目录
一.什么是正则表达式?
正则表达式描述了一种字符串匹配的模式,可以用来
- 检查一个字符串是否含有某种子串
- 将匹配的子串替换
- 从某个串中取出符合某个条件的子串
- 检查一个字符串是否符合某种格式
1.为什么要使用正则表达式
在了解正则表达式之前,我们先看几个非常常见的问题:
- 如何判断字符串是否是有效的电话号码?例如:
010-1234567,123ABC456,13510001000等; - 如何判断字符串是否是有效的电子邮件地址?例如:
[email protected],test#example等; - 如何判断字符串是否是有效的时间?例如:
12:34,09:60,99:99等。
一种直观的想法是通过程序判断,这种方法需要为每种用例创建规则,然后用代码实现。下面是判断手机号的代码:
boolean isValidMobileNumber(String s) {
// 是否是11位?
if (s.length() != 11) {
return false;
}
// 每一位都是0~9:
for (int i=0; i<s.length(); i++) {
char c = s.charAt(i);
if (c < '0' || c > '9') {
return false;
}
}
return true;
}
上述代码仅仅做了非常粗略的判断,并未考虑首位数字不能为0等更详细的情况。
除了判断手机号,我们还需要判断电子邮件地址、电话、邮编等等:
boolean isValidMobileNumber(String s) { … }
boolean isValidEmail(String s) { … }
boolean isValidPhoneNumber(String s) { … }
boolean isValidZipCode(String s) { … }
…
为每一种判断逻辑编写代码实在是太繁琐了。有没有更简单的方法?
有!用正则表达式!
- 正则表达式可以用字符串来描述规则,并用来匹配字符串。 例
- 如,判断手机号,我们用正则表达式
\d{11}boolean isValidMobileNumber(String s) { return s.matches("\\d{11}"); }
2.使用正则表达式的好处
- 正则表达式是用
字符串描述的一个匹配规则,使用正则表达式可以快速判断给定的字符串是否符合匹配规则。 - 正则表达式是一套
标准,它可以用于任何语言。Java标准库的java.util.regex包内置了正则表达式引擎,在Java程序中使用正则表达式非常简单。
二.正则表达式规则
正则表达式的匹配规则是从左到右按规则匹配
1. 字面量字符和原字符
- 大部分字符在正则表达式中就是字面上的意思,如:/a/匹配a, /abc/匹配abc,
- 如果在正则表达式之中,某个字符只表示它字面的含义,那么就叫做
“字面量字符”, - 除了字面量字符之外,还有一部分字符有特殊的含义,不代表字面的意思,它们叫做
“元字符”
2. 元字符
| 代码/语法 | 说明 | 示例 |
|---|---|---|
| . | 匹配除换行符以外的任意字符 | 比如”/a.c/”可以匹配,abc,adc,anc |
| \w | 匹配字母或数字或下划线 等价于’[A-Za-z0-9_]’ | 比如”/\w/”可以匹配,a,1,_,不能匹配空格 |
| \s | 匹配任意的空白符,包括空格、制表符、换页符,等价于 [ \f\n\r\t\v] | 比如”/\s/”可以匹配空格,a,1,_,不能匹配字母数字等字符 |
| \d | 匹配数字,等价于[0-9] | 比如”/\d/”可以匹配0到9的数字,但不能匹配字母符合等字符 |
| \b | 匹配单词的开始或结束 | 比如"er\b"可以匹配"never"中的"er",但是不能匹配"verb"中的"er" |
| ^ | 匹配字符串的开始 | “^The”:表示所有以"The"开始的字符串(“There”,"The cat"等) |
| $ | 匹配字符串的结束 | “of$”:表示所 以以"of "结尾的字符串(“Tkkof”,"tf fdsof"等) |
3. 反义元字符
| 代码/语法 | 说明 |
|---|---|
| \W | 匹配任意不是字母,数字,下划线,汉字的字符 |
| \S | 匹配任意不是空白符的字符[^\f\n\r\t\v] |
| \D | 匹配任意非数字的字符 |
| \B | 匹配不是单词开头或结束的位置 |
| [^x] | 匹配除了x以外的任意字符 |
| [^aeiou] | 匹配除了aeiou这几个字母以外的任意字符 |
x|y |
匹配 x 或 y |
4. 字符转义 \反斜杠
如果想查找元字符本身的话,比如你查找.或者*就出现了问题:你没办法指定它们,因为它们会被解释成别的意思。
- 这时你就得使用
" \ "来取消这些字符的特殊意义。因此,你应该使用" \. "和" \* "。当然,要查找\本身,你也得用" \\ "
例:
unibetter\.com匹配unibetter.com,C:\\Windows匹配C:\Windows
5. 重复元字符(限定符)
| 代码/语法 | 说明 | 示例 |
|---|---|---|
| * | 重复零次或更多次 “ab*” | 表示一个字符串有一个a后面跟着零个或若干个b。(“a”, “ab”, “abbb”,……) |
| + | 重复一次或更多次 “ab+” | 表示一个字符串有一个a后面跟着至少一个b或者更多 |
| ? | 重复零次或一次 “ab?” | 表示一个字符串有一个a后面跟着零个或者一个b |
| {n} | 重复n次 “ab{2}” | 表示一个字符串有一个a跟着2个b(“abb”) |
| {n,} | 至少重复n次或更多次 “ab{2,}” | 表示一个字符串有一个a跟着至少2个b |
| {n,m} | 重复n到m次 “ab{3,5}” | 表示一个字符串有一个a跟着3到5个b |
6.贪婪与懒惰
- 当正则表达式中包含能接受重复的限定符时,通常的行为是(在使整个表达式能得到匹配的前提下)
匹配尽可能多的字符。以这个表达式为例:a.*,它将会匹配最长的以a开始,以任意结束的字符串。如果用它来搜索aabab的话,它会匹配整个字符串aabab。这被称为贪婪匹配 - 有时,我们更需要
懒惰匹配,也就是匹配尽可能少的字符。前面给出的限定符都可以被转化为懒惰匹配模式,只要在它后面加上一个问号?。这样.*?就意味着匹配任意数量的重复,但是在能使整个匹配成功的前提下使用最少的重复
7.关于()分组
-
分组的作用是
改变默认的优先级
例如:/^18|19$/
181、189、119、819、1819...都符合,而不是我们认为的18或19,但是改成/^(18|19)$/就是单纯的18或19了 -
可以在捕获正则匹配的内容同时,把分组匹配的内容也进行捕获->分组捕获分组引用,例如:
/^(\d)(\w)\2\1$/,这里的\2是和第二个分组出现一模一样的内容,\1是和第一个分组出现一模一样的内容,例如:"0aa0"就符合了
(\d{1,3}\.){3}\d{1,3}是一个简单的IP地址匹配表达式。要理解这个表达式,请按下列顺序分析它:\d{1,3}匹配1-3位的数字,(\d{1,3}\.){3}匹配1-3位数字+一个英文句号(这个整体也就是这个分组)重复3次,最后再加上一个1-3位的数字(\d{1,3})
