前言
在前面的两篇文章中分别介绍了Elasticsearch和head插件的安装部署:
Elasticsearch5.2.2 安装部署与常见启动报错解决
Elasticsearch head插件安装过程详解
在本篇文章,将结合具体的例子重点介绍Elasticsearch Java API的操作。
Elasticsearch的Java客户端非常强大;它可以建立一个嵌入式实例并在必要时运行管理任务。运行一个Java应用程序和Elasticsearch时,有两种操作模式可供使用。该应用程序可在Elasticsearch集群中扮演更加主动或更加被动的角色。在更加主动的情况下(称为Node Client),应用程序实例将从集群接收请求,确定哪个节点应处理该请求,就像正常节点所做的一样。(应用程序甚至可以托管索引和处理请求。)另一种模式称为Transport Client,它将所有请求都转发到另一个Elasticsearch节点,由后者来确定最终目标。
一、API基本操作
1、操作环境准备
- Elasticsearch和head插件已经安装部署好,并已经启动成功
- 创建Maven工程,导入以下依赖:
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>5.2.2</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>5.2.2</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.9.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
</dependencies>
- 等待依赖的jar包下载完成
- 在Maven工程的resources目录下新建一个文件log4j2.xml ,然后在该文件中下入以下配置信息:
<?xml version="1.0" encoding="UTF-8"?>
<Configuration>
<Appenders>
<Console name="STDOUT" target="SYSTEM_OUT">
<PatternLayout pattern="%d %-5p [%t] %C{2} (%F:%L) - %m%n"/>
</Console>
<RollingFile name="RollingFile" fileName="logs/strutslog1.log"
filePattern="logs/$${date:yyyy-MM}/app-%d{MM-dd-yyyy}-%i.log.gz">
<PatternLayout>
<Pattern>%d{MM-dd-yyyy} %p %c{1.} [%t] -%M-%L- %m%n</Pattern>
</PatternLayout>
<Policies>
<TimeBasedTriggeringPolicy />
<SizeBasedTriggeringPolicy size="1 KB"/>
</Policies>
<DefaultRolloverStrategy fileIndex="max" max="2"/>
</RollingFile>
</Appenders>
<Loggers>
<Logger name="com.opensymphony.xwork2" level="WAN"/>
<Logger name="org.apache.struts2" level="WAN"/>
<Root level="warn">
<AppenderRef ref="STDOUT"/>
</Root>
</Loggers>
</Configuration>
2、获取Transport Client
(1)ElasticSearch服务默认端口9300。
(2)Web管理平台端口9200。
private TransportClient client;
@SuppressWarnings("unchecked")
@Before
public void getClient() throws Exception {
// 1 设置连接的集群名称
Settings settings = Settings.builder().put("cluster.name", "my-application").build();
// 2 连接集群
client = new PreBuiltTransportClient(settings);
client.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("weekend110"), 9300));
// 3 打印集群名称
System.out.println(client.toString());
}
3、创建索引
1)源代码:
/**
* 创建索引
*/
@Test
public void createIndex_blog(){
// 1 创建索引
client.admin().indices().prepareCreate("blog1").get();
// 2 关闭连接
client.close();
}
2)查看结果: http://192.168.2.100:9200/blog1
{“blog1”:{“aliases”:{},“mappings”:{},“settings”:{“index”:{“creation_date”:“1594951875136”,“number_of_shards”:“5”,“number_of_replicas”:“1”,“uuid”:“MIoleYUIRf2pBhgycwdUcQ”,“version”:{“created”:“5020299”},“provided_name”:“blog1”}}}}
4、删除索引
1)源代码:
/**
* 删除索引
*/
@Test
public void deleteIndex(){
// 1 删除索引
client.admin().indices().prepareDelete("blog1").get();
// 2 关闭连接
client.close();
}
2)查看结果: http://192.168.2.100:9200/blog1
没有blog1索引了。
