目标轮廓检测与全卷积编解码器网络
摘要
本文实现一种基于全卷积编解码器网络的轮廓检测深度学习算法[1]。与以往的低级边缘检测不同,该算法重点是检测高级对象轮廓。算法网络是在PASCALVOC上进行端到端训练的,从不准确的多边形注释中提炼出ground truth,在目标轮廓检测方面比以前的方法具有更高的精度。所学习的模型很好地推广到来自MSCOCO上相同超级类别的看不见的对象类,并且可以将BSDS500上最先进的边缘检测与微调相匹配。通过与多尺度组合分组算法相结合,该算法可以生成高质量的分段对象提案,并大大提高了PASCALVOC的最先进水平(将平均召回率从0.62提高到0.67),并且具有相对较少的candidates(每幅图像为1660)。
对象轮廓检测是许多视觉任务的基础。例如,它可以用于图像分割、对象检测以及遮挡和深度推理。然而,鉴于其公理化的重要性,我们发现在文献中对象轮廓检测的研究相对较少。与此同时,许多学者还致力于研究反应前景对象和背景边界(图1(B))的边缘检测。在本文中,我们解决了“只针对对象”的轮廓检测问题,这种检测有望抑制背景边界(图1(c))。

图 1对象轮廓检测。输入图像(a),与传统的边缘检测(b)相比,我们的模型可以有效地学习了检测前景物体的轮廓(c)。
边缘检测有着悠久的历史。早期的研究集中在设计简单的滤波器来检测其局部邻域中具有最高梯度的像素,例如Sobel和Canny。基于滤波器的方法的主要问题是,它们只查看相邻像素之间的颜色或亮度差异,但不能在较大的视野中分辨纹理差异。随着texture descriptors的进步,Martin[37]在它们的概率边界检测器中的组合了颜色、亮度和纹理梯度。Arbelaez[3]通过计算来自多尺度和光谱聚类的局部线索(称为gPb)进一步改进了这一点,它将精度提高到最先进的水平。然而,gPb的全局化步骤显著增加了计算负载。Lim and Dollar[30,12]分析了局部等高线图的聚类结构,开发了高效的快速边缘检测的监督学习算法。这些工作将边缘检测提升到更高的抽象水平,但由于缺乏对象级知识,仍然低于人类的感知。
最近,深卷积网络[29]显示了学习对象识别高层次表示的的显著能力[18,10]。这些学习的特征已经被用来检测自然图像边缘[25,6,43,47]并产生一个新的最先进的性能[47]。所有这些方法都需要在ground truth轮廓注释上进行训练。然而,由于收集高质量的轮廓注释是十分困难的,因此用于训练轮廓检测器的可用数据集非常有限,而且规模很小。例如,Berkeley segmentation(BSDS500)[36]和NYU depth v2(NYUDv2)[44]数据集分别只包括200和381幅训练图像。因此,深度卷积网络的表示能力还没有完全用于轮廓检测。论文将基于深度学习的轮廓检测训练集推广到PASCALVOC[14]上的10k以上图像。为了解决ground truth轮廓注释的质量问题,该论文开发了一种基于密集CRF[26]的方法来细化多边形的对象分割掩码。
给定图像轮廓对,将目标轮廓检测作为图像标记问题。在全卷积网络和反卷积网络语义分割成功的启发下,论文提出了一个全卷积编解码器网络(CEDN)。这个网络是完全卷积的,可以在任意图像大小上工作,编码-解码器网络强调其不同于反卷积网络的非对称结构。用VGG-16网络[45]初始化编码器(直到“fc6”层),为了实现密集图像大小的预测,网络的解码器是通过交替的反池化层和卷积层来构造的,其中反池化层重复使用从编码器的最大池化层到高层的特征映射。在训练过程中固定编码器参数(VGG-16),只优化解码器参数。这允许编码器保持其泛化能力,以便学习到的解码器网络可以很容易地与其他任务相结合,例如bounding-box回归或语义分割。
论文在BSDS500和MS COCO数据集上评估了训练网络,并发现该网络很好地推广到与训练集中的对象类似的“超级类别”中的对象,例如。它概括了“动物”超级类别中的“熊”之类的对象,因为“狗”和“猫”在训练集中。论文还表明,经过训练的网络可以很容易地适应通过几次迭代的微调来检测自然图像边缘,这与最先进的算法[47]产生了可比较的结果。
轮廓检测的一个直接应用是生成目标提案。以往的文献研究了通过评价边缘特征和组合分组[46,9,4]等方法生成边界框或分段对象提案的各种方法。本文使用多尺度组合分组(MCG)算法[4]从轮廓检测中生成分段对象提案。因此,我们的方法显著提高了PASCALVOC2012验证集上的分段对象提案的质量,实现了0.67的平均recall,从重叠0.5到1.0,每幅图像有大约1660个候选,而原始基于P的MCG算法的最先进的平均recall为0.62,每幅图像接近5140个候选。我们还评估了带有80个对象类的MS COCO数据集的对象提案,并分析了来自不同对象类及其超级类别的平均recall。
主要贡献概述如下:
- 我们开发了一个简单而有效的用于对象轮廓预测的全卷积编解码器网络,并且经过训练的模型从相同的超级类别很好地推广到看不见的对象类,在对象轮廓检测方面比以前的方法具有更高的精度。
- 我们表明,我们可以微调我们的网络边缘检测,并匹配最先进的精度和召回。
- 我们从不完全基于多边形的分割注释中生成精确的对象轮廓,这使得在尺度上训练对象轮廓检测器成为可能。