public static void main(String[] args) {
String str1 ="longen";
String str2 ="longenlongen";
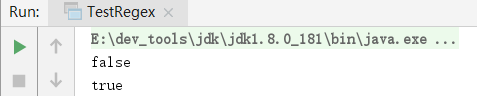
System.out.println(str1.matches("(longen){2}"));
System.out.println(str2.matches("(longen){2}"));
}
8.关于[]分组
-
简单字符组
[123]可以分别匹配包含1-3这3个数的字符串
[bcf]at可以分别匹配bat、cat、fat -
范围字符组,与
连字符 “-”一起使用
匹配数字:/[0-9]/
匹配HTML的标题标签:<h[1-6]>
匹配小写英文字母用字符组[a-z]匹配大写英文字母用字符组[A-Z] -
组合字符组: 由多种字符组组合一起的字符组
匹配a~f和1-5之间的字符 [a-f1-5], 字符组内不要有空格,有人喜欢在f和1之间加个空格
匹配大小写英文字母用字符组[a-zA-Z],这里最关键的是连字符 "-",不要理解为减号
匹配数字,字字母,下划线,美元符号:[0-9a-zA-Z_$] -
排除型字符组
匹配非数字字符[^0-9]
注意:范围不能乱写,比如只能 [0-9],不能[9-0]。不然正则表达式引擎解析会报错
9. 正则匹配模式
每个正则表达式都可带有一或多个标志(flags)
- g : 表示全局模式(global),即模式将被应用于所有字符串,而非在发现第一个匹配项就立即停止;
- i : 表示不区分大小写模式(case-insensitive),即在确定匹配项时忽略模式与字符串的大小写;
- m : 表示多行模式(multiline),即在到达一行文本结尾时还会继续查找下一行中是否存在与模式匹配的项
10.需要转义的特殊字符

三.Java中使用正则表达式
1.简单匹配规则
1.1.使用正则表达式进行精确匹配。
-
正则表达式的匹配规则是
从左到右按规则匹配。
对于正则表达式abc来说,它只能精确地匹配字符串"abc",不能匹配"ab",“Abc”,"abcd"等其他任何字符串。 -
如果正则表达式有
特殊字符,那就需要用“ \ ”转义。- 例如,正则表达
式a\&c,其中\&是用来匹配特殊字符&的,它能精确匹配字符串"a&c",但不能匹配"ac"、"a-c"、"a&&c"等。
- 例如,正则表达
-
正则表达式在Java代码中也是一个字符串,所以,对于正则表达式
a\&c来说,对应的Java字符串是"a\\&c",因为\也是Java字符串的转义字符,两个 "\\"实际上表示的是一个"\":
@Test
public void testAccurateMatch() {
String reg1 = "abc";
System.out.println("abc".matches(reg1));// true
System.out.println("Abc".matches(reg1));// false
System.out.println("abcd".matches(reg1));// false
String reg2 = "a\\&c"; // 对应的正则是a\&c
System.out.println("a&c".matches(reg2));// true
System.out.println("a-c".matches(reg2));// false
System.out.println("a&&c".matches(reg2));// false
}

如果想匹配非ASCII字符,例如中文,那就用\u####的十六进制表示
例如:a\u548cc匹配字符串"a和c",中文字符和的Unicode编码是548c。
1.2.匹配任意字符
精确匹配实际上用处不大,因为我们直接用String.equals()就可以做到。大多数情况下,我们想要的匹配规则更多的是模糊匹配。可以用 . 匹配一个任意字符。
例如,正则表达式a.c中间的. 可以匹配一个任意字符,下面的字符串都可以被匹配:
"abc",因为.可以匹配字符b;
"a&c",因为.可以匹配字符&;
"acc",因为.可以匹配字符c。
但它不能匹配"ac"、"a&&c",因为. 匹配一个字符且仅限一个字符。
@Test
public void testBlurMatch() {
String reg = "a.c";
System.out.println("abc".matches(reg));// "abc",因为.可以匹配字符b; true
System.out.println("a&c".matches(reg));// "a&c",因为.可以匹配字符&; true
System.out.println("acc".matches(reg));// "acc",因为.可以匹配字符c; true
//它不能匹配"ac"、"a&&c",因为.匹配一个字符且仅限一个字符。
System.out.println("ac".matches(reg));// false
System.out.println(" a&&c".matches(reg));// " false
}

1.3.匹配数字
用 .可以匹配任意字符,这个口子开得有点大。如果我们只想匹配0~9这样的数字,可以用\d匹配
例如: 正则表达式00\d可以匹配:
"007",因为\d可以匹配字符7;"008",因为\d可以匹配字符8。- 它不能匹配
"00A","0077",因为\d仅限单个数字字符。
@Test
public void testMatchNumber() {
String reg = "00\\d";
System.out.println("007".matches(reg));
System.out.println("008".matches(reg));
// 它不能匹配`"00A"`,`"0077"`,因为`\d`仅限单个数字字符。
System.out.println("00A".matches(reg));// false
System.out.println("0077".matches(reg));// " false
}

1.4. 匹配常用字符
用\w可以匹配一个字母、数字或下划线,w的意思是word。
例如: java\w可以匹配:
"javac",因为\w可以匹配英文字符c
-"java9",因为\w可以匹配数字字符9"java_",因为\w可以匹配下划线_- 它不能匹配
"java#","java ",因为\w不能匹配#、空格等字符。
@Test
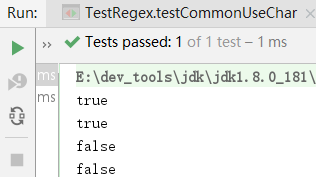
public void testCommonUseCharMatch() {
String reg = "java\\w";
System.out.println("java9".matches(reg));
System.out.println("java_".matches(reg));
