知识框架
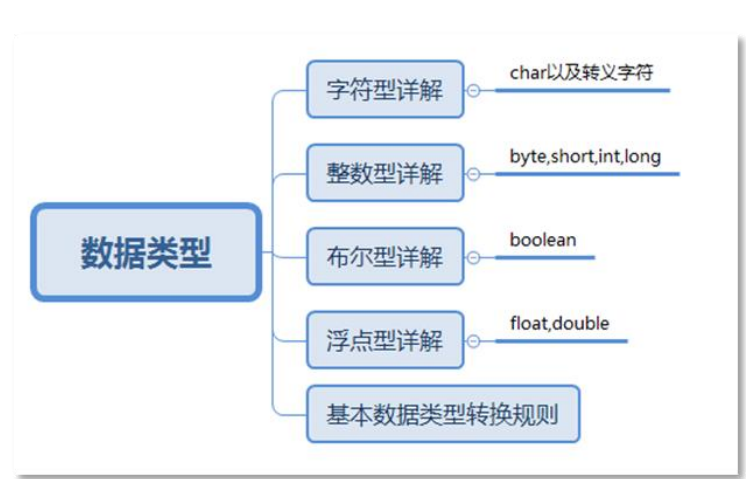
数据类型概述
Java的数据类型分为两大类:
- 基本数据类型:包括 整数 、 浮点数 、 字符 、 布尔 。
- 引用数据类型:包括 类 、 数组 、 接口 等等.
- 第 1 类:整数型(不带小数的数字):byte,short,int,long
- 第 2 类:浮点型(带小数的数字):float,double
- 第 3 类:字符型(文字,单个字符):char
- 第 4 类:布尔型(真和假):boolean
实际上计算机在任何情况下都只能识别二进制,什么是二进制呢?计算机毕竟是一台通电的机器,电流只有正极、负极,所以只能表示两种情况,也就是 1 和 0。对于一串由 1 和 0 组成的数字来说就是二进制,所谓的二进制就是满2 进 1。关于计算机存储单位?1字节 = 8bit(8比特)即1byte = 8bit 1bit就是一个1或0。不同的进制之间可以互相转换。在计算机当中,一个二进制位最左边的是符号位,当为0时表示正数,当为1时表示负数。

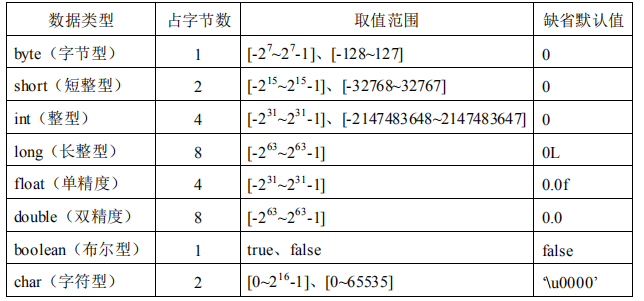
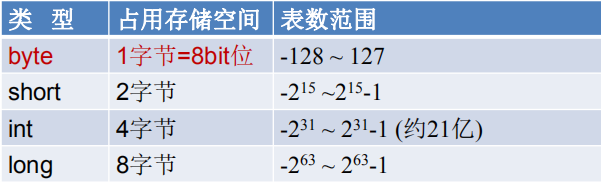
整数类型:byte、short、int、long
- 整型用于表示没有小数部分的数值,允许是负数
- Java各整数类型有固定的表数范围和字段长度,不受具体OS的影响,以保证java程序的可移植性。
- java的整型常量默认为 int 型,声明long型常量须后加‘l’或‘L’
- java程序中变量通常声明为int型,除非不足以表示较大的数,才使用long
- bit: 计算机中的最小存储单位。byte:计算机中基本存储单元。
所有数字在计算机底层都以二进制形式存在。
对于整数,有四种表示方式:
- 二进制(binary):0,1 ,满2进1.以0b或0B开头。
- 十进制(decimal):0-9 ,满10进1。
- 八进制(octal):0-7 ,满8进1. 以数字0开头表示。
- 十六进制(hex):0-9及A-F,满16进1. 以0x或0X开头表示。此处的A-F不区分大小写。 如:0x21AF +1= 0X21B0
/* 在java语言中整数型字面量有4种表示形式: 十进制:最常用的。 二进制 八进制 十六进制 */ public class IntTest01{ public static void main(String[] args){ // 十进制 int a = 10; System.out.println(a); // 10 // 八进制 int b = 010; System.out.println(b); // 8 // 十六进制 int c = 0x10; System.out.println(c); // 16 int x = 16; //十进制方式 System.out.println(x); // 二进制(JDK8的新特性,低版本不支持。) int d = 0b10; System.out.println(d); // 2 } }
浮点类型:float、double
- 与整数类型类似,Java 浮点类型也有固定的表数范围和字段长度,不受具体操作 系统的影响。
浮点型常量有两种表示形式:
- 十进制数形式:如:5.12 512.0f .512 (必须有小数点)
- 科学计数法形式:如:5.12e2 512E2 100E-2
- float:单精度,尾数可以精确到7位有效数字。很多情况下,精度很难满足需求。
- double:双精度,精度是float的两倍。通常采用此类型。
Java 的浮点型常量默认为double型,声明float型常量,须后加‘f’或‘F’。

字符类型:char
- char 型数据用来表示通常意义上“字符”(2字节)。在Java程序中,强烈建议不要使用char类型。因为char类型描述了utf-16编码中的一个代码单元。short和char实际上容量相同,不过char可以表示更大的数字。因为char表示的是文字,文件没有正负之分,所以char可以表示更大的数字。
Java中的所有字符都使用Unicode编码,故一个字符可以存储一个字母,一个汉字,或其他书面语的一个字符。单引号中间不能为空。
