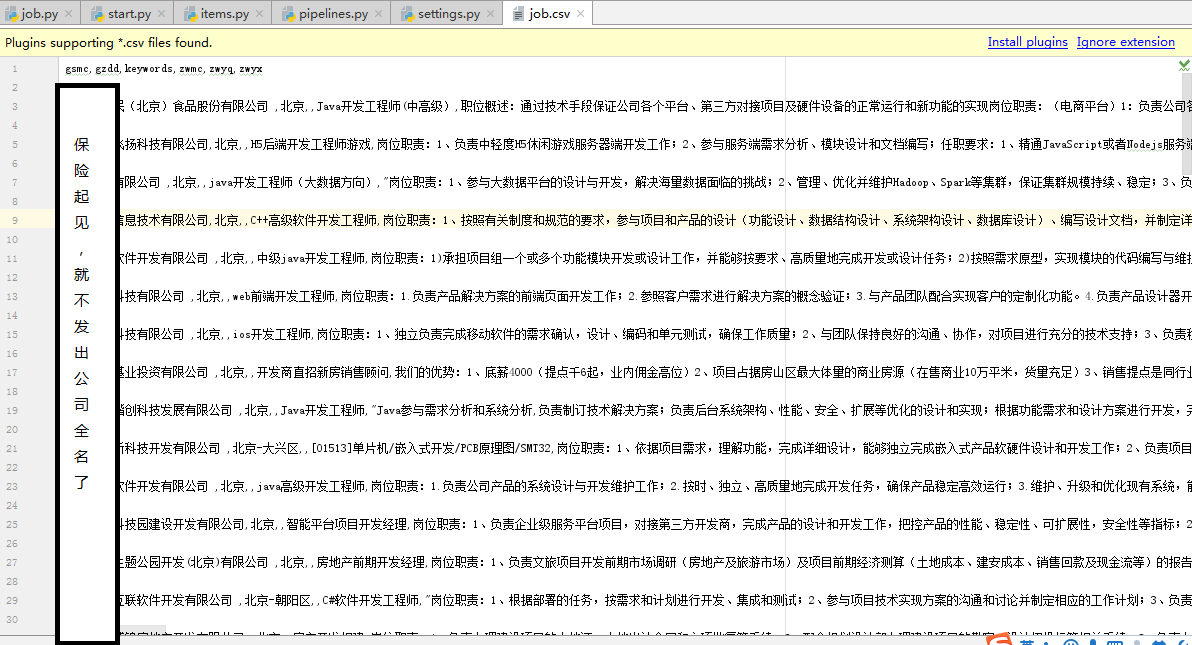
现在我们写一个爬取某招聘网站上北京开发岗位招聘信息的爬虫程序
爬取数据前,我们需要创建一个scarpy框架,我个人喜欢通过Anaconda Prompt创建,简单 便捷
Anaconda Prompt下载地址:https://www.anaconda.com/download/
下载界面有两个版本,选择本机python的版本下载安装就可以了。
步入正题,首先我们开始通过Anaconda Prompt创建一个爬虫
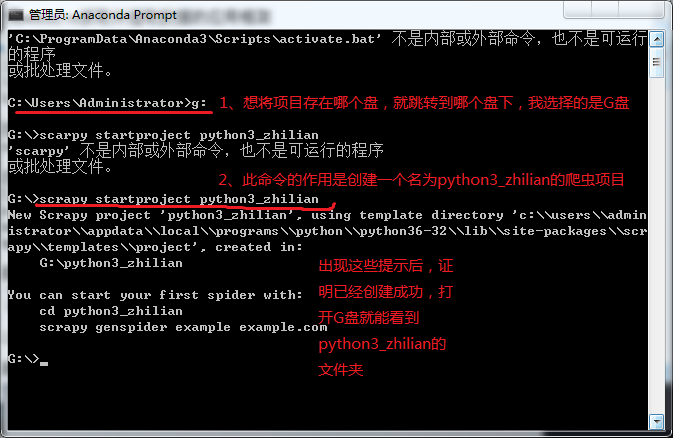
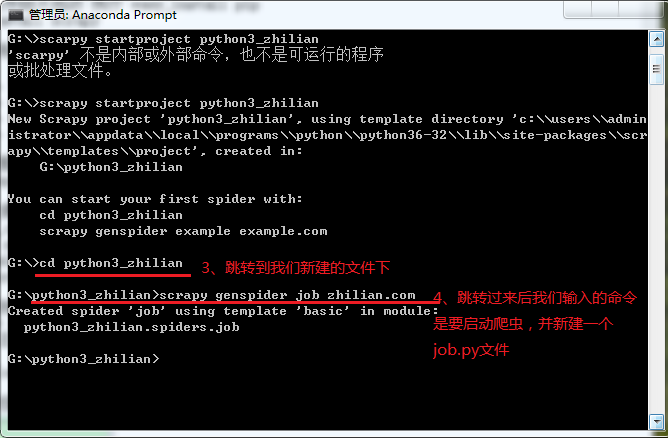
完成以上步骤后,我们就可以在pycharm里编写爬虫代码了
首先,用pycharm编辑器打开我们刚刚创建的python3_zhilian(步骤:打开pycharm--点击左上角File--点击open--找到python3_zhilian点击OK,这一步需要注意的是 直接打开python3_zhilian文件夹就可以)
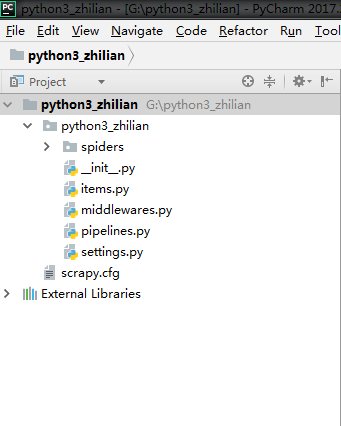
首先我们详细了解一下这里面每个目录的作用:
-
scrapy.cfg 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
-
items.py 设置数据存储模板,用于结构化数据,如:Django的Model