// 它不能匹配`"java#"`,`"java "`,因为`\w`不能匹配`#`、`空格`等字符
System.out.println("java#".matches(reg));// false
System.out.println("java ".matches(reg));// " false
}
1.5. 匹配空格字符
用\s可以匹配一个空格字符,注意空格字符不但包括空格,还包括tab字符(在Java中用\t表示) 。
例如,a\sc可以匹配:
"a c",因为\s可以匹配空格字符;"a c",因为\s可以匹配tab字符\t。- 它不能匹配
"ac","abc"等。
@Test
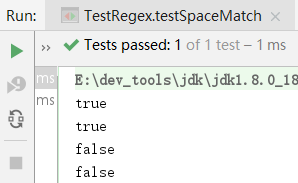
public void testSpaceMatch() {
String reg = "a\\sc";
System.out.println("a c".matches(reg));
System.out.println("a\tc".matches(reg));
System.out.println("ac".matches(reg));
System.out.println("abc ".matches(reg));
}
1.6. 匹配非数字
用\d可以匹配一个数字,而\D则匹配一个非数字。
例如,00\D可以匹配:
"00A",因为\D可以匹配非数字字符A;"00#",因为\D可以匹配非数字字符#。00\D是不能匹配的字符串"007","008"等数字字符
@Test
public void testMatch() {
//匹配数字
String re1 = "java\\d"; // 对应的正则是java\d
System.out.println("java9".matches(re1));//true
System.out.println("java10".matches(re1));//false,只能匹配一个
System.out.println("javac".matches(re1));//false
//匹配非数字
String re2 = "java\\D";
System.out.println("javax".matches(re2));//true
System.out.println("java#".matches(re2));//true
System.out.println("java5".matches(re2));//false
}

1.7. 重复匹配
匹配多个字符
-
修饰符
*可以匹配任意个字符,包括0个字符。我们用A\d*可以匹配:- A:因为\d*可以匹配0个数字;
- A0:因为\d*可以匹配1个数字0;
- A380:因为\d*可以匹配多个数字380。
-
修饰符
+可以匹配至少一个字符。我们用A\d+可以匹配:- A0:因为\d+可以匹配1个数字0;
- A380:因为\d+可以匹配多个数字380。
- 但它无法匹配"A",因为修饰符+要求至少一个字符。
-
修饰符
?可以匹配0个或一个字符。我们用A\d?可以匹配:- A:因为\d?可以匹配0个数字;
- A0:因为\d+可以匹配1个数字0。
- 但它无法匹配"A33",因为修饰符?超过1个字符就不能匹配了。
-
修饰符
{n}可以匹配n个字符。A\d{3}可以精确匹配:- A380:因为\d{3}可以匹配3个数字380。
-
用修饰符
{n,m}可以匹配n~m个字符。A\d{3,5}可以精确匹配:- A380:因为\d{3,5}可以匹配3个数字380;
- A3800:因为\d{3,5}可以匹配4个数字3800;
- A38000:因为\d{3,5}可以匹配5个数字38000。
如果没有上限,那么修饰符{n,}就可以匹配至少n个字符。
1.8.小结
单个字符的匹配规则如下:
| 正则表达式 | 规则 | 可以匹配 |
|---|---|---|
| A | 指定字符 | A |
| \u548c | 指定Unicode字符 | 和 |
| . | 任意字符 | a,b,&,0 |
| \d | 数字0~9 | 0~9 |
| \w | 大小写字母,数字和下划线 | az,AZ,0~9,_ |
| \s | 空格、Tab键 | 空格,Tab |
| \D | 非数字 | a,A,&,_,…… |
| \W | 非\w | &,@,中,…… |
| \S | 非\s | a,A,&,_,…… |
多个字符的匹配规则如下:
| 正则表达式 | 规则 | 可以匹配 |
|---|---|---|
| A* | 任意个数字符 | 空,A,AA,AAA,…… |
| A+ | 至少1个字符 | A,AA,AAA,…… |
| A? | 0个或1个字符 | 空,A |
| A{3} | 指定个数字符 | AAA |
| A{2,3 | 指定范围个数字符 | AA,AAA |
| A{2,} | 至少n个字符 | AA,AAA,AAAA,…… |
| A{0,3} | 最多n个字符 | 空,A,AA,AAA |
匹配国内的电话号码规则:34位区号加78位电话,中间用-连接,例如:010-12345678。
@Test
public void testMatchMachineNo() {
String reg = "\\d{3,4}-\\d{7,8}";
System.out.println("123-1234567".matches(reg));//true
System.out.println("123-12345678".matches(reg));//true
System.out.println("1234-1234567".matches(reg));//true
System.out.println("1234-12345678".matches(reg));//true
System.out.println("12341234567".matches(reg));//false
System.out.println("12834-12345678".matches(reg));//false
}
2.复杂匹配规则
2.1.匹配开头和结尾
用正则表达式进行多行匹配时,我们用^表示开头,$表示结尾
例如: ^A\d{3}$,可以匹配"A001"、"A380"。
@Test
public void testMatchFirstAndLast() {
// 表示以A开头,以3个数字结尾
String reg = "^A\\d{3}$";
System.out.println("A001".matches(reg));//true
System.out.println("A380".matches(reg));//true
System.out.println("A0001".matches(reg));//false
System.out.println("A3800".matches(reg));//false
System.out.println("A00a".matches(reg));//false
System.out.println("A38a".matches(reg));//false
}

2.2.匹配指定范围
如果我们规定一个7~8位数字的电话号码不能以0开头,应该怎么写匹配规则呢?
