要理解SVM的损失函数,先定义决策边界。假设现在数据中总计有个训练样本,每个训练样本i可以被表示为
,其中xi是
这样的一个特征向量,每个样本总共含有n个特征。二分类标签yi的取值是{-1, 1}。
如果n等于2,则有i=(x1i,x2i,yi)T,分别由特征向量和标签组成。此时可以在二维平面上,以x2为横坐标,x1 为纵坐标,y为颜色,可视化所有的N个样本:
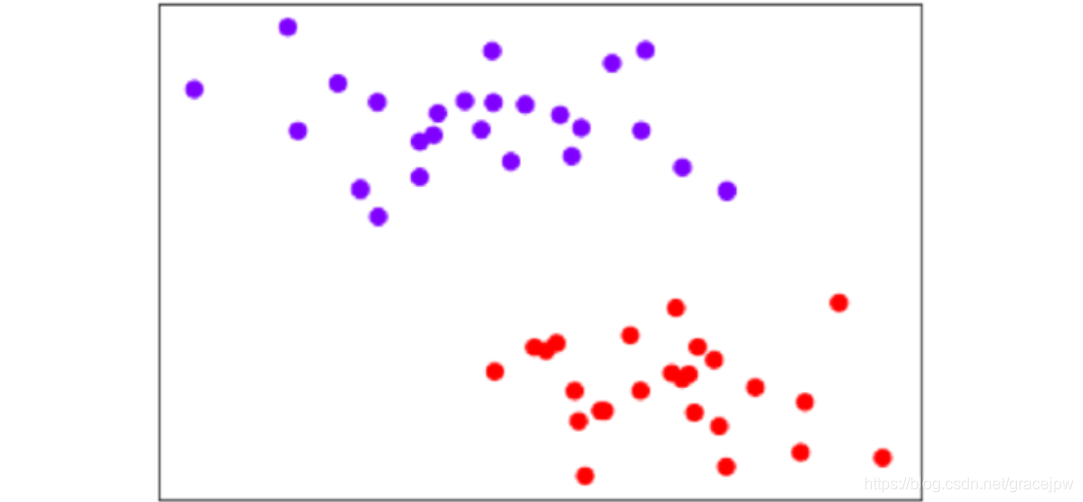
让所有紫色点的标签为1,红色点的标签为-1。要在这个数据集上寻找一个决策边界,在二维平面上,决策边界(超平面)就是一条直线。二维平面上的任意一条线可以被表示为:
变换表达式如下:
其中[a, -1]就是参数向量ω, x就是特征向量, b是截距。注意,这个表达式长得非常像线性回归公式:
线性回归中等号的一边是标签,回归过后会拟合出一个标签,而决策边界的表达式中却没有标签存在,全部是由参数,特征和截距组成的一个式子,等号的一边是0。
在一组数据下,给定固定的ω和b,这个式子就可以是一条固定直线,在ω和b不确定的状况下,表达式ωTx+b=0可以代表平面上的任意一条直线。如果ω和b固定,给定一个唯一的x取值,表达式就可以表示一个固定的点。在SVM中,就使用这个表达式表示决策边界。
目标是求解能够让边际最大化的决策边界,所以要求解参数向量和截距。
如果在决策边界上任意取两个点xa,xb ,并带入决策边界的表达式,则有:
两式相减,得到:
一个列向量的转置乘以另一个列向量,可以获得两个向量的点积(dot product),表示为
。两个向量的点积为0表示两个向量的方向相互垂直。xa与xb是一条直线上的两个点,相减后的得到的向量方向由xb指向xa,所以xa-xb的方向平行于他们所在的直线——决策边界。而ω与xa-xb相互垂直,所以参数向量ω的方向必然垂直于决策边界。
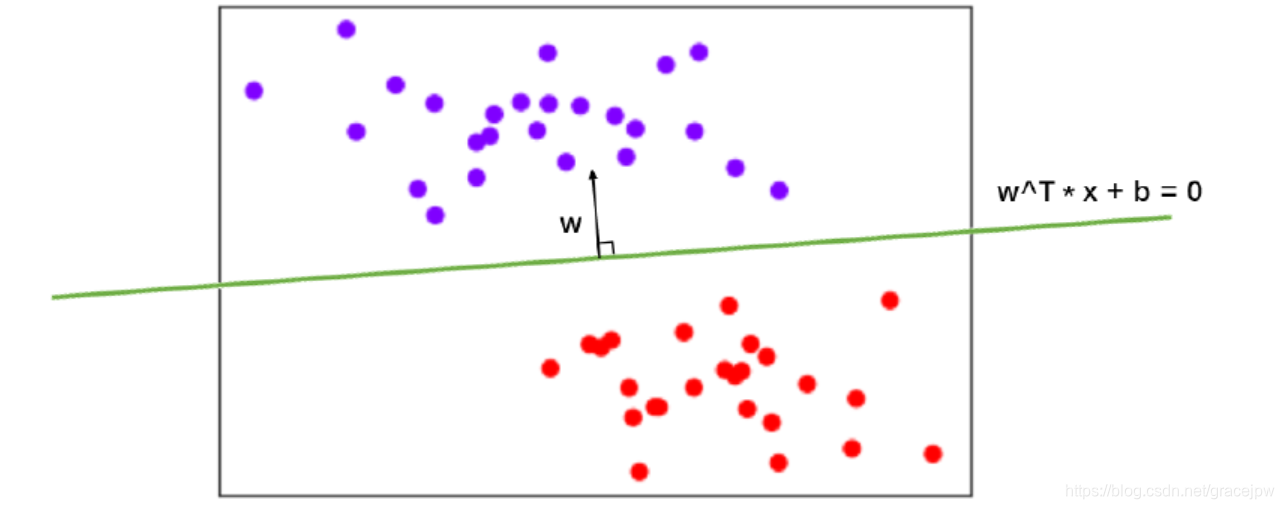
此时,有了决策边界。任意一个紫色的点xp就可以被表示为:
由于紫色的点所代表的标签y是1,所以规定,p>0。同样的,对于任意一个红色的点xr而言,可以表示为:
由于红色点所表示的标签y是-1,所以规定,r<0。由此,如果有新的测试数据,则xt的标签可以根据以下表达式判定:
为了推导和计算的简便,规定:
标签是{-1,1}
决策边界以上的点,标签都为正,并且通过调整ω和b的符号,让这个点在
