版权声明:本文为博主原创文章,未经博主允许不得转载。http://www.cnblogs.com/jokermo/
1.区别
- HashTable是线程安全的,HashmMap是非线程安全的
- HashTable不允许键和值为null,HashMap允许键和值为null
- HashMap提供了可供应用迭代的键的集合,所以HashMap是快速失败的,HashTable提供对键的枚举,是安全失败的
- 扩容的参数不一样,HashMap要保证每次扩容后是2的次方,HashTable是扩大一倍
- 散列计算不一样
虽然HashTable是线程安全的,适用于多线程。但是一般不推荐使用,因为HashTable是遗留类,内部实现很多没有优化和冗余,使用ConcurrentHashMap代替HashTable在多线程中使用。
2.HashMap底层实现
HashMap是存储键值对的聚合,也就是以Key-Value为键值对存储,也称为Entry。Entry分散存储在一个数组中。HashMap最常用的方法是Get与Put.
Put的原理
例如这是一个HashMapd的数组,初始化时都为null

现在调用HashMap.Put("dog","0");
这时候我们需要利用一个哈希函数来确定Entry的插入位置(index):
index = Hash(“dog”)
假定最后计算出的index是2,那么结果如下:

但是HashMap数组的长度是有限的,如果hash()出来的index对应的值中已经有数据了,这样就发生了hash冲突比如index = Hash("cat")
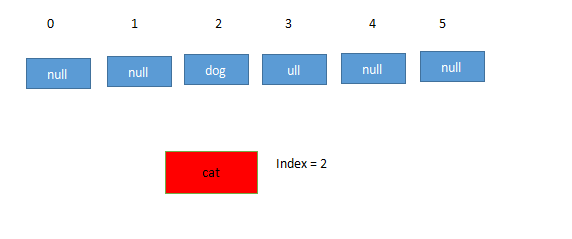
这时候就要用链表来解决了。HashMap数组的每一个元素不止是一个Entry对象,也是一个链表的头节点。每一个Entry对象通过Next指针指向它的下一个Entry节点。当新来的Entry映射到冲突的数组位置时,
只需要插入到对应的链表即可:
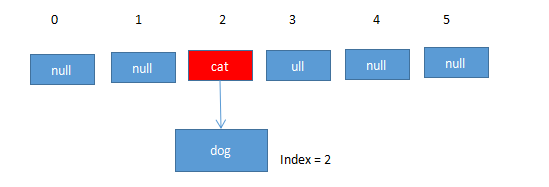
注意:这里使用的是“头插法”,因为设计者认为后插入的数据更容易被查找。
Get的原理
当调用Get("dog")时,首先
首先会把输入的Key做一次Hash映射,得到对应的index:index = Hash(“apple”)
以为存在hash冲突,对应的index找到的值不止一个,所以这个列子会进行两步操作:
第一步:
先找到cat,cat不是我们想要的,然后进行往下找。
第二步:
找到dog,完成!
到现在为止HashMap的底层原理基本完成。接下来是更底层的东西了!!!
3.HashMap底层实现
HashMap的默认长度为什么是16?每次扩容为什么是2的次幂?
之所以选择16,是为了服务于从Key映射到index的hash算法。为了实现一个尽量均匀分布的Hash函数,设计者采用了位运算方式。公式如下:
index = HashCode(Key) & (Length - 1)(Length是HashMap的长度)
下面我们以值为“book”的Key来演示整个过程:
1.计算book的hashcode,结果为十进制的3029737,二进制的101110001110101110 1001。
2.假定HashMap长度是默认的16,计算Length-1的结果为十进制的15,二进制的1111。
3.把以上两个结果做与运算,101110001110101110 1001 & 1111 = 1001,十进制是9,所以 index=9。
可以说,Hash算法最终得到的index结果,完全取决于Key的Hashcode值的最后几位。
长度16或者其他2的幂,Length-1的值是所有二进制位全为1,这种情况下,index的结果等同于HashCode后几位的值。只要输入的HashCode本身分布均匀,Hash算法的结果就是均匀的。
注:列子取自公众号《程序员小灰》