{“error”:{“root_cause”:[{“type”:“index_not_found_exception”,“reason”:“no such index”,“resource.type”:“index_or_alias”,“resource.id”:“blog1”,“index_uuid”:“na”,“index”:“blog1”}],“type”:“index_not_found_exception”,“reason”:“no such index”,“resource.type”:“index_or_alias”,“resource.id”:“blog1”,“index_uuid”:“na”,“index”:“blog1”},“status”:404}
5、新建文档(源数据json串)
当直接在ElasticSearch建立文档对象时,如果索引不存在的,默认会自动创建,映射采用默认方式。
ElasticSearch服务默认端口9300
Web管理平台端口9200
1)源代码:
/**
* 源数据为 json串
* @throws UnknownHostException
*/
@Test
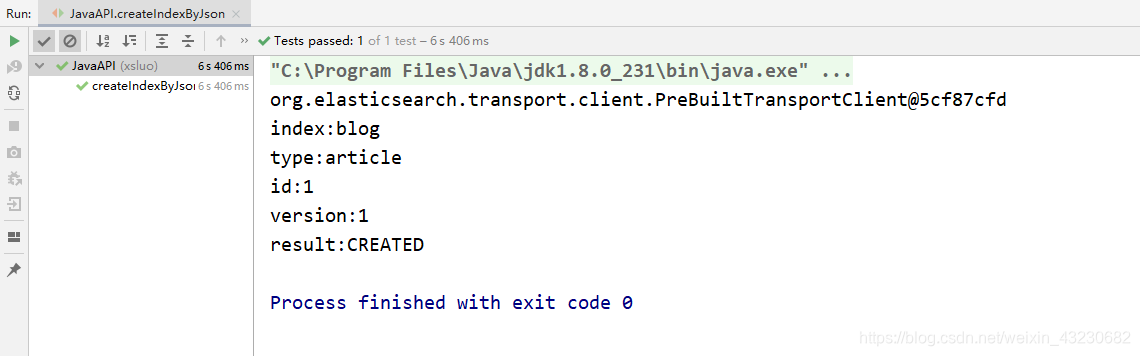
public void createIndexByJson() throws UnknownHostException {
// 1 文档数据准备
String json = "{" + "\"id\":\"1\"," + "\"title\":\"基于Lucene的搜索服务器\","
+ "\"content\":\"它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口\"" + "}";
// 2 创建文档
IndexResponse indexResponse = client.prepareIndex("blog", "article", "1").setSource(json).execute().actionGet();
// 3 打印返回的结果
System.out.println("index:" + indexResponse.getIndex());
System.out.println("type:" + indexResponse.getType());
System.out.println("id:" + indexResponse.getId());
System.out.println("version:" + indexResponse.getVersion());
System.out.println("result:" + indexResponse.getResult());
// 4 关闭连接
client.close();
}
2)查看结果:

6、新建文档(源数据map方式添加json)
1)源代码:
/**
* 源数据 Map方式添加json
*/
@Test
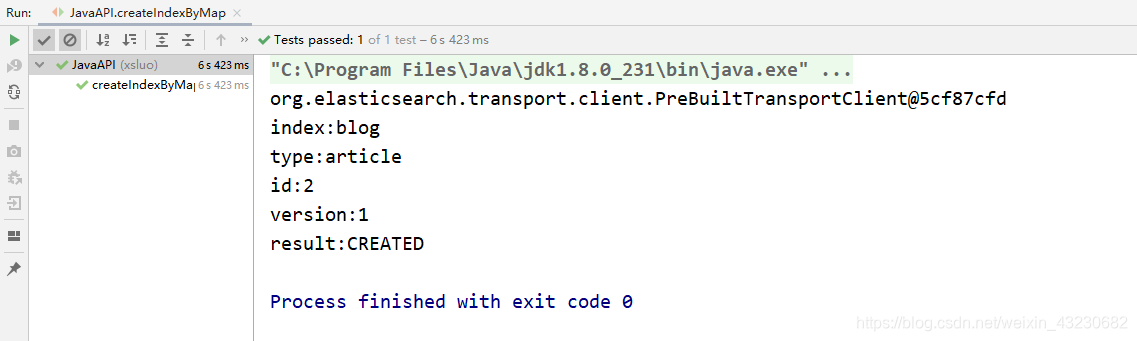
public void createIndexByMap() {
// 1 文档数据准备
Map<String, Object> map = new HashMap<String, Object>();
map.put("id", "2");
map.put("title", "基于Lucene的搜索服务器");
map.put("content", "它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口");
// 2 创建文档
IndexResponse indexResponse = client.prepareIndex("blog", "article", "2").setSource(map).execute().actionGet();
// 3 打印返回的结果
System.out.println("index:" + indexResponse.getIndex());
System.out.println("type:" + indexResponse.getType());
System.out.println("id:" + indexResponse.getId());
System.out.println("version:" + indexResponse.getVersion());
System.out.println("result:" + indexResponse.getResult());
// 4 关闭连接
client.close();
}
2)查看结果:
7、新建文档(源数据es构建器添加json)
1)源代码:
/**
* 源数据es构建器添加json
* @throws Exception
*/
@Test
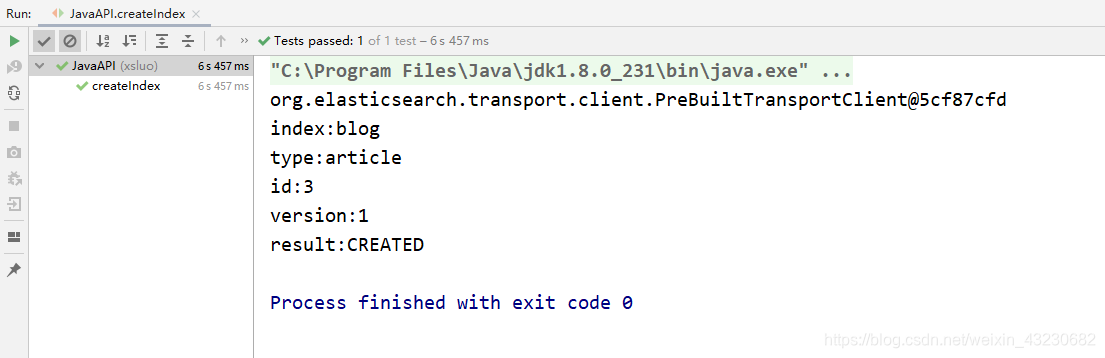
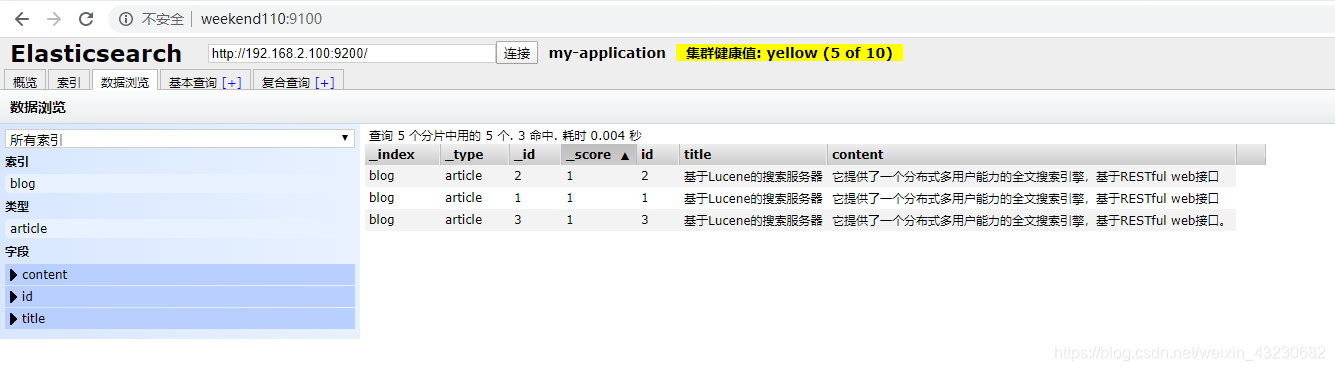
public void createIndex() throws Exception {
// 1 通过es自带的帮助类,构建json数据
XContentBuilder builder = XContentFactory.jsonBuilder().startObject()
.field("id", 3)
.field("title", "基于Lucene的搜索服务器")
.field("content", "它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。")
.endObject();
// 2 创建文档
IndexResponse indexResponse = client.prepareIndex("blog", "article", "3").setSource(builder).get();
// 3 打印返回的结果
System.out.println("index:" + indexResponse.getIndex());
System.out.println("type:" + indexResponse.getType());
System.out.println("id:" + indexResponse.getId());
System.out.println("version:" + indexResponse.getVersion());
System.out.println("result:" + indexResponse.getResult());
// 4 关闭连接
client.close();
}
2)查看结果:
8、搜索文档数据(单个索引)
1)源代码:
/**
* 搜索文档数据(单个索引)