/* 字符型: char 1、char占用2个字节。 2、char的取值范围:[0-65535] 3、char采用unicode编码方式。 4、char类型的字面量使用单引号括起来。 5、char可以存储一个汉字。 */ public class CharTest01{ public static void main(String[] args){ // char可以存储1个汉字吗? // 可以的,汉字占用2个字节,java中的char类型占用2个字节,正好。 char c1 = '中'; System.out.println(c1); char c2 = 'a'; System.out.println(c2); // 0如果加上单引号的话,0就不是数字0了,就是文字0,它是1个字符。 char c3 = '0'; System.out.println(c3); // 错误: 不兼容的类型: String无法转换为char //char c4 = "a"; // 错误: 未结束的字符文字 //char c5 = 'ab'; // 错误: 未结束的字符文字 //char c6 = '1.08'; } }
字符型变量的三种表现形式:
- 字符常量是用单引号(‘ ’)括起来的单个字符。例如:char c1 = 'a'; char c2 = '中'; char c3 = '9';
- Java中还允许使用转义字符‘\’来将其后的字符转变为特殊字符型常量。 例如:char c3 = ‘\n’; // '\n'表示换行符
- 直接使用 Unicode 值来表示字符型常量:‘\uXXXX’。其中,XXXX代表 一个十六进制整数。如:\u000a 表示 \n。char类型是可以进行运算的。因为它都对应有Unicode码。
/* 关于java中的转义字符 java语言中“\”负责转义。 \t 表示制表符tab */ public class Demo02Char { public static void main(String[] args) { // 普通的't'字符 char c1 = 't'; // 经过测试以下代码 \t 实际上是1个字符,不属于字符串 // 两个字符合在一起表示一个字符,其中 \t 表示“制表符tab” char c2 = '\t'; //相当于键盘上的tab键 // \的出现会将紧挨着的后面的字符进行转义。\碰到t表示tab键。 System.out.println("abc\tdef"); System.out.print("abc"); //char c3 = 'n'; // 普通的n字符 char c3 = '\n'; // 换行符 // 假设现在想在控制台输出一个 ' 字符怎么办? // System.out.println('''); 错误: 空字符文字 // \' 表示一个普通不能再普通的单引号字符。(\'联合起来表示一个普通的 ') System.out.println('\''); // 假设现在想在控制台输出一个 \ 字符怎么办? // System.out.println('\'); 错误: 未结束的字符文字 // 在java中两个反斜杠代表了一个“普通的反斜杠字符” System.out.println('\\'); // 希望输出的结果是:"test" // System.out.println(""test""); 错误: 需要')' System.out.println("“test”"); //内部的双引号我用中文的行吗?可以。 System.out.println(""); // System.out.println(""");编译报错。 System.out.println("\"test\""); // 这个可以输出吗? // 这个不需要专门进行转义。 // 这个 ' 在这里只是一个普通的字符,不具备特殊含义。 System.out.println("'"); //以下都有问题 //System.out.println('''); //System.out.println("""); // 可以的。 System.out.println("'这样呢'"); // 编译报错,因为:4e2d 是一个字符串 // char x = '4e2d'错误: 未结束的字符文字 // 反斜杠u表示后面的是一个字符的unicode编码。 // unicode编码是十六进制的。 char x = '\u4e2d'; System.out.println(x); // '中' } }
布尔类型:boolean