- 我们的方法通过与组合分组[4]集成,获得了分段对象提案的最新结果。
语义轮廓检测。Hariharan[19]研究自顶向下轮廓检测问题。它们的语义轮廓检测器[19]致力于寻找不同对象类之间的语义边界。虽然他们在收集注释时考虑对象实例轮廓,但他们选择忽略来自同一类的对象实例之间的遮挡边界。由于将自底向上边缘与对象检测器输出相结合,它们的方法可以扩展到对象实例轮廓,但在推广到未见对象类时会遭遇更多挑战。
遮挡边界检测。Hoiem[20]研究从单一图像中恢复遮挡边界的问题。这显然是一个非常具有挑战性的不适定问题,因为部分可观测性,同时将三维场景投影到二维图像平面上。他们制定了一个CRF模型来整合各种线索:颜色、位置、边缘、表面取向和深度估计。
对象提案生成。在生成边界框或分段对象提案方面有大量的工作。Hosang[21]和Jordi [39]介绍了关于最先进算法的良好概述和分析。边界框提案生成是由高效的对象检测驱动的。它们的缺点之一是边界框通常不能提供精确的对象定位。与本文工作相关的是生成分段对象提案。分割目标提案算法的核心是轮廓检测和超像素分割。本文用一种最先进的多尺度组合分组[4]方法进行实验,以产生提案,并相信对象轮廓检测器可以直接植入大多数算法。
将轮廓检测描述为二值图像标记问题,其中“1”和“0”分别表示“轮廓”和“非轮廓”。图像标记是一项需要高级知识和低级线索的任务。鉴于深度卷积网络能成功地学习丰富的特征层次结构,图像标记已经取得了很大的进展,特别是在语义分割的任务上。在这些端到端方法中,完全卷积网络很好地扩展到图像大小,但不能产生非常精确的标记边界;反池化层帮助反卷积网络产生更好的标签定位,但它们的对称结构引入了一个很难用有限的样本训练的重解码器网络。
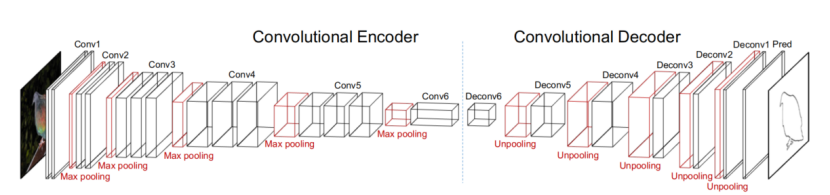
图 2. 提出的全卷积编解码器网络架构。
借鉴了上述两项工作的全卷积解调思想,一个用于对象轮廓检测的全卷积编解码器网络被提出。网络体系结构如图2所示。使用从VGG-16到“fc6”的层作为编码器。由于将“fc6”转换为卷积,所以在解码器中其命名为“conv6”。
由于图像标记问题(图像输入和掩码输出)的不对称性,本文打破了反卷积网络的对称结构,引入了一种轻加权解码器。第一层解码器“deconv6”是为降维而设计的,它将4096-d“conv6”投射到512-d,并带有1×1内核,这样我们就可以在下面的“deconv5”层中重复使用从“conv5”到功能映射的两次池化交换层。每个解码器层的通道数被适当地设计,以允许从其相应的最大池层进行反池化。除“deconv6”外,所有解码器卷积层都使用5×5核。除了输出标签旁边的解码器卷积层外,所有的解码器卷积层都遵循relu激活函数。我们相信我们的解码器的特征通道仍然是冗余的二进制标记在这里寻址,因此在每个relu层后也增加了一个dropout层。表1列出了一个完整的解码器网络设置,损失函数只是像素级逻辑损失。
| name |
deconv6 |
deconv5 |
deconv4 |
|
| setup kernel acti |
conv 1x1 x512 relu |
unpool-conv 5x 5 x512 relu |
unpool-conv 5x 5 x256 relu |
|
| name |
deconv3 |
deconv2 |
deconv1 |
pred |
| setup kernel activation |
unpool-conv 5x5 x128 relu |
unpool-conv 5x5x 64 relu |
unpool-conv 5 x5x 32 relu |
conv 5x 5 x 1 sigmoid |
-
- 轮廓ground truth精炼
绘制物体的详细和准确的轮廓是人类的一项具有挑战性的任务。这就是为什么许多大规模分割数据集提供多边形的轮廓注释,因为它们在规模上收集的成本较低。然而,由于注释者的行为不可预测而且多边形表示具有局限性,注释的轮廓通常与真实图像边界不能很好地对齐,因此不能直接用作训练的ground truth。其中,PASCAL VOC数据集是一个广泛接受的基准,具有高质量的对象分割注释。VOC2012版包括来自20个类别的11540幅图像,涵盖了来自“人”、“车辆”、“动物”和“家庭”等类别的大多数常见对象,其中1464幅和1449幅图像被标注为对象实例轮廓,用于训练和验证。Hariharan[19]进一步为剩余的图像贡献了超过10000个高质量的注释。总共有10582张用于训练的图像和1449张用于验证的图像。这个数据集可以用来训练对象轮廓检测器与提出的完全卷积编解码器网络。
原始的PASCALVOC注释在被遮挡的对象之间留下一个薄的未标记(或不确定)区域(图3(B))。为了找到高保真轮廓ground truth进行训练,需要将注释的轮廓与真实的图像边界对齐。文章认为轮廓对齐是一个多类标记问题,并引入了一个密集的CRF模型[26]其中每个实例(或背景)都被分配一个唯一的标签。然后,密集的CRF优化用相邻的实例标签填充不确定区域,以便我们在标记边界处获得细化的轮廓(图3(D))。对图形切割方法进行了实验[7]但发现由于其短切偏压,它通常会产生粗糙的轮廓(图3(C))。