* @throws Exception
*/
@Test
public void getData() throws Exception {
// 1 查询文档
GetResponse response = client.prepareGet("blog", "article", "1").get();
// 2 打印搜索的结果
System.out.println(response.getSourceAsString());
// 3 关闭连接
client.close();
}
2)查看结果:

9、搜索文档数据(多个索引)
1)源代码:
/**
* 搜索文档数据(多个索引)
*/
@Test
public void getMultiData() {
// 1 查询多个文档
MultiGetResponse response = client.prepareMultiGet()
.add("blog", "article", "1")
.add("blog", "article", "2", "3")
.add("blog", "article", "2")
.get();
// 2 遍历返回的结果
for(MultiGetItemResponse itemResponse:response){
GetResponse getResponse = itemResponse.getResponse();
// 如果获取到查询结果
if (getResponse.isExists()) {
String sourceAsString = getResponse.getSourceAsString();
System.out.println(sourceAsString);
}
}
// 3 关闭资源
client.close();
}
2)查看结果:

10、更新文档数据(update)
1)源代码:
/**
* 更新文档数据(update)
* @throws Throwable
*/
@Test
public void updateData() throws Throwable {
// 1 创建更新数据的请求对象
UpdateRequest updateRequest = new UpdateRequest();
updateRequest.index("blog");
updateRequest.type("article");
updateRequest.id("3");
updateRequest.doc(XContentFactory.jsonBuilder().startObject()
// 对没有的字段添加, 对已有的字段替换
.field("title", "基于Lucene的搜索服务器")
.field("content",
"它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。大数据前景无限")
.field("createDate", "2017-8-22")
.endObject());
// 2 获取更新后的值
UpdateResponse indexResponse = client.update(updateRequest).get();
// 3 打印返回的结果
System.out.println("index:" + indexResponse.getIndex());
System.out.println("type:" + indexResponse.getType());
System.out.println("id:" + indexResponse.getId());
System.out.println("version:" + indexResponse.getVersion());
System.out.println("create:" + indexResponse.getResult());
// 4 关闭连接
client.close();
}
2)查看结果:

11、更新文档数据(upsert)
设置查询条件, 查找不到则添加IndexRequest内容,查找到则按照UpdateRequest更新。
1)源代码:
/**
* 更新插入文档数据(upsert)
* @throws Exception
*/
@Test
public void testUpsert() throws Exception {
// 设置查询条件, 查找不到则添加
IndexRequest indexRequest = new IndexRequest("blog", "article", "5")
.source(XContentFactory
.jsonBuilder()
.startObject()
.field("title", "搜索服务器")
.field("content","它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。")
.endObject());
// 设置更新, 查找到更新下面的设置
UpdateRequest upsert = new UpdateRequest("blog", "article", "5")
.doc(XContentFactory
.jsonBuilder()
.startObject()
.field("user", "李四")
.endObject())
.upsert(indexRequest);
client.update(upsert).get();
client.close();
}
2)查看结果:
第一次执行

第二次执行

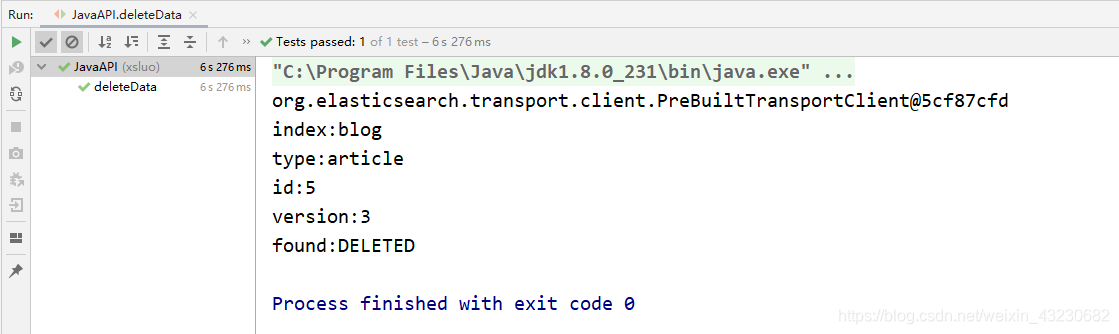
12、删除文档数据(prepareDelete)
1)源代码:
/**
* 删除文档数据(prepareDelete)
*/
@Test
public void deleteData() {
// 1 删除文档数据
DeleteResponse indexResponse = client.prepareDelete("blog", "article", "2").get();
// 2 打印返回的结果
System.out.println("index:" + indexResponse.getIndex());
System.out.println("type:" + indexResponse.getType());
System.out.println("id:" + indexResponse.getId());