- boolean类型数据只允许取值true和false,无null。不可以使用0或非 0 的整数替代false和true,这点和C语言不同。Java虚拟机中没有任何供boolean值专用的字节码指令,Java语言表达所操作的 boolean值,在编译之后都使用java虚拟机中的int数据类型来代替:true用1表示,false 用0表示。
boolean 类型用来判断逻辑条件,一般用于程序流程控制:
- if条件控制语句;
- while循环控制语句;
- do-while循环控制语句;
- for循环控制语句;
字符编码
对于以上的八种基本数据类型来说,其中七种类型 byte,short,int,long,float,double,boolean计算机表示起来是很容易的,因为这七种类型底层直接就是数字,十进制的数字和二进制之间有固定的转换规则,所以计算机可直接表示和处理。但是大家别忘了,除了以上的七种数据类型之外,还有一种类型叫做字符型 char,这个对于计算机来说表示起来就不是那么容易了,因为字符毕竟是现实世界当中的文字,而文字每个国家又是不同的,计算机是如何表示文字的呢?实际上,起初的时候计算机只支持数字,因为计算机最初就是为了科学计算,随着计算机的发展,为了让计算机起到更大的作用,因此我们需要让计算机支持现实世界当中的文字,一些标准制定的协会就制定了字符编码(字符集),字符编码其实就是一张对照表,在这个对照表上描述了某个文字与二进制之间的对应关系。
什么是字符编码?
- 字符编码是人为的定义的一套转换表。
- 在字符编码中规定了一系列的文字对应的二进制。
- 字符编码其实本质上就是一本字典,该字段中描述了文字与二进制之间的对照关系。
- 字符编码是人为规定的。(是某个计算机协会规定的。)
计算机中储存的信息都是用二进制数表示的,而我们在屏幕上看到的数字、英文、标点符号、汉字等字符是二进制 数转换之后的结果。按照某种规则,将字符存储到计算机中,称为编码 。反之,将存储在计算机中的二进制数按照 某种规则解析显示出来,称为解码 。比如说,按照A规则存储,同样按照A规则解析,那么就能显示正确的文本f符 号。反之,按照A规则存储,再按照B规则解析,就会导致乱码现象。字符编码 Character Encoding : 就是一套自然语言的字符与二进制数之间的对应规则。编码和解码,它们都是什么,我们拿字符'a'来解释一下:'a'是 97,97 对应的二进制是 01100001,那么从'a'到二进制 01100001的转换过程称为编码,从二进制 01100001 到'a'的转换过程称为解码。大家一定要注意:编码和解码要采用同一种字符编码方式(要采用同一个对照表),不然会出现乱码。这也是乱码出现的本质原因。
字符集
字符集 Charset :也叫编码表。是一个系统支持的所有字符的集合,包括各国家文字、标点符号、图形符 号、数字等。 计算机要准确的存储和识别各种字符集符号,需要进行字符编码,一套字符集必然至少有一套字符编码。常见字符集有ASCII字符集、GBK字符集、Unicode字符集等。

![]()
可见,当指定了编码,它所对应的字符集自然就指定了,所以编码才是我们最终要关心的。
ASCII字符集 :
- ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁 字母的一套电脑编码系统,用于显示现代英语,主要包括控制字符(回车键、退格、换行键等)和可显 示字符(英文大小写字符、阿拉伯数字和西文符号)。
- 基本的ASCII字符集,使用7位(bits)表示一个字符,共128字符。ASCII的扩展字符集使用8位(bits) 表示一个字符,共256字符,方便支持欧洲常用字符。常见的 ASCII 码需要大家能够记住几个,在 ASCII 码中规定'a'对应 97,'b'对应 98,以此类推,'A'对应 65,'B'对应 66,以此类推,'0'字符对应 48,'1'字符对应 49,以此类推,这些常见的编码还是需要大家记住的。其他字符编码都向上兼容 ASCII 码。
ISO-8859-1字符集:
- 拉丁码表,别名Latin-1,用于显示欧洲使用的语言,包括荷兰、丹麦、德语、意大利语、西班牙语等。
- ISO-5559-1使用单字节编码,兼容ASCII编码。
GBxxx字符集:
- GB就是国标的意思,是为了显示中文而设计的一套字符集。
- GB2312:简体中文码表。一个小于127的字符的意义与原来相同。但两个大于127的字符连在一起时, 就表示一个汉字,这样大约可以组合了包含7000多个简体汉字,此外数学符号、罗马希腊的字母、日文 的假名们都编进去了,连在ASCII里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这 就是常说的"全角"字符,而原来在127号以下的那些就叫"半角"字符了。