\d{7,8}是不行的,因为第一个\d 可以匹配到0。
使用[...]可以匹配范围内的字符
- 例如:
[123456789]可以匹配1~9,写出上述电话号码的规则:[123456789]\d{7,8} - 把所有字符全列出来太麻烦,
[...]还有一种写法,直接写[1-9]就可以。
要匹配大小写不限的十六进制数,如:1A2b3c,可以这样写:[0-9a-fA-F] 它表示一共可以匹配以下任意范围的字符
- 0-9:字符0~9;
- a-f:字符a~f;
- A-F:字符A~F。
如果要匹配6位十六进制数,前面讲过的{n}仍然可以继续配合使用:[0-9a-fA-F]{6}
[...]还有一种排除法,即不包含指定范围的字符。
假设我们要匹配任意字符,但不包括数字,可以写[^1-9]{3}:
- 可以匹配"ABC",因为不包含字符1~9;
- 可以匹配"A00",因为不包含字符1~9;
- 不能匹配"A01",因为包含字符1;
- 不能匹配"A05",因为包含字符5。
@Test
public void testMatchNoContains() {
// 表示匹配非数字的3位字符串
String reg = "[^1-9]{3}";
System.out.println("ABC".matches(reg));//true
System.out.println("A00".matches(reg));//true
System.out.println("A01".matches(reg));//false
System.out.println("A05".matches(reg));//false
System.out.println("ABCC".matches(reg));//false
System.out.println("Aa#".matches(reg));//true
}

2.3.或规则匹配
用 ” | “连接的两个正则规则是或规则
例如,AB|CD表示可以匹配AB或CD。
@Test
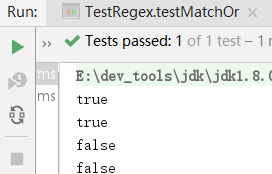
public void testMatchOr() {
// 表示匹配非数字的3位字符串
String reg = "AB|ab";
System.out.println("AB".matches(reg));//true
System.out.println("ab".matches(reg));//true
System.out.println("AC".matches(reg));//false
System.out.println("ac".matches(reg));//false
}
2.4.使用括号
现在我们想要匹配字符串learn java、learn php和learn c#怎么办?
- 一个最简单的规则是
learn\sjava|learn\sphp|learn\sgo,但是这个规则太复杂了,可以把公共部分提出来,然后用(...)把子规则括起来表示成learn\\s(java|php|c#)
@Test
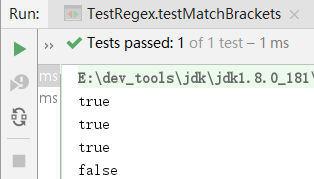
public void testMatchBrackets() {
// 表示匹配非数字的3位字符串
String reg = "learn\\s(java|php|c#)";
System.out.println("learn java".matches(reg));//true
System.out.println("learn php".matches(reg));//true
System.out.println("learn c#".matches(reg));//true
System.out.println("learn JAVA".matches(reg));//false
}
3.分组匹配
3.1.分组提取子串
我们前面讲到的(...)可以用来把一个子规则括起来,这样写learn\s(java|php|c#)就可以更方便地匹配长字符串了。
实际上(...)还有一个重要作用,就是分组匹配。
利用前面讲到的匹配规则,很容易写出匹配区号-电话号码这个规则:\d{3,4}\-\d{6,8}
虽然这个正则匹配规则很简单,但是往往匹配成功后,下一步是分别提取区号和电话号码,分别存入数据库。于是问题来了:如何提取匹配的子串?
- 可以用
String提供的indexOf()和substring()方法,但它们从正则匹配的字符串中提取子串没有通用性,下一次要提取learn\s(java|php)还得改代码。 - 正确的方法是用
(...)先把要提取的规则分组,把上述正则表达式变为(\d{3,4})\-(\d{6,8})。
匹配后,如何按括号提取子串?
现在我们没办法用 String.matches() 这样简单的判断方法了,必须引入 java.util.regex,用Pattern对象匹配,匹配后获得一个Matcher对象,如果匹配成功,就可以直接从Matcher.group(index) 返回子串:
@Test
public void testPattern() {
// 匹配国内的电话号码规则:3~4位区号加7~8位电话,中间用-连接,例如:010-12345678。
//用Pattern对象匹配,匹配后获得一个Matcher对象,如果匹配成功,就可以直接从Matcher.group(index)返回子串:
Pattern pattern = Pattern.compile("(\\d{3,4})-(\\d{7,8})");
Matcher matcher = pattern.matcher("123-1234567");
if (matcher.matches()) {
String str0 = matcher.group(0);//123-1234567 匹配正则的完整字符串
String str1 = matcher.group(1);//123 匹配第一组规则
String str2 = matcher.group(2);//1234567 匹配第二组规则
System.out.println(str0);
System.out.println(str1);
System.out.println(str2);
}else {
System.out.println("匹配失败!");
}
}
Matcher.group(index)方法的参数用1表示匹配第一个规则子串,2表示匹配第二个规则子串。如果我们传入0会得到整个正则匹配到的字符串。

3.2.Pattern
可以用java.util.regex包里面的Pattern类和Matcher类进行分组提取。
-
实际上
String.matches()方法内部调用的就是Pattern和Matcher类的方法。 -
反复使用
String.matches()对同一个正则表达式进行多次匹配效率较低 ,因为每次都会创建出一样的Pattern对象。 完全可以先创建出一个Pattern对象,然后反复使用,就可以实现编译一次,多次匹配
public static void main(String[] args) {
Pattern pattern = Pattern.compile("(\\d{3,4})-(\\d{7,8})");
pattern.matcher("010-12345678").matches(); // true
pattern.matcher("021-123456").matches(); // true
pattern.matcher("022#1234567").matches(); // false
// 获得Matcher对象:
Matcher matcher = pattern.matcher("010-12345678");
if (matcher.matches()) {
String whole = matcher.group(0); // "010-12345678", 0表示匹配的整个字符串