System.out.println("version:" + indexResponse.getVersion());
System.out.println("found:" + indexResponse.getResult());
// 3 关闭连接
client.close();
}
2)查看结果:
二、条件查询QueryBuilders
1、查询所有(matchAllQuery)
1)源代码:
/**
* 条件查询 QueryBuilders:查询所有(matchAllQuery)
*/
@Test
public void matchAllQuery() {
// 1 执行查询
SearchResponse searchResponse = client.prepareSearch("blog").setTypes("article")
.setQuery(QueryBuilders.matchAllQuery()).get();
// 2 打印查询结果
SearchHits hits = searchResponse.getHits(); // 获取命中次数,查询结果有多少对象
System.out.println("查询结果有:" + hits.getTotalHits() + "条");
Iterator<SearchHit> iterator = hits.iterator();
while (iterator.hasNext()) {
SearchHit searchHit = iterator.next(); // 每个查询对象
System.out.println(searchHit.getSourceAsString()); // 获取字符串格式打印
}
// 3 关闭连接
client.close();
}
2)查看结果:

2、对所有字段分词查询(queryStringQuery)
1)源代码:
/**
* 条件查询 QueryBuilders:对所有字段分词查询(queryStringQuery)
*/
@Test
public void query() {
// 1 条件查询
SearchResponse searchResponse = client
.prepareSearch("blog")
.setTypes("article")
.setQuery(QueryBuilders.queryStringQuery("全文"))
.get();
// 2 打印查询结果
SearchHits hits = searchResponse.getHits(); // 获取命中次数,查询结果有多少对象
System.out.println("查询结果有:" + hits.getTotalHits() + "条");
Iterator<SearchHit> iterator = hits.iterator();
while (iterator.hasNext()) {
SearchHit searchHit = iterator.next(); // 每个查询对象
System.out.println(searchHit.getSourceAsString()); // 获取字符串格式打印
}
// 3 关闭连接
client.close();
}
2)查看结果:

3、通配符查询(wildcardQuery)
*表示多个字符(任意的字符)
?表示单个字符
1)源代码:
/**
* 条件查询 QueryBuilders:通配符查询(wildcardQuery)
*/
@Test
public void wildcardQuery() {
// 1 通配符查询
SearchResponse searchResponse = client
.prepareSearch("blog")
.setTypes("article")
.setQuery(QueryBuilders.wildcardQuery("content", "*景*"))
.get();
// 2 打印查询结果
SearchHits hits = searchResponse.getHits(); // 获取命中次数,查询结果有多少对象
System.out.println("查询结果有:" + hits.getTotalHits() + "条");
Iterator<SearchHit> iterator = hits.iterator();
while (iterator.hasNext()) {
SearchHit searchHit = iterator.next(); // 每个查询对象
System.out.println(searchHit.getSourceAsString()); // 获取字符串格式打印
}
// 3 关闭连接
client.close();
}
2)查看结果:

删除id为2的文档,下面测试词条查询。
4、词条查询(TermQuery)
1)源代码:
/**
* 条件查询 QueryBuilders:词条查询(TermQuery)
*/
@Test
public void termQuery() {
// 1 第一field查询
SearchResponse searchResponse = client
.prepareSearch("blog")
.setTypes("article")
.setQuery(QueryBuilders.termQuery("content", "全"))
.get();
// 2 打印查询结果
SearchHits hits = searchResponse.getHits(); // 获取命中次数,查询结果有多少对象
System.out.println("查询结果有:" + hits.getTotalHits() + "条");
Iterator<SearchHit> iterator = hits.iterator();
while (iterator.hasNext()) {
SearchHit searchHit = iterator.next(); // 每个查询对象
System.out.println(searchHit.getSourceAsString()); // 获取字符串格式打印
}
// 3 关闭连接
client.close();
}
2)查看结果:

5、模糊查询(fuzzy)
1)源代码:
/**
* 条件查询 QueryBuilders:模糊查询(fuzzy)
*/
@Test
public void fuzzy() {
// 1 模糊查询
SearchResponse searchResponse = client