上得出的结果为正。
决策边界以下的点,标签都为负,并且通过调整ω和b的符号,让这个点在
上得出的结果为负。
结论:决策边界以上的点都为正,以下的点都为负,是我们为了计算简便,而人为规定的。这种规定,不会影响对参数向量和截距的求解。
决策边界的两边要有两个超平面,这两个超平面在二维空间中就是两条平行线(即:虚线超平面),而他们之间的距离就是边际d。而决策边界位于这两条线的中间,所以这两条平行线必然是对称的。令这两条平行线被表示为:
两个表达式同时除以k,得到:
这就是平行于决策边界的两条线的表达式,表达式两边的1和-1分别表示了两条平行于决策边界的虚线到决策边界的相对距离。此时,可以让这两条线分别过两类数据中距离决策边界最近的点,这些点就被称为“支持向量”,而决策边界永远在这两条线的中间,所以可以被调整。我们令紫色类的点为xp,红色类的点为xr,得到:
两式相减,则有:
如下图所示,xp-xr可表示为两点之间的连线,而边际d是平行于ω的,所以xp-xr相当于三角型的斜边,并且知道一条直角边的方向。在线性代数中,有如下数学性质:
线性代数中模长的运用
向量b除以自身的模长||b||可以得到b方向上的单位向量。
向量a乘以向量b方向上的单位向量,可以得到向量a在向量b方向上的投影的长度。
所以,上述表达式两边同时除以||ω||,得到:
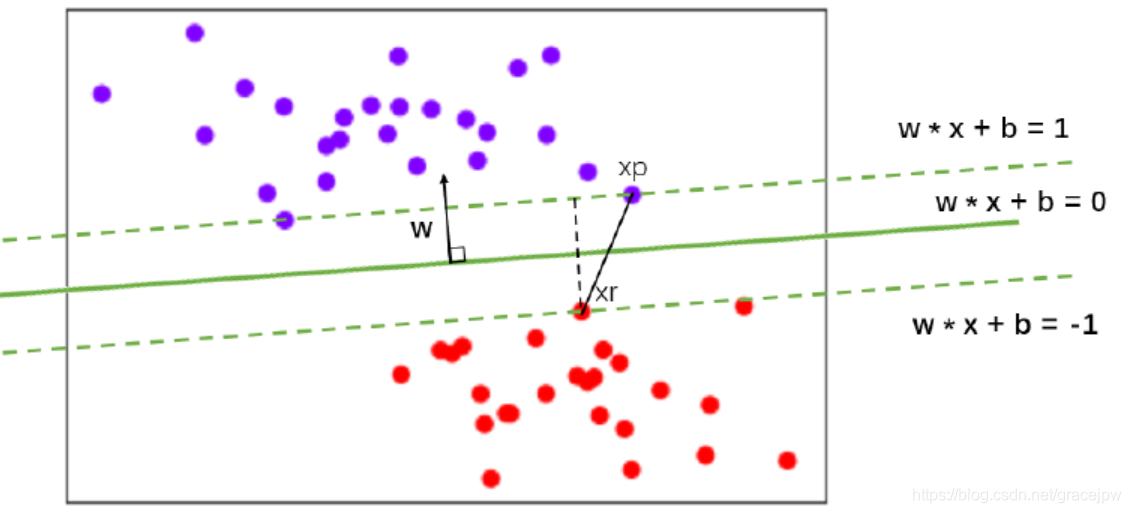
至此,计算最大边界所对应的决策边界问题,就转换成了:求解ω的最小值,使得d最大化。极值问题可以相互转化,把求解ω的最小值转化为求解以下函数的最小值:
之所以要在模长上加上平方,是因为模长的本质是一个距离,所以它是一个带根号的存在,对它取平方,是为了消除根号(其实模长的本质是向量的L2范式,还记得L2范式公式如何写的小伙伴必定豁然开朗)。
两条虚线表示的超平面,是数据边缘所在的点。所以对于任意样本i,可以把决策函数写作:
整理一下,可以把两个式子整合成:
在一部分教材中,这个式子被称为“函数间隔”。将函数间隔作为条件附加到f(ω)上,得到了SVM的损失函数最初形态:
服从
到这里,就完成了对SVM第一层理解的第一部分:线性SVM做二分类的损失函数。
机器学习:线性SVM的损失函数
猜你喜欢
转载自blog.csdn.net/gracejpw/article/details/102643797
今日推荐
周排行