String area = matcher.group(1); // "010", 1表示匹配的第1个子串
String tel = matcher.group(2); // "12345678", 2表示匹配的第2个子串
System.out.println(area);
System.out.println(tel);
}
}
- 正则表达式用
(...)分组可以通过Matcher对象快速提取子串:- group(0)表示匹配的整个字符串;
- group(1)表示第1个子串,group(2)表示第2个子串,以此类推。
- 使用
Matcher时,必须首先调用matches()判断是否匹配成功,匹配成功后,才能调用group()提取子串
利用提取子串的功能,我们轻松获得了区号和号码两部分。
4.非贪婪匹配
4.1.什么是非贪婪匹配
在介绍非贪婪匹配前,我们先看一个简单的问题:
给定一个字符串表示的数字,判断该数字末尾0的个数。例如:
-"111000":3个0
-"10100":2个0
-"1001":0个0
可以很容易地写出该正则表达式:(\d+)(0*)
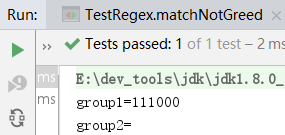
@Test
public void matchNotGreed() {
Pattern pattern = Pattern.compile("(\\d+)(0*)");
Matcher matcher = pattern.matcher("111000");
if (matcher.matches()) {
System.out.println("group1=" + matcher.group(1)); // "1230000"
System.out.println("group2=" + matcher.group(2)); // ""
}
}
然而打印的第二个子串是空字符串""。
实际上,我们期望分组匹配结果是:
| input | \d+ | 0* |
|---|---|---|
| 111000 | “111” | “000” |
| 10100 | “101” | “00” |
| 1001 | “1001” | “” |
但实际的分组匹配结果是这样的:
| input | \d+ | 0* |
|---|---|---|
| 123000 | “123000” | “” |
| 10100 | “10100” | “” |
| 1001 | “1001” | “” |
仔细观察上述实际匹配结果,实际上它是完全合理的,因为\d+确实可以匹配后面任意个0
这是因为正则表达式默认使用贪婪匹配:任何一个规则,它总是尽可能多地向后匹配,因此,\d+总是会把后面的0包含进来。
4.1.1.使用非贪婪匹配
要让\d+尽量少匹配,让0*尽量多匹配,我们就必须让\d+使用非贪婪匹配。在规则\d+后面加个?即可表示非贪婪匹配。我们改写正则表达式如下:
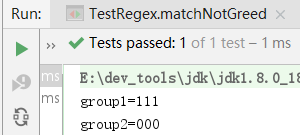
@Test
public void matchNotGreed() {
Pattern pattern = Pattern.compile("(\\d+?)(0*)");
Matcher matcher = pattern.matcher("111000");
if (matcher.matches()) {
System.out.println("group1=" + matcher.group(1)); // "111"
System.out.println("group2=" + matcher.group(2)); // "000"
}
}
因此得出结论: 正则表达式匹配默认使用贪婪匹配,可以使用?表示对某一规则进行非贪婪匹配。
注意区分?的含义:\d??
- 看这个正则表达式
(\d??)(9*),注意\d?表示匹配0个或1个数字,后面第二个?表示非贪婪匹配,因此,给定字符串"9999",匹配到的两个子串分别是""和"9999",因为对于\d?来说,可以匹配1个9,也可以匹配0个9,但是因为后面的?表示非贪婪匹配,它就会尽可能少的匹配,结果是匹配了0个9。
5.搜索和替换
5.1.分割字符串
使用正则表达式分割字符串可以实现更加灵活的功能:
String.split()方法传入的正是正则表达式。我们来看下面的代码:
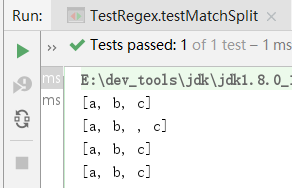
@Test
public void testMatchSplit() {
//以单个空白字符串为分割条件分割字符串
String[] strArr1 = "a b c".split("\\s"); // { "a", "b", "c" }
System.out.println(Arrays.toString(strArr1));
//以单个空白字符串为分割条件分割字符串
String[] strArr2 = "a b c".split("\\s"); // { "a", "b", "", "c" }
System.out.println(Arrays.toString(strArr2));
//以0个或者多个空白字符串为分割条件分割字符串
String[] strArr3 = "a b c".split("\\s+"); // { "a", "b", , "c" }
System.out.println(Arrays.toString(strArr3));
//以0个或者多个逗号/分号/空白字符
String[] strArr4 = "a, b ;; c".split("[\\,\\;\\s]+"); // { "a", "b", "c" }
System.out.println(Arrays.toString(strArr4));
}
如果我们想让用户输入一组字符串,然后把有效字符串提取出来,因为用户的输入往往是不规范的,这时,使用合适的正则表达式,就可以消除多个空格、混合,和;这些不规范的输入,直接提取出规范的字符串。
5.2.搜索字符串
使用正则表达式还可以搜索字符串:
@Test
public void testMatchSearch() {
String s = "the quick brown fox jumps over the lazy dog.";
Pattern pattern = Pattern.compile("\\wo\\w");
Matcher matcher = pattern.matcher(s);
while (matcher.find()) {
String sub = s.substring(matcher.start(), matcher.end());
System.out.println(sub);
}
}
获取到Matcher对象后,不需要调用matches()方法(因为匹配整个串肯定返回false),而是反复调用find()方法,在整个字符串中搜索能匹配上\\wo\\w规则的子串,并打印出来。
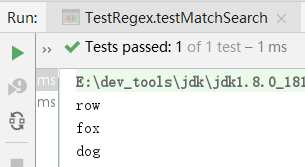
这种方式比String.indexOf()要灵活得多,因为我们搜索的规则是: ** 3个字符,中间必须是o,前后两个必须是字符[A-Za-z0-9_]**。
5.3.替换字符串
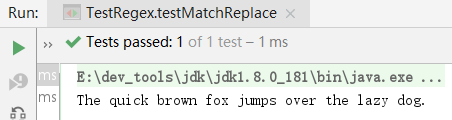
使用正则表达式替换字符串可以直接调用 String.replaceAll(),它的 第一个参数是正则表达式,第二个参数是待替换的字符串。
@Test
public void testMatchReplace() {
String s = "The quick\t\t brown fox jumps over the lazy dog.";
//将一个或者多个空白字符替换为一个空白字符串
String r = s.replaceAll("\\s+", " ");
System.out.println(r); // "The quick brown fox jumps over the lazy dog."