.prepareSearch("blog")
.setTypes("article")
.setQuery(QueryBuilders.fuzzyQuery("title", "lucene"))
.get();
// 2 打印查询结果
SearchHits hits = searchResponse.getHits(); // 获取命中次数,查询结果有多少对象
System.out.println("查询结果有:" + hits.getTotalHits() + "条");
Iterator<SearchHit> iterator = hits.iterator();
while (iterator.hasNext()) {
SearchHit searchHit = iterator.next(); // 每个查询对象
System.out.println(searchHit.getSourceAsString()); // 获取字符串格式打印
}
// 3 关闭连接
client.close();
}
2)查看结果:

三、映射相关操作
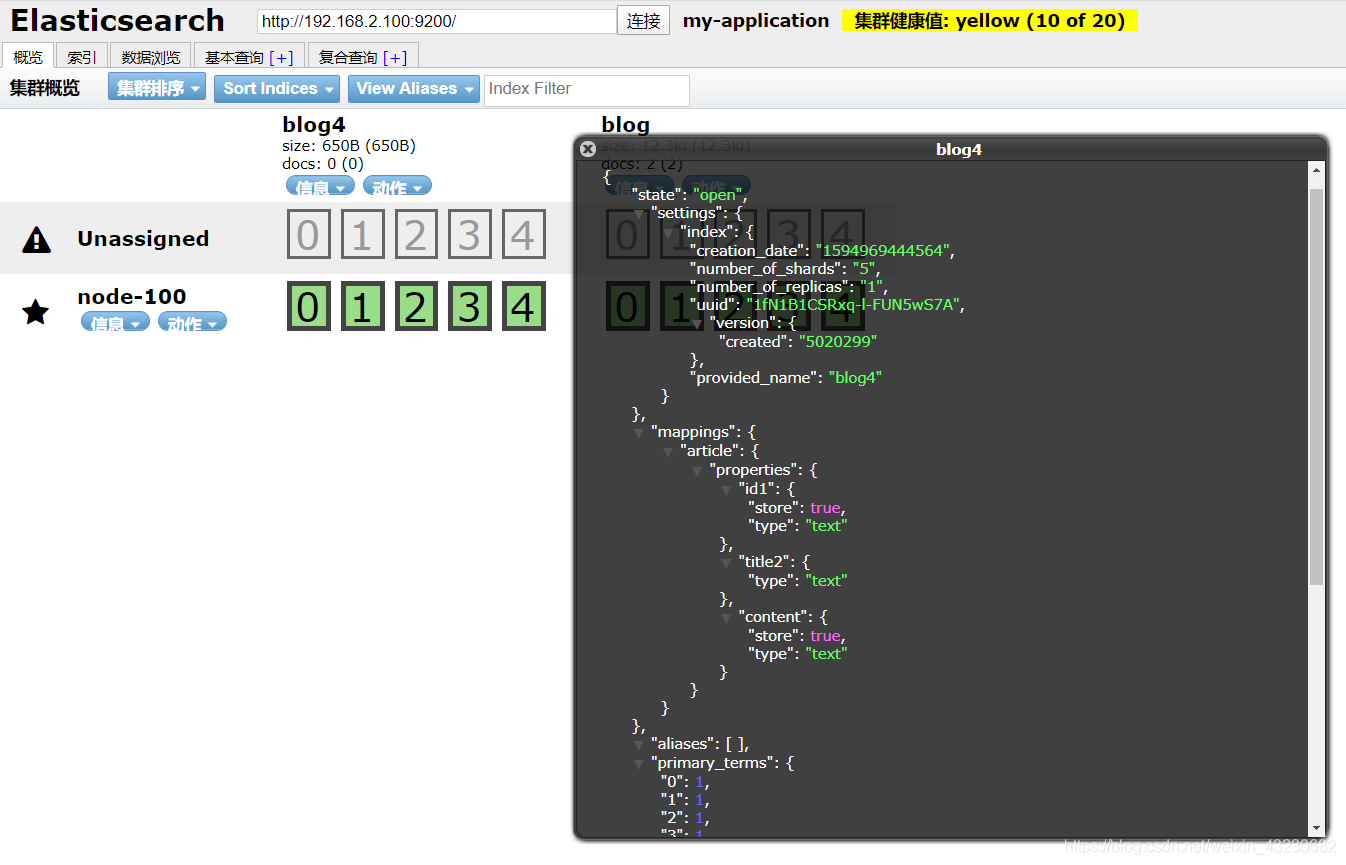
新建一个索引:blog4
然后为之创建mapping
1)源代码:
/**
* 映射相关操作
* @throws Exception
*/
@Test
public void createMapping() throws Exception {
// 1设置mapping
XContentBuilder builder = XContentFactory.jsonBuilder()
.startObject()
.startObject("article")
.startObject("properties")
.startObject("id1")
.field("type", "string")
.field("store", "yes")
.endObject()
.startObject("title2")
.field("type", "string")
.field("store", "no")
.endObject()
.startObject("content")
.field("type", "string")
.field("store", "yes")
.endObject()
.endObject()
.endObject()
.endObject();
// 2 添加mapping
PutMappingRequest mapping = Requests.putMappingRequest("blog4").type("article").source(builder);
client.admin().indices().putMapping(mapping).get();
// 3 关闭资源
client.close();
}
2)查看结果:
四、完整代码示例
package xsluo;
import org.elasticsearch.action.admin.indices.mapping.put.PutMappingRequest;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.get.MultiGetItemResponse;
import org.elasticsearch.action.get.MultiGetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.action.update.UpdateResponse;
import org.elasticsearch.client.Requests;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.common.xcontent.XContentBuilder;
import org.elasticsearch.common.xcontent.XContentFactory;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.transport.client.PreBuiltTransportClient;
import org.junit.Before;
import org.junit.Test;
import java.net.InetAddress;
import java.net.UnknownHostException;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
public class JavaAPI {
private TransportClient client;
@SuppressWarnings("unchecked")
@Before
public void getClient() throws Exception {
// 1 设置连接的集群名称
Settings settings = Settings.builder().put("cluster.name", "my-application").build();
// 2 连接集群
client = new PreBuiltTransportClient(settings);
client.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("weekend110"), 9300));
// 3 打印集群名称
System.out.println(client.toString());
}
/**
* 创建索引
*/
@Test
public void createIndex_blog(){
// 1 创建索引
client.admin().indices().prepareCreate("blog4").get();
// 2 关闭连接
client.close();
}
/**
* 删除索引
*/
@Test
public void deleteIndex(){
// 1 删除索引
client.admin().indices().prepareDelete("blog2").get();
// 2 关闭连接
client.close();
}
/**
* 源数据为 json串
* @throws UnknownHostException
*/
@Test