(a) 图像 (b) 注释

(c) 图形切割 改进 (d) DenseCRF 改进
图 3. 轮廓改进。基于多边形的标注(a)不能直接用于训练,因为它的边界不准确(薄薄的白色区域反映物体之间未标记的像素)。我们用密集的CRF (d)重新标记不确定区域,并将其与图切(c)进行对比,使之与图像边界对齐。
3.3训练
使用Caffe训练网络。对于每个训练图像,随机裁剪四个224×224×3个patches,连同它们的镜像patches组成一个224×224×3×8的minibatch。ground truth轮廓掩模按相同方式处理。用预先训练的VGG-16网络初始化编码器,用随机值初始化解码器。在训练过程中,固定编码器参数,只优化解码器参数。这使得模型可以很容易地与其他解码器集成,例如边界框回归[17]和用于联合训练的语义分割[38]。由于“contowr”和“non-contowr”像素在每个小块中是非常不平衡的,因此“轮廓”的惩罚被设置为“non-contour”的惩罚的10倍。使用Adam方法[5]对网络参数进行优化,发现它比标准随机梯度下降更有效。学习率设为10e-4,并对网络进行30个epoch的训练,每个epoch都处理所有的训练图像。训练patch调整为224×224,以提高内存效率,并且学习到的参数可以用于任意大小的图像,因为它具有完全卷积的性质。
给定经过训练的模型,所有测试图像都通过CEDN网络以其原始大小进行前馈,以生成轮廓检测映射。通过F-measure(F)、固定轮廓阈值(ODS)、每个图像最佳阈值(OIS)和平均精度(AP)四个指标来评价检测精度。请注意,在评估之前,使用标准的非最大抑制来清理预测的轮廓图(细化轮廓)。
PASCAL Val2012。介绍PASCALVOC2012验证集的结果,与三个基准线、结构化边缘检测(SE)[12]、单尺度组合分组(SCG)和多尺度组合分组(MCG)[4]进行了比较。精度-召回曲线如图4所示。请注意,我们使用最初注释的轮廓,而不是我们的精炼轮廓作为基本真理,以进行无偏的评估。因此,我们认为细化的轮廓作为上限,因为我们的网络是从它们中学习的。它的精确回收值被称为“GT-Dense CRF”,图4中有一个绿色点。与基线相比,CEDN产生了非常高的精度,这意味着它生成了在视觉上更干净的轮廓图,背景杂波被很好地抑制(图5中的第三列)。CEDN也很好地恢复了来自同一类的两个实例之间的遮挡边界(图5中的第二个示例)。目前CEDN(F=0.57)和上限(F=0.74)之间仍然存在很大的性能差距,这需要进一步的研究来改进。