}
上面的代码把不规范的连续空格分隔的句子变成了规范的句子。可见,灵活使用正则表达式可以大大降低代码量。
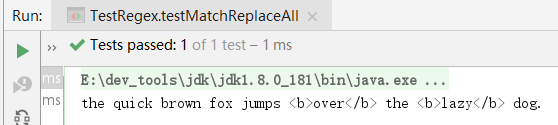
5.4.反向引用
如果我们要把搜索到的指定字符串按规则替换,比如前后各加一个<b>xxxx</b>,这个时候,使用replaceAll()的时候,我们传入的第二个参数可以使用 $1、$2来反向引用匹配到的子串。
语法: (x) 匹配 x 保存 x 在名为$1…$9的变量中
例如:
@Test
public void testMatchReplaceAll() {
String s = "the quick brown fox jumps over the lazy dog.";
String r = s.replaceAll("\\s([a-z]{4})\\s", " <b>$1</b> ");
System.out.println(r);
}
它实际上把任何4字符单词的前后用<b>xxxx</b>括起来。实现替换的关键就在于" <b>$1</b> ",它用匹配的分组子串([a-z]{4})替换了**$1**
5.1.Java中使用正则实现模板引擎功能
模板引擎是指,定义一个字符串作为模板:
您提现${borrowAmount}元至尾号${tailNo}的请求失败,您可以重新提交提款申请。
其中,以${key}表示的是变量,也就是将要被替换的内容
当传入一个Map<String, String>给模板后,需要把对应的key替换为Map的value。
例如,传入Map为:
{
"borrowAmount": "1000.00",
"tailNo": "1234"
}
然后,${borrowAmount}被替换为Map对应的值"1000.00”,${tailNo}被替换为Map对应的值"1234",最终输出的结果为:
您提现1000.00元至尾号1234的请求失败,您可以重新提交提款申请。
需要用到的方法:
- Matcher. appendReplacement:将当前匹配的子字符串替换为指定的字符串,并且将替换后的 字符串及其之前到上次匹配的子字符串之后的字符串添加到一个StringBuffer对象中。
- Matcher. appendTail:将最后一次匹配之后的字符串添加到一个StringBuffer对象中。
import org.junit.Test;
import java.text.ParseException;
import java.util.HashMap;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @Description TODO java模板引擎替换实现
*/
public class StringTemplateUtil {
public static final String DEF_REGEX_1 = "\\{(.+?)\\}";
public static final String DEF_REGEX_2 = "\\$\\{(.+?)\\}";
public static String render(String template, Map<String, String> data) {
return render(template, data, DEF_REGEX_1);
}
public static String render(String template, Map<String, String> data, String regex) {
if (template == null || template.trim().isEmpty()) {
return "";
}
if (regex == null || regex.trim().isEmpty()) {
return template;
}
if (data == null || data.size() == 0) {
return template;
}
try {
StringBuffer appendReplaceSb = new StringBuffer();
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(template);
while (matcher.find()) {
// String currentStr = matcher.group(0);//整个正则匹配的字符串
String key = matcher.group(1);//当前第一个子分组正则匹配的字符串
String value = data.get(key);
/*Matcher. appendReplacement:将当前匹配的子字符串替换为指定的字符串,并且将替换后的字符串
及其之前到上次匹配的子字符串之后的字符串添加到一个StringBuffer对象中。*/
matcher.appendReplacement(appendReplaceSb, value);//
}
/* Matcher. appendTail:将最后一次匹配之后的字符串添加到一个StringBuffer对象中。*/
matcher.appendTail(appendReplaceSb);
return appendReplaceSb.toString();
} catch (Exception e) {
e.printStackTrace();
}
return template;
}
@Test
public void test1() throws ParseException {
String template = "您提现{borrowAmount}元至尾号{tailNo}的请求失败,您可以重新提交提款申请。";
Map<String, String> data = new HashMap<String, String>();
data.put("borrowAmount", "1000.00");
data.put("tailNo", "1234");
System.out.println(render(template, data));
//执行结果:
//您提现1000.00元至尾号1234的请求失败,您可以重新提交提款申请。
}
@Test
public void test2() throws ParseException {
String template = "您提现${borrowAmount}元至尾号${tailNo}的请求失败,您可以重新提交提款申请。";
Map<String, String> data = new HashMap<String, String>();
data.put("borrowAmount", "1000.00");
data.put("tailNo", "1234");
System.out.println(render(template, data, StringTemplateUtil.DEF_REGEX_2));
//执行结果:
//您提现1000.00元至尾号1234的请求失败,您可以重新提交提款申请。
}
}
四.详解Pattern与Matcher类常用方法
1. java.util.Regex
java.util.Regex是一个Java中使用正则表达式对字符串进行匹配工作的类库。它包括两个类:Pattern和Matcher- Pattern: Pattern是一个正则表达式经编译后的表现方式。
- Matcher : 它依据Pattern对象做为匹配模式对字符串进行匹配。
2. 捕获组的概念
捕获组可以通过从左到右计算其开括号来编号,编号是从1开始的。
例如: 在表达式((A)(B(C)))中,存在四个这样的组:
1——>((A)(B(C)))
2——>(A)
3——>(B(C))
4——>(C)
开括号是 () , 闭括号是[ ] 。 这是用来表示区间的,也就是数字范围的 开括号用来表示开区间,闭括号用来表示闭区间。
比如说: x的值属于开区间(1,10) 表示x的那个值介于1和10之间(不包括1和10)
又 x取值属于闭区间[1,10] 表示x的值介于1和10之间(包括1和10,也就是x有等于10和1的可能)
- 要查找表达式中存在多少个组,请在匹配器对象上调用
groupCount方法。groupCount方法返回一个int,显示匹配器模式中存在的捕获组数。 - 还有一个特殊组,即
组0,它始终代表整个表达式。 该组未包含在groupCount报告的总数中。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegexMatches {
public static void main( String args[] ) {
// String to be scanned to find the pattern.
String line = "This order was placed for QT3000! OK?";
String pattern = "(.*)(\d+)(.*)";
// Create a Pattern object
Pattern r = Pattern.compile(pattern);
// Now create matcher object.