public void createIndexByJson() throws UnknownHostException {
// 1 文档数据准备
String json = "{" + "\"id\":\"1\"," + "\"title\":\"基于Lucene的搜索服务器\","
+ "\"content\":\"它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口\"" + "}";
// 2 创建文档
IndexResponse indexResponse = client.prepareIndex("blog", "article", "1").setSource(json).execute().actionGet();
// 3 打印返回的结果
System.out.println("index:" + indexResponse.getIndex());
System.out.println("type:" + indexResponse.getType());
System.out.println("id:" + indexResponse.getId());
System.out.println("version:" + indexResponse.getVersion());
System.out.println("result:" + indexResponse.getResult());
// 4 关闭连接
client.close();
}
/**
* 源数据 Map方式添加json
*/
@Test
public void createIndexByMap() {
// 1 文档数据准备
Map<String, Object> map = new HashMap<String, Object>();
map.put("id", "2");
map.put("title", "基于Lucene的搜索服务器");
map.put("content", "它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口");
// 2 创建文档
IndexResponse indexResponse = client.prepareIndex("blog", "article", "2").setSource(map).execute().actionGet();
// 3 打印返回的结果
System.out.println("index:" + indexResponse.getIndex());
System.out.println("type:" + indexResponse.getType());
System.out.println("id:" + indexResponse.getId());
System.out.println("version:" + indexResponse.getVersion());
System.out.println("result:" + indexResponse.getResult());
// 4 关闭连接
client.close();
}
/**
* 源数据es构建器添加json
* @throws Exception
*/
@Test
public void createIndex() throws Exception {
// 1 通过es自带的帮助类,构建json数据
XContentBuilder builder = XContentFactory.jsonBuilder().startObject()
.field("id", 3)
.field("title", "基于Lucene的搜索服务器")
.field("content", "它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。")
.endObject();
// 2 创建文档
IndexResponse indexResponse = client.prepareIndex("blog", "article", "3").setSource(builder).get();
// 3 打印返回的结果
System.out.println("index:" + indexResponse.getIndex());
System.out.println("type:" + indexResponse.getType());
System.out.println("id:" + indexResponse.getId());
System.out.println("version:" + indexResponse.getVersion());
System.out.println("result:" + indexResponse.getResult());
// 4 关闭连接
client.close();
}
/**
* 搜索文档数据(单个索引)
* @throws Exception
*/
@Test
public void getData() throws Exception {
// 1 查询文档
GetResponse response = client.prepareGet("blog", "article", "1").get();
// 2 打印搜索的结果
System.out.println(response.getSourceAsString());
// 3 关闭连接
client.close();
}
/**
* 搜索文档数据(多个索引)
*/
@Test
public void getMultiData() {
// 1 查询多个文档
MultiGetResponse response = client.prepareMultiGet()
.add("blog", "article", "1")
.add("blog", "article", "2", "3")
.add("blog", "article", "2")
.get();
// 2 遍历返回的结果
for(MultiGetItemResponse itemResponse:response){
GetResponse getResponse = itemResponse.getResponse();
// 如果获取到查询结果
if (getResponse.isExists()) {
String sourceAsString = getResponse.getSourceAsString();