图 4. 用于轮廓检测的PASCAL VOC 2012验证集的PR曲线。

图 5. 在PASCAL VOC val2012上的示例结果。在从左到右的每一行中,我们给出(a)输入图像,(b) ground truth注释,(c)边缘检测,(d)我们的物体轮廓检测,(e)我们最好的物体提案。
带有微调的BSDS500。BSDS500[36]是轮廓检测的标准基准. 与我们的以对象为中心的目标不同,该数据集旨在评估自然边缘检测,不仅包括对象轮廓,还包括对象内部边界和背景边界(图6(B)中的示例)。它包括从多个用户收集的500张带有仔细注释边界的自然图像。数据集分为三个部分:200用于训练,100用于验证,其余200用于测试。首先研究CEDN模型在PAS-CALVOC上训练的效果如何推广到这个数据集中看不见的对象类别。其中有趣的是,如图6(C)所示,大多数野生动物轮廓,例如,大象和鱼、背景边界同时被准确地检测到,又例如,建筑物和山脉显然被压制。我们进一步微调我们的CEDN模型在BSDS500的200个训练图像上用很小学习率(10e-5 )训练一百个epoch。接下来,预先训练的CEDN模型(“CEDN-pretrain”)所抑制的边界从场景中出现。我们定量地评估了测试集上的预训练和微调模型,并与以前的方法进行了比较。图7显示:1)预先训练的CEDN模型由于其对象选择性的性质而产生了高精度但低的召回率;2)微调的CEDN模型与最先进的方法(HED)[47]实现了可比较的性能(F=0.79)。请注意,我们的模型并不是为BSDS500上的自然边缘检测而设计的,我们相信在HED[47]中使用的技术,如多尺度融合、精心设计的上采样层和数据增强可以进一步提高我们模型的性能。表2列出了更详细的比较。

图 6. 从左到右的每一行我们给出了(a)输入图像,(b) ground truth轮廓, (c)用预先训练好的CEDN进行轮廓检测,(d)用经过微调的CEDN进行轮廓检测。

图 7. 对PR曲线进行轮廓检测,对BSDS500进行设置。
|
|
ODS |
OIS |
AP |
| Human |
.80 |
.80 |
- |
| SCG [4] |
.739 |
.758 |
.773 |
| SE [12] |
.746 |
.767 |
.803 |
| DeepEdge [6] |
.753 |
.772 |
.807 |
| DeepContour [43] |
.756 |
.773 |
.797 |
| HED [47] |
.782 |
.804 |
.833 |
| .788 |
.808 |
.840 |
|
| CEDN-pretrain |
.610 |
.635 |
.580 |
| CEDN |
.788 |
.804 |
.821 |
对象提案是计算机视觉中重要的中级代表。大多数方案生成方法都建立在有效的轮廓检测和超像素分割的基础上。因此,轮廓检测的改进将立即提高对象提案的性能。我们选择MCG算法从我们检测到的轮廓中生成分段对象提案。MCG算法是基于经典的gPb轮廓检测器。它首先从多尺度计算超等高线图,然后将它们对齐为一个单一的层次分割。为了获得对象的提案,设计了一个多目标优化,以减少相邻区域组合分组的冗余。然后,将减少的分组候选人集根据其低级特征进行排序,作为最终的分段对象提案。请注意,分层分割可以直接从单尺度获得,这导致了一种快速的单尺度组合分组算法(SCG)。基于上述程序,我们只需将gPb替换为我们的CEDN轮廓检测器,以生成提案。多尺度和单尺度版本分别称为“CEDNMCG”和“CEDNSCG”。
我们通过两个度量来评估对象提案的质量:平均召回(AR)和平均最佳重叠(ABO)。这两种措施都是基于提案和ground truth掩码之间的重叠(Jaccard索引或Intersection-over-Union)。衡量AR的方法是:1)计算超过一定阈值T的最佳Jaccard对象的百分比,然后2)在阈值T在范围[0.5,1.0]内对它们进行平均。它是[21,39]建立的,以基准质量的边界框和分段对象提案。ABO是通过计算每个地面真实物体的最佳方案的Jaccard,然后对所有物体进行平均。
我们与最先进的算法进行了比较:MCG、SCG、类别独立对象提案(CI)[13]、约束参数MinCuts(CPMC)[9]、全局和局部搜索(GLS)[40]、大地测量对象提案(GOP)[27]、学习提出对象(LPO)[28]、图形切割中的回收推理(RI GOR)[22]、选择性搜索(选择)[46]和形状共享(Sh)[24]。