- GBK:最常用的中文码表。是在GB2312标准基础上的扩展规范,使用了双字节编码方案,共收录了 21003个汉字,完全兼容GB2312标准,同时支持繁体汉字以及日韩汉字等。
- GB18030:最新的中文码表。收录汉字70244个,采用多字节编码,每个字可以由1个、2个或4个字节组成。支持中国国内少数民族的文字,同时支持繁体汉字以及日韩汉字等。
Unicode字符集 :
- Unicode编码系统为表达任意语言的任意字符而设计,是业界的一种标准,也称为统一码、标准万国 码。
- 它最多使用4个字节的数字来表达每个字母、符号,或者文字。有三种编码方案,UTF-8、UTF-16和UTF- 32。最为常用的UTF-8编码。
UTF-8编码,可以用来表示Unicode标准中任何字符,它是电子邮件、网页及其他存储或传送文字的应用 中,优先采用的编码。互联网工程工作小组(IETF)要求所有互联网协议都必须支持UTF-8编码。所以, 我们开发Web应用,也要使用UTF-8编码。它使用一至四个字节为每个字符编码,编码规则:
- 128个US-ASCII字符,只需一个字节编码。
- 拉丁文等字符,需要二个字节编码。
- 大部分常用字(含中文),使用三个字节编码。
- 其他极少使用的Unicode辅助字符,使用四字节编码。
基本数据类型转换
- 八种基本数据类型中,除 boolean 类型不能转换,剩下七种类型之间都可以进行转换;
- 如果整数型字面量没有超出 byte,short,char 的取值范围,可以直接将其赋值给byte,short,char 类型的变量;
- 小容量向大容量转换称为自动类型转换,容量从小到大的排序为:byte < short(char) <int < long < float < double,其中 short 和 char 都占用两个字节,但是 char 可以表示更大的正整数;
- 大容量转换成小容量,称为强制类型转换,编写时必须添加“强制类型转换符”,但运行时可能出现精度损失,谨慎使用;
- byte,short,char 类型混合运算时,先各自转换成 int 类型再做运算;
- 多种数据类型混合运算,各自先转换成容量最大的那一种再做运算;
自动类型转换:容量小的类型自动转换为容量大的数据类型就是自动类型转换
数据类型按容量大小排序为:

代码演示,自动类型转换
/* 在java中有一条非常重要的结论,必须记住: 在任何情况下,整数型的“字面量/数据”默认被当做int类型处理。(记住就行) 如果希望该“整数型字面量”被当做long类型来处理,需要在“字面量”后面添加L/l 建议使用大写L,因为小写l和1傻傻分不清。 */ public class Demo03Int { public static void main(String[] args) { // 分析这个代码存在类型转换吗,以下代码什么意思? // 不存在类型转换 // 100 这个字面量被当做int类型处理 // a变量是int类型,所以不存在类型的转换。 // int类型的字面量赋值给int类型的变量。 int a = 100; System.out.println(a); // 分析这个程序是否存在类型转换? // 分析:200这个字面量默认被当做int类型来处理 // b变量是long类型,int类型占4个字节,long类型占8个字节 // 小容量可以自动转换成大容量,这种操作被称为:自动类型转换。 long b = 200; System.out.println(b); // 分析这个是否存在类型转换? // 这个不存在类型转换。 // 在整数型字面量300后面添加一个L之后,300L联合起来就是一个long类型的字面量 // c变量是long类型,long类型赋值给long类型不存在类型转换。 long c = 300L; System.out.println(c); // 题目: // 可以吗?存在类型转换吗? // 2147483647默认被当做int来处理 // d变量是long类型,小容量可以自动赋值给大容量,自动类型转换 long d = 2147483647; // 2147483647是int最大值。 System.out.println(d); // 编译器会报错吗?