System.out.println(sourceAsString);
}
}
// 3 关闭资源
client.close();
}
/**
* 更新文档数据(update)
* @throws Throwable
*/
@Test
public void updateData() throws Throwable {
// 1 创建更新数据的请求对象
UpdateRequest updateRequest = new UpdateRequest();
updateRequest.index("blog");
updateRequest.type("article");
updateRequest.id("3");
updateRequest.doc(XContentFactory.jsonBuilder().startObject()
// 对没有的字段添加, 对已有的字段替换
.field("title", "基于Lucene的搜索服务器")
.field("content",
"它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。大数据前景无限")
.field("createDate", "2017-8-22")
.endObject());
// 2 获取更新后的值
UpdateResponse indexResponse = client.update(updateRequest).get();
// 3 打印返回的结果
System.out.println("index:" + indexResponse.getIndex());
System.out.println("type:" + indexResponse.getType());
System.out.println("id:" + indexResponse.getId());
System.out.println("version:" + indexResponse.getVersion());
System.out.println("create:" + indexResponse.getResult());
// 4 关闭连接
client.close();
}
/**
* 更新插入文档数据(upsert)
* @throws Exception
*/
@Test
public void testUpsert() throws Exception {
// 设置查询条件, 查找不到则添加
IndexRequest indexRequest = new IndexRequest("blog", "article", "5")
.source(XContentFactory
.jsonBuilder()
.startObject()
.field("title", "搜索服务器")
.field("content","它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。")
.endObject());
// 设置更新, 查找到更新下面的设置
UpdateRequest upsert = new UpdateRequest("blog", "article", "5")
.doc(XContentFactory
.jsonBuilder()
.startObject()
.field("user", "李四")
.endObject())
.upsert(indexRequest);
client.update(upsert).get();
client.close();
}
/**
* 删除文档数据(prepareDelete)
*/
@Test
public void deleteData() {
// 1 删除文档数据
DeleteResponse indexResponse = client.prepareDelete("blog", "article", "2").get();
// 2 打印返回的结果
System.out.println("index:" + indexResponse.getIndex());
System.out.println("type:" + indexResponse.getType());
System.out.println("id:" + indexResponse.getId());
System.out.println("version:" + indexResponse.getVersion());
System.out.println("found:" + indexResponse.getResult());
// 3 关闭连接
client.close();
}
/**
* 条件查询 QueryBuilders:查询所有(matchAllQuery)
*/
@Test
public void matchAllQuery() {
// 1 执行查询
SearchResponse searchResponse = client.prepareSearch("blog").setTypes("article")
.setQuery(QueryBuilders.matchAllQuery()).get();
// 2 打印查询结果
SearchHits hits = searchResponse.getHits(); // 获取命中次数,查询结果有多少对象
System.out.println("查询结果有:" + hits.getTotalHits() + "条");
Iterator<SearchHit> iterator = hits.iterator();
while (iterator.hasNext()) {
SearchHit searchHit = iterator.next(); // 每个查询对象
System.out.println(searchHit.getSourceAsString()); // 获取字符串格式打印
}
// 3 关闭连接
client.close();
}
/**
* 条件查询 QueryBuilders:对所有字段分词查询(queryStringQuery)
*/
@Test
public void query() {
// 1 条件查询
SearchResponse searchResponse = client
.prepareSearch("blog")
.setTypes("article")
.setQuery(QueryBuilders.queryStringQuery("全文"))