Matcher m = r.matcher(line);
if (m.find( )) {
System.out.println("Found value: " + m.group(0) );
System.out.println("Found value: " + m.group(1) );
System.out.println("Found value: " + m.group(2) );
} else {
System.out.println("NO MATCH");
}
}
}
Found value: This order was placed for QT3000! OK?
Found value: This order was placed for QT300
Found value: 0
3.常用方法
3.1.Pattern.complie
Pattern类用于创建一个正则表达式,也可以说创建一个匹配模式,它的构造方法是私有的,不可以直接创建,但可以通过Pattern.complie(String regex)简单工厂方法创建一个正则表达式,
- Pattern.complie(String reg)
Pattern p=Pattern.compile("\\w+");
p.pattern();//返回 \w+
pattern()返回正则表达式的字符串形式,其实就是返回complile(String regex)的regex参数
- Pattern.compile(String regex, int flags):
不常用,一般默认方式就足够了
flags取自java.util.regex.Duration类的字段 -- static int CANON_EQ - 启用规范等价。
- static int CASE_INSENSITIVE - 启用不区分大小写的匹配。
- static int COMMENTS - 允许模式中的空格和注释。
- static int DOTALL - 启用dotall模式。
- static int LITERAL - 启用模式的文字解析。
- static int MULTILINE - 启用多行模式。
- static int UNICODE_CASE - 启用支持Unicode的案例折叠。
- static int UNICODE_CHARACTER_CLASS - 启用Unicode版本的预定义字符类和POSIX字符类。
- static int UNIX_LINES - 启用Unix行模式。
import java.util.regex.MatchResult;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class PatternDemo {
private static final String REGEX = "(.*)(\\d+)(.*)?# 3 capturing groups";
private static final String INPUT = "This is a sample Text, 1234, with numbers in between.";
public static void main(String[] args) {
// create a pattern
Pattern pattern = Pattern.compile(REGEX,Pattern.COMMENTS);
// get a matcher object
Matcher matcher = pattern.matcher(INPUT);
if(matcher.find()) {
//get the MatchResult Object
MatchResult result = matcher.toMatchResult();
//Prints the offset after the last character matched.
System.out.println("First Capturing Group - Match String end(): "+result.end());
}
}
}
First Capturing Group - Match String end(): 53
3.2.Pattern.split
- Pattern.split(CharSequence input): 使用正则表达式中的字符分割待匹配的字符串,并返回一String[]
String.split(String regex)底层就是通过Pattern.split(CharSequence input)来实现的.
/**
* 测试Pattern.split方法
*/
@Test
public void testPatternSplit() {
String str = "{0x40, 0x11, 0x00, 0x00}";
// 分割符为:逗号, {,}, 空白符
String regex = "[,\\{\\}\\s]";
Pattern pattern = Pattern.compile(regex);
/*
* 1. split 方法用于使用正则表达式中的字符分割待匹配的字符串
*
* 注意:
* 1. 如果分割符位于原字符串的起始位置,则分割的时候,会在起始位置上分割出一个""出来
* 2. 如果有连续两个分隔符,则会在这两个分割符之间分割有一个""出来
* */
System.out.println("----------- split test -----------");
String[] results = pattern.split(str);
System.out.println("length :" + results.length);
for (int i = 0; i < results.length; i++) {
System.out.println("element_" +i + " :" + results[i]);
}
System.out.println(Arrays.toString(results));
/*
* 2. split方法的limit参数的意思是使用正则表达式的分割字符将原字符串分为limit个组
* **/
System.out.println("\n----------- split limit test -----------");
String[] resultsLimit = pattern.split(str, 2);
for (int i = 0; i < resultsLimit.length; i++) {
System.out.print(resultsLimit[i]);
}
}
----------- split test -----------
element_0 :
element_1 :0x40
element_2 :
element_3 :0x11
element_4 :
element_5 :0x00
element_6 :
element_7 :0x00
[, 0x40, , 0x11, , 0x00, , 0x00]
----------- split limit test -----------
0x40, 0x11, 0x00, 0x00}
3.3.Pattern.matcher
Pattern.matcher(String regex,CharSequence input):是一个静态方法,用于快速匹配字符串,该方法适合用于只匹配一次,且匹配全部字符串.
Pattern.matches("\\d+","2223");//返回true
Pattern.matches("\\d+","2223aa");//返回false,这里aa不能匹配到
Pattern.matches("\\d+","22bb23");//返回false,这里bb不能匹配到
3.4.Pattern实例.matcher
Pattern实例.matcher(CharSequence input):Pattern实例.matcher(CharSequence input)返回一个Matcher对象- Matcher类的构造方法也是私有的,不能随意创建,只能通过
Pattern实例.matcher(CharSequence input)方法得到该类的实例 - Pattern类只能做一些
简单的匹配操作,要想得到更强更便捷的正则匹配操作,那就需要将Pattern与Matcher一起合作. Matcher类提供了对正则表达式的分组匹配,以及对正则表达式的多次匹配
- Matcher类的构造方法也是私有的,不能随意创建,只能通过
Pattern pattern=Pattern.compile("\\d+");
Matcher matcher =pattern.matcher("22bb23");
matcher.pattern();//返回Pattern对象 也就是返回该Matcher对象是由哪个Pattern对象的创建的
3.5.Matcher实例.matches()/lookingAt()/find()
Matcher类提供三个匹配操作方法: 三个方法均返回boolean类型,当匹配到时返回true,没匹配到则返回false
- matches() :对整个字符串进行匹配,只有整个字符串都匹配了才返回true
Pattern pattern=Pattern.compile("\\d+");
Matcher matcher =pattern.matcher("22bb23");
matcher.matches();//返回false,因为bb不能被\d+匹配,导致整个字符串匹配未成功.