为什么? // 在java中,整数型字面量一上来编译器就会将它看做int类型 // 而2147483648已经超出了int的范围,所以在没有赋值之前就出错了。 // 记住,不是e放不下2147483648,e是long类型,完全可以容纳2147483648 // 只不过2147483648本身已经超出了int范围。 // 错误: 整数太大 //long e = 2147483648; // 怎么解决这个问题呢? long e = 2147483648L; System.out.println(e); byte f = 1; short g = 2; char h = '3'; //byte + short +char --->int + int + int -->int int result = f + g + h; System.out.println(result);//54 } }
强制类型转换:自动类型转换的逆过程,将容量大的数据类型转换为容量小的数据类型就是强制类型转换。
- 特点:代码需要进行特殊的格式处理,不能自动完成。
- 格式:范围小的类型 范围小的变量名 = (范围小的类型) 原本范围大的数据;
代码演示,强制类型转换
/* 1、小容量可以直接赋值给大容量,称为自动类型转换。 2、大容量不能直接赋值给小容量,需要使用强制类型转换符进行强转。 但需要注意的是:加强制类型转换符之后,虽然编译通过了,但是运行 的时候可能会损失精度。 */ public class Demo04Int { public static void main(String[] args) { long x = 100L; // x是long类型,占用8个字节,而y变量是int类型,占用4个字节 // 在java语言中,大容量可以“直接”赋值给小容量吗?不允许,没有这种语法。 // 编译错误信息:错误: 不兼容的类型: 从long转换到int可能会有损失 //int y = x; // 大容量转换成小容量,要想编译通过,必须加强制类型转换符,进行强制类型转换。 // 底层是怎么进行强制类型转换的呢? // long类型100L:00000000 00000000 00000000 00000000 00000000 00000000 00000000 01100100 // 以上的long类型100L强转为int类型,会自动将“前面”的4个字节砍掉:00000000 00000000 00000000 01100100 // 格式:范围小的类型 范围小的变量名 = (范围小的类型) 原本范围大的数据; int y = (int) x; // 这个(int)就是强制类型转换符,加上去就能编译通过。 // 但是要记住:编译虽然过了,但是运行时可能损失精度。 System.out.println(y); // 100 // long强制转换成为int类型,数据溢出 int num2 = (int) 6000000000L; System.out.println(num2); // 1705032704 // double --> int,强制类型转换,精度损失 int num3 = (int) 3.99; System.out.println(num3); // 3,这并不是四舍五入,所有的小数位都会被舍弃掉 // 定义变量a int类型,赋值100 int a = 100; int b = a; // 将变量a中保存的值100复制一份给b变量。 System.out.println(b); } }
编译器的2个优化
优化1
对于byte/short/char三种类型来说,如果右侧赋值的数值没有超过范围,那么javac编译器将会自动隐含地为我们补上一个(byte)(short)(char)。
- 如果没有超过左侧的范围,编译器补上强转。
- 如果右侧超过了左侧范围,那么直接编译器报错。
代码演示:
public class DemoNotice { public static void main(String[] args) { // 右侧确实是一个int数字,但是没有超过左侧的范围,就是正确的。 // int --> byte,不是自动类型转换 byte num1 = /*(byte)*/ 30; // 右侧没有超过左侧的范围 System.out.println(num1); // 30 // byte num2 = 128; // 右侧超过了左侧的范围 // int --> char,没有超过范围 // 编译器将会自动补上一个隐含的(char) char zifu = /*(char)*/ 65; System.out.println(zifu); // A } }