图 8. PASCAL VOC 2012验证集上的平均最佳重叠和平均回忆率。
PASCAL Val2012。图8显示,CEDNMCG实现了0.67AR和0.83ABO,每个图像的提案为1660,这提高了第二个最好的MCG8%的AR和3%的ABO与三分之一的提案。在高端GPU上计算PASCAL图像的CEDN等高线图需要0.1秒,在标准CPU上用MCG生成提案需要18秒。我们注意到CEDNSCG与CEDNMCG实现了类似的精度,但运行SCG只需不到3秒。我们还在图10中绘制了每个类AR,并发现CEDNMCG和CEDNSCG改善了所有20个类的MCG和SCG。值得注意的是,自行车类有最差的AR,我们猜测它很可能是因为它的注释不完整。图5(d)展示了一些对象提案的例子。

图 9. MS COCO val2014上的实例结果。在从左到右的每一行中,我们给出(a)输入图像,(b) ground truth注释,(c)边缘检测[12],(d)我们的物体轮廓检测,(e)我们最好的物体提案。
COCO Val2014。我们在MSCOCO2014验证集中给出了结果,其中包括来自80个对象类的由多边形注释的40504幅图像。由于对象类别、环境和尺度的巨大变化,该数据集更具价值性。与PASCALVOC相比,我们的CEDN轮廓检测器有60个看不见的对象类。请注意,我们没有在MS COCO数据集上对CEDN进行训练。图11报告了AR和ABO结果。结果表明,CEDNMCG实现了对MCG的竞争性AR,从较少的提案中召回略低,但ABO比LPO、MCG和SeSe弱。仔细查看结果,CEDNMCG算法仍然可以在已知对象(图9中的第一个和第三个示例)上执行良好的性能,但在某些未知对象类(如Food)上不那么有效(图9中的第二个示例)。这很可能是因为类别比较新,虽然在我们的训练集(PASCALVOC)中看到,实际上被注释为背景。例如,PASCAL VOC数据集中有一个“餐桌”类,但没有“食物”类。图12中给出了每类ARs,并有以下观察:
- CEDN在与PASCAL类(如“车辆”、“动物”和“家具”)共有的超级类上取得了良好的效果。
- CEDN未能检测到PASCAL VOC训练集中标记为“背景”的对象,如“食物”和“应用”。
- CEDN在PASCAL VOC训练中不常见且看不见的类别上效果很好,比如“体育”。
这些观察对COCO的训练有正面效果,但我们也观察到,MSCOCO中的多边形注释不如PASCALVOC中的多边形注释可靠(图9(B)中的第三个例子)。我们需要更复杂的方法来完善COCO注释。

图 10. PASCAL VOC 2012验证集上每个类的平均召回率。

图 11. MS COCO 2014验证集的平均最佳重叠和平均回忆率。

图 12. 在MS COCO 2014验证集上,每堂课的平均回忆率。


图 13. 与HED在PASCAL val2012上的完全比较。
我们实现了一种以对象为中心的轮廓检测方法,使用了一个简单而有效的全卷积编解码网络。考虑到多边形的轮廓注释不完善,我们实现了一种基于密集CRF的细化方法,从而对所提出的网络进行了端到端的训练。因此,经过训练的模型在PASCALVOC和BSDS500上获得了较高的精度,并在微调后在BSDS500上取得了与最先进的性能相当的性能。我们将所提出的轮廓检测器与多尺度组合分组算法相结合,生成分段对象提案,这大大提高了PASCALVOC的最先进水平。我们还发现,所提出的模型很好地推广到已知超类别的看不见的对象类,并在没有重新训练网络的情况下在MSCOCO上显示了具有强竞争力的性能。