-
pipelines 数据处理行为,如:一般结构化的数据持久化
-
settings.py 配置文件,如:递归的层数、并发数,延迟下载等
-
spiders 爬虫目录,如:创建文件,编写爬虫规则
接下来我们主要做的就是对蜘蛛的修改
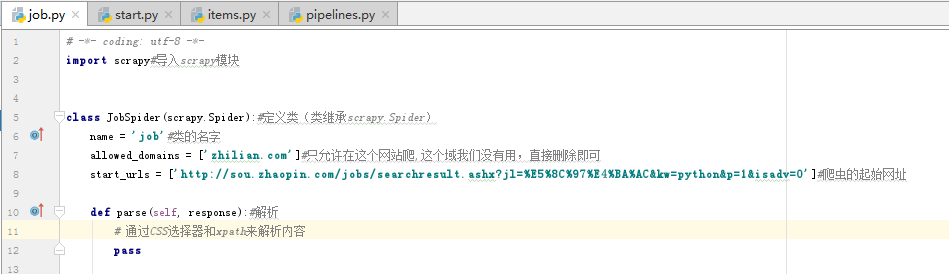
先打开spiders下的job.py进行修改,详细内容已经写在注释里,见下图代码
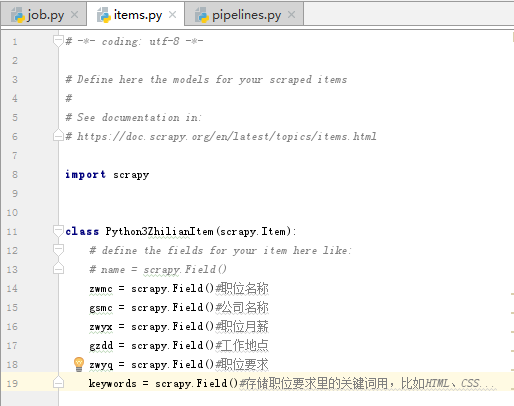
接下来我们开始写业务,业务封装的数据我们需要保存在一个实体里
在这里,我们只爬取职位名称、公司名称、职位月薪、工作地点和职位要求等5个字段
打开items.py,添加如下代码:
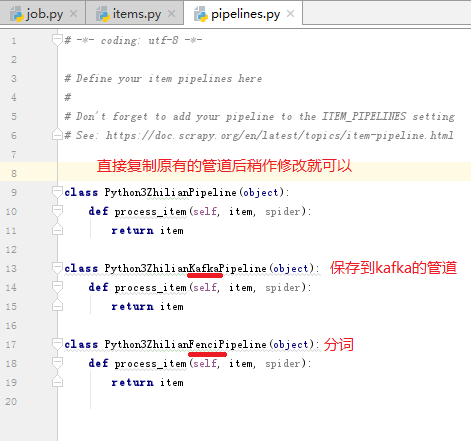
下面我们需要创建三个管道,将数据分别保存在关系型数据MySQL内,Kafka内,还有一条管道是做分词用
打开pipelines.py,实现如下代码
要启动这三个管道,还需要在settings.py下进行配置
至此,系统每个环节所需要的必须产物都已经有了,但是实现代码还没有写,所以下面我们开始实现,从蜘蛛开始,打开job.py并实现以下代码:(详细的步骤以注释形式随代码附上)
# -*- coding: utf-8 -*-
import scrapy#导入scrapy模块
class JobSpider(scrapy.Spider):#定义类(类继承scrapy.Spider)