优化2:
在给变量进行赋值的时候,如果右侧的表达式当中全都是常量,没有任何变量,那么编译器javac将会直接将若干个常量表达式计算得到结果。short result = 5 + 8; // 等号右边全都是常量,没有任何变量参与运算编译之后,得到的.class字节码文件当中相当于【直接就是】:short result = 13;右侧的常量结果数值,没有超过左侧范围,所以正确。这称为“编译器的常量优化”。但是注意:一旦表达式当中有变量参与,那么就不能进行这种优化了。
代码演示
public class DemoNotice { public static void main(String[] args) { short num1 = 10; // 正确写法,右侧没有超过左侧的范围, short a = 5; short b = 8; // short + short --> int + int --> int // short result = a + b; // 错误写法!左侧需要是int类型 // 右侧不用变量,而是采用常量,而且只有两个常量,没有别人 short result = 5 + 8; System.out.println(result); short result2 = 5 + a + 8; // 18 } }
原码、反码、补码
二进制
- Java整数常量默认是int类型,当用二进制定义整数时,其第32位是符号位; 当是long类型时,二进制默认占64位,第64位是符号位
二进制的整数有如下三种形式:
- 原码:直接将一个数值换成二进制数。最高位是符号位
- 负数的反码:是对原码按位取反,只是最高位(符号位)确定为1。
- 负数的补码:其反码加1。
计算机以二进制补码的形式保存所有的整数。
- 正数的原码、反码、补码都相同
- 负数的补码是其反码+1
为什么要使用原码、反码、补码表示形式呢?
- 计算机辨别“符号位”显然会让计算机的基础电路设计变得十分复杂! 于是 人们想出了将符号位也参与运算的方法. 我们知道, 根据运算法则减去一个正 数等于加上一个负数, 即: 1-1 = 1 + (-1) = 0 , 所以机器可以只有加法而没有 减法, 这样计算机运算的设计就更简单了。
/* 1、计算机在任何情况下都只能识别二进制 2、计算机在底层存储数据的时候,一律存储的是“二进制的补码形式” 计算机采用补码形式存储数据的原因是:补码形式效率最高。 3、什么是补码呢? 实际上是这样的,二进制有:原码 反码 补码 4、记住: 对于一个正数来说:二进制原码、反码、补码是同一个,完全相同。 int i = 1; 对应的二进制原码:00000000 00000000 00000000 00000001 对应的二进制反码:00000000 00000000 00000000 00000001 对应的二进制补码:00000000 00000000 00000000 00000001 对于一个负数来说:二进制原码、反码、补码是什么关系呢? byte i = -1; 对应的二进制原码:10000001 对应的二进制反码(符号位不变,其它位取反):11111110 对应的二进制补码(反码+1):11111111 5、分析 byte b = (byte)150; 这个b是多少? int类型的4个字节的150的二进制码是什么? 00000000 00000000 00000000 10010110 将以上的int类型强制类型转为1个字节的byte,最终在计算机中的二进制码是: 10010110 千万要注意:计算机永远存储的都是二进制补码形式。也就是说上面 10010110 这个是一个二进制补码形式,你可以采用逆推导的方式推算出 这个二进制补码对应的原码是啥!!!!!! 10010110 ---> 二进制补码形式 10010101 ---> 二进制反码形式 11101010 ---> 二进制原码形式 */ public class IntTest05{ public static void main(String[] args){ // 编译报错:因为150已经超出了byte取值范围,不能直接赋值,需要强转 //byte b = 150; byte b = (byte)150; // 这个结果会输出多少呢? System.out.println(b); // -106 } }