#include <iostream>
#include <omp.h>
#include <sys/time.h>
#include <fstream>
using namespace std;
void bubble(int*, int);
void odd_even1(int*, int);
void odd_even2(int*, int);
void show(int*, int);
void init(int*, int);
int main() {
for (int n=100; n < 10000; n+=100)
{
int* arr = (int*)malloc(sizeof(int)*n);
struct timeval start1, end1, start2, end2;
init(arr, n);
gettimeofday(&start1, nullptr);
odd_even1(arr, n);
gettimeofday(&end1, nullptr);
init(arr, n);
gettimeofday(&start2, nullptr);
odd_even2(arr, n);
gettimeofday(&end2, nullptr);
double odd_even1 =(1000000*(end1.tv_sec-start1.tv_sec) \
+end1.tv_usec-start1.tv_usec)/1000;
double odd_even2 = (1000000*(end2.tv_sec-start2.tv_sec) \
+end2.tv_usec-start2.tv_usec)/1000;
free(arr);
}
return 0;
}
void init(int*arr, int n) {
for (int i = 0; i < n; i++) {
arr[i] = n - i;
}
}
void show(int* arr, int n) {
for (int i = 0; i < n; i++) {
printf("%d ", arr[i]);
}
printf("\n");
}
void bubble(int* arr, int n) {
int temp;
for (int length = n; length >= 2; length-- ) {
for (int i = 0; i < length - 1; i++) {
if (arr[i] > arr[i+1]) {
temp = arr[i];
arr[i] = arr[i+1];
arr[i+1] = temp;
}
}
}
}
void odd_even1(int* arr, int n) {
int temp;
for (int parse = 0; parse < n; parse++) {
if (parse % 2 == 0) {
# pragma omp parallel for num_threads(4) private(temp)
for (int i = 0; i < n-1; i += 2) {
if (arr[i] > arr[i+1]) {
temp = arr[i];
arr[i] = arr[i+1];
arr[i+1] = temp;
}
}
} else {
# pragma omp parallel for num_threads(4) private(temp)
for (int i = 1; i < n - 1; i += 2) {
if (arr[i] > arr[i + 1]) {
temp = arr[i];
arr[i] = arr[i+1];
arr[i+1] = temp;
}
}
}
}
}
void odd_even2(int* arr, int n) {
int temp;
int parse;
# pragma omp parallel num_threads(4) private(temp, parse)
for (parse = 0; parse < n; parse++) {
if (parse % 2 == 0) {
# pragma omp for
for (int i = 0; i < n-1; i += 2) {
if (arr[i] > arr[i+1]) {
temp = arr[i];
arr[i] = arr[i+1];
arr[i+1] = temp;
}
}
} else {
# pragma omp for
for (int i = 1; i < n - 1; i += 2) {
if (arr[i] > arr[i + 1]) {
temp = arr[i];
arr[i] = arr[i+1];
arr[i+1] = temp;
}
}
}
}
}
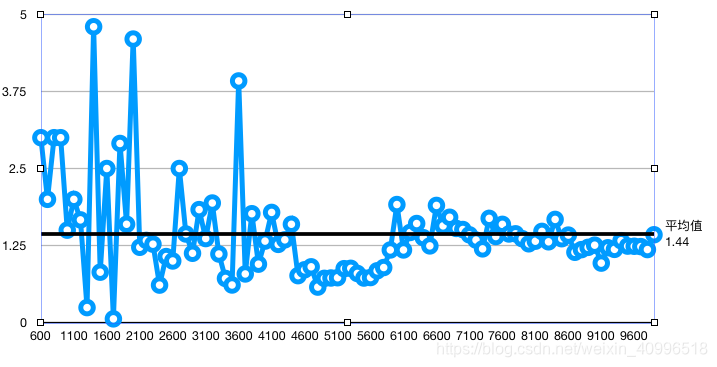
- 将#pragma omp parallel放在外层循环外, 避免每次外层循环都创建销毁线程, 增加额外开销
- 下图为 将#pragma omp parallel 放在外层循环内 耗费时间 与 放在外层循环内 耗费时间 的比值. 线程的额外开销大约可以节省20%-30%的时间