name = 'job'#类的名字
# allowed_domains = ['zhilian.com']#只允许在这个网站爬,这个域我们没有用,直接删除即可
start_urls = ['http://sou.zhaopin.com/jobs/searchresult.ashx?jl=%E5%8C%97%E4%BA%AC&kw=%E5%BC%80%E5%8F%91&sm=0&p=1']#爬虫的起始网址
def parse(self, response):#解析
# 通过CSS选择器和xpath来解析内容
#1、找到招聘职位链接并跟踪
#2、找到‘下一页’的链接并跟踪
zwmcs = response.css('td.zwmc')#获得所有的职位
for zw in zwmcs:
href = zw.css(' a::attr("href")').extract_first()#获得所有职位的链接
yield response.follow(href, self.detail)#response.follow方法为了实现跟随爬取
next_href = response.css('li.pagesDown-pos>a::attr("href")').extract_first()#获得‘下一页’的链接
if next_href is not None:#判断如果next_href不为空,执行跟随爬取
yield response.follow(next_href, self.parse)
def detail(self, response):
zwmc = response.css('div.inner-left.fl>h1::text').extract_first()
print(zwmc)
注:代码内的.css()括号里的内容就是某招聘里HTML的class名称
接下来我们可以运行一下试试:
1、可以在Anaconda Prompt下输入scrapy crawl python3_zhilian启动爬虫
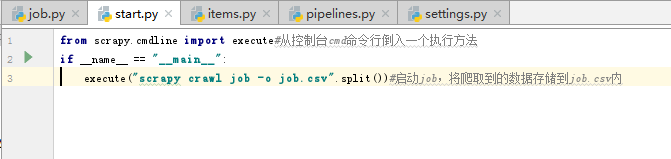
2、第二种方法,也是我比较喜欢的一种方法,在pycharm里python3_zhilian里新建一个.py文件,名字任意起,我创建的名称为start,代码如下(注:启动蜘蛛只需点击启动start)
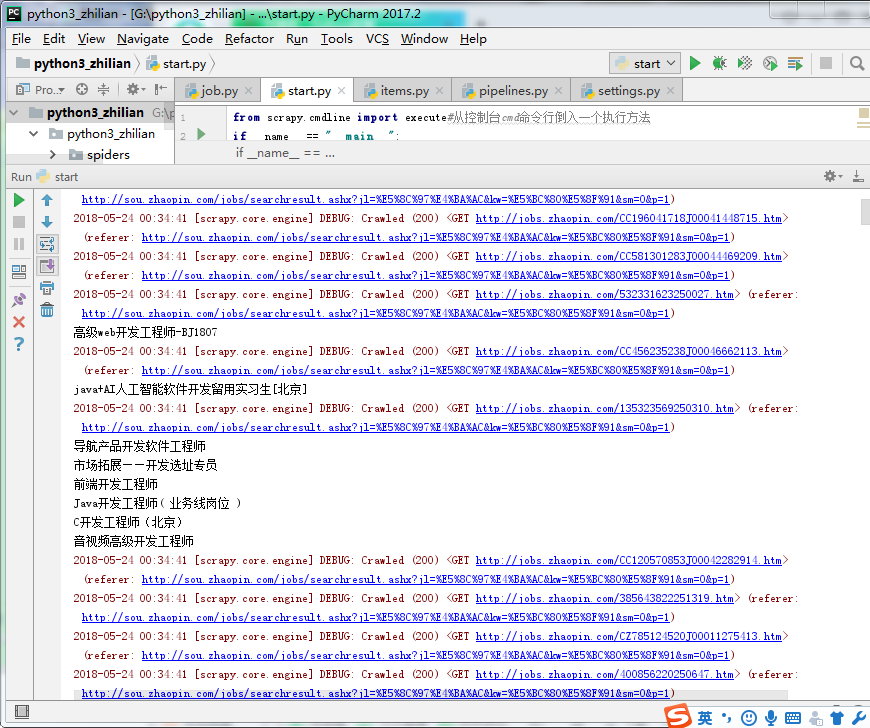
运行后我们可以看到已经成功爬取到数据了
接下来我们将其余的四个字段全部补充完整,还是在job.py中编写代码,代码如下(详细的步骤以注释形式随代码附上)
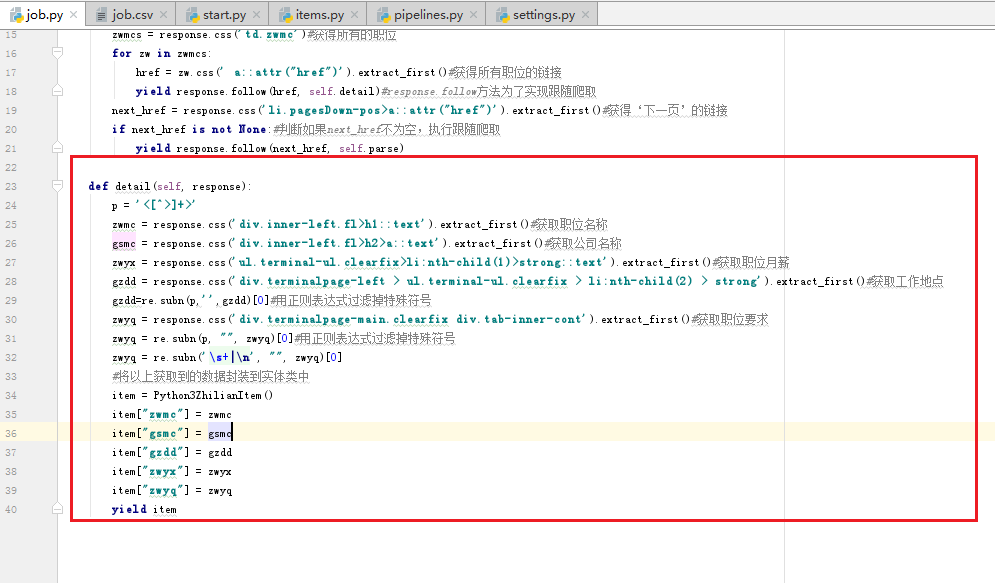
补充完毕后,再次启动start,我们就可以爬取到某网站招聘信息上的职位名称、公司名称、职位月薪、工作地点和职位要求
由于我们在start.py下写了一个-o job.csv,所以当程序运行结束后,python3_zhilian目录下会自动生成job.csv文件,并将爬取到的数据存储到job.csv内