.get();
// 2 打印查询结果
SearchHits hits = searchResponse.getHits(); // 获取命中次数,查询结果有多少对象
System.out.println("查询结果有:" + hits.getTotalHits() + "条");
Iterator<SearchHit> iterator = hits.iterator();
while (iterator.hasNext()) {
SearchHit searchHit = iterator.next(); // 每个查询对象
System.out.println(searchHit.getSourceAsString()); // 获取字符串格式打印
}
// 3 关闭连接
client.close();
}
/**
* 条件查询 QueryBuilders:通配符查询(wildcardQuery)
*/
@Test
public void wildcardQuery() {
// 1 通配符查询
SearchResponse searchResponse = client
.prepareSearch("blog")
.setTypes("article")
.setQuery(QueryBuilders.wildcardQuery("content", "*景*"))
.get();
// 2 打印查询结果
SearchHits hits = searchResponse.getHits(); // 获取命中次数,查询结果有多少对象
System.out.println("查询结果有:" + hits.getTotalHits() + "条");
Iterator<SearchHit> iterator = hits.iterator();
while (iterator.hasNext()) {
SearchHit searchHit = iterator.next(); // 每个查询对象
System.out.println(searchHit.getSourceAsString()); // 获取字符串格式打印
}
// 3 关闭连接
client.close();
}
/**
* 条件查询 QueryBuilders:词条查询(TermQuery)
*/
@Test
public void termQuery() {
// 1 第一field查询
SearchResponse searchResponse = client
.prepareSearch("blog")
.setTypes("article")
.setQuery(QueryBuilders.termQuery("content", "全"))
.get();
// 2 打印查询结果
SearchHits hits = searchResponse.getHits(); // 获取命中次数,查询结果有多少对象
System.out.println("查询结果有:" + hits.getTotalHits() + "条");
Iterator<SearchHit> iterator = hits.iterator();
while (iterator.hasNext()) {
SearchHit searchHit = iterator.next(); // 每个查询对象
System.out.println(searchHit.getSourceAsString()); // 获取字符串格式打印
}
// 3 关闭连接
client.close();
}
/**
* 条件查询 QueryBuilders:模糊查询(fuzzy)
*/
@Test
public void fuzzy() {
// 1 模糊查询
SearchResponse searchResponse = client
.prepareSearch("blog")
.setTypes("article")
.setQuery(QueryBuilders.fuzzyQuery("title", "lucene"))
.get();
// 2 打印查询结果
SearchHits hits = searchResponse.getHits(); // 获取命中次数,查询结果有多少对象
System.out.println("查询结果有:" + hits.getTotalHits() + "条");
Iterator<SearchHit> iterator = hits.iterator();
while (iterator.hasNext()) {
SearchHit searchHit = iterator.next(); // 每个查询对象
System.out.println(searchHit.getSourceAsString()); // 获取字符串格式打印
}
// 3 关闭连接
client.close();
}
/**
* 映射相关操作
* @throws Exception
*/
@Test
public void createMapping() throws Exception {
// 1设置mapping
XContentBuilder builder = XContentFactory.jsonBuilder()
.startObject()
.startObject("article")
.startObject("properties")
.startObject("id1")
.field("type", "string")
.field("store", "yes")
.endObject()
.startObject("title2")
.field("type", "string")
.field("store", "no")
.endObject()
.startObject("content")
.field("type", "string")
.field("store", "yes")
.endObject()
.endObject()
.endObject()
.endObject();
// 2 添加mapping
PutMappingRequest mapping = Requests.putMappingRequest("blog4").type("article").source(builder);
client.admin().indices().putMapping(mapping).get();
// 3 关闭资源
client.close();
}
}