Matcher matcher2 =pattern.matcher("2223");
matcher2 .matches();//返回true,因为\d+匹配到了整个字符串
Pattern.matcher(String regex,CharSequence input)等价 Pattern.compile(regex).matcher(input).matches()
- lookingAt() : 对前面的字符串进行匹配,只有匹配到的字符串在最前面才返回true
Pattern pattern=Pattern.compile("\\d+");
Matcher matcher =pattern.matcher("22bb23");
matcher .lookingAt();//返回true,因为\d+匹配到了前面的22
Matcher matcher2=p.matcher("aa2223");
matcher2.lookingAt();//返回false,因为\d+不能匹配前面的aa
- find() : 对字符串进行匹配,匹配到的字符串可以在任何位置
Pattern pattern=Pattern.compile("\\d+");
Matcher matcher =pattern.matcher("22bb23");
matcher.find();//返回true
Matcher matcher2=pattern.matcher("aa2223");
matcher2.find();//返回true
Matcher matcher3=pattern.matcher("aa2223bb");
matcher3.find();//返回true
Matcher matcher4=pattern.matcher("aabb");
matcher4.find();//返回false
3.6.Mathcer实例.start()/ Matcher.end()/ Matcher.group()
当使用matches(),lookingAt(),find()执行匹配操作后,就可以利用以上三个方法得到更详细的信息.
- start(i) :返回此子分组匹配到的子字符串
第一个字符在原字符串中的下标位置,下标从0开始(包含) - end(i) :返回此子分组匹配到的子字符串的
最后一个字符在原字符串中的下标位置. (不包含) - group(i) : 返回匹配到的子字符串 ,
指的是用()包含的子分组,按照定义的顺序标识下标,当正则表达式中使用 |连接分组,那么有的分组匹配的字串可能为null。 - groupCount():返回当前查找所获得的匹配组的数量,不包括整个整个正则表达式的匹配。
比如,表达式有两个子分组,则groupCount == 2
@Test
public void testMatcherGroupFindStartEnd() {
String str = "{0x40, 0x31, 0x20, 0x00}";
String regex = "([A-Za-z0-9]+)(,)";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(str);
// 对于在整个原字符串中,找到的下一个匹配的字串
while (matcher.find()) {
// 输出groupCount的数量
System.out.println("groupCount : " + matcher.groupCount());
// 0-输出整个匹配
System.out.println("the substring of contains all group : " + matcher.group(0));
System.out.println("group_0 start index : " + matcher.start(0) + " end :" + matcher.end(0));
// 依次输出子分组的匹配结果
// 如果子分组之间是通过 | 来连接的,则子分组的匹配结果有的为null
for (int i = 1; i <= matcher.groupCount(); i++) {
System.out.println("group_" + i + ":" + matcher.group(i));
System.out.println("group_" + i + " start index : " + matcher.start(i) + " end :" + matcher.end(i));
}
}
}
groupCount : 2
the substring of contains all group : 0x40,
group_0 start index : 1 end :6
group_1:0x40
group_1 start index : 1 end :5
group_2:,
group_2 start index : 5 end :6
groupCount : 2
the substring of contains all group : 0x31,
group_0 start index : 7 end :12
group_1:0x31
group_1 start index : 7 end :11
group_2:,
group_2 start index : 11 end :12
groupCount : 2
the substring of contains all group : 0x20,
group_0 start index : 13 end :18
group_1:0x20
group_1 start index : 13 end :17
group_2:,
group_2 start index : 17 end :18
每次执行匹配操作后start(),end(),group()三个方法的值都会改变,变成匹配到的子字符串,以及它们的重载方法,也会改变成相应的信息.
- 注意: 只有当匹配操作成功,才可以使用start(),end(),group()
三个方法,否则会抛出java.lang.IllegalStateException,也就是当matches(),lookingAt(),find()其中任意一个方法返回true时,才可以使用.
Pattern p=Pattern.compile("\\d+");
Matcher m=p.matcher("我的QQ是:456456 我的电话是:0532214 我的邮箱是:[email protected]");
while(m.find()) {
System.out.println(m.group());
System.out.print("start:"+m.start());
System.out.println(" end:"+m.end());
}
456456
start:6 end:12
0532214
start:19 end:26
123
start:36 end:39
3.7.Matcher的replace/append方法详解
- matcher.replaceAll() :替换在
原字符串中所有被正则表达式匹配的字串,并返回替换之后的结果 - matcher.replaceFirst() :替换在
原字符串中第一个被正则表达式匹配的字串,并返回替换之后的结果 - matcher.appendReplacement() : 将当前匹配子串替换为
指定字符串,并且将替换后的子串以及其之前到上次匹配子串之后的字符串段添加到一个StringBuffer对象里(需while(matcher.find())进行配合迭代) - matcher.appendTail(StringBuffer sb) 将
最后一次匹配后剩余的字符串添加到一个StringBuffer对象里。3和4的结合能够实现将原字符串中的某些字串替换指定字符,并返回完成替换之后的结果
@Test
public void testMatcherReplaceAppend() {
String str = "{0x40, 0x31, 0x20, 0x00}";
String regex = "([0-9A-Za-z]+)";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(str);
// replaceAll
System.out.println("----------- replace all test ----------");
String replacedAllStr = matcher.replaceAll("replace");
System.out.println("replaced : " + replacedAllStr);
//matcher.reset(str); // 重置被matcher的字符串
matcher.reset(); // 重置matcher,以实现对原字符串重新搜索
// replaceFirst
System.out.println("------------ replace first test ---------");
String replacedFirstStr = matcher.replaceFirst("replace");
System.out.println("replaced first : " + replacedFirstStr);
matcher.reset();
// appendReplacement
System.out.println("------------- appendReplacement test ------------");
StringBuffer appendRepStr = new StringBuffer();
while (matcher.find()) {
matcher.appendReplacement(appendRepStr,"0xffff");
}
System.out.println(appendRepStr);
// 最后调用appendTail将匹配剩余的字符串添加都StringBuffer的末尾
// 注意这时要实现完整的功能:将所有匹配的内容替换并添加到appendRepStr中,剩余未匹配的继续添加到
// appendRepStr中,相当于对原字符串进行全部的替换
// 此时要保证,在遍历所有匹配的字串后调用appendTail方法
System.out.println("------------ appendTail test ---------------");
matcher.appendTail(appendRepStr);
System.out.println(appendRepStr);
}
----------- replace all test ----------
replaced : {replace, replace, replace, replace}
------------ replace first test ---------
replaced first : {replace, 0x31, 0x20, 0x00}
------------- appendReplacement test ------------
{0xffff, 0xffff, 0xffff, 0xffff
------------ appendTail test ---------------
{0xffff, 0xffff, 0xffff, 0xffff}