SSE指令一次性能同时处理128位即16个字节型数据,8个short类型的,或者4个int类型数据(128=16×8=8×2×8=4×4×8)
一个字节=8位=255。
取反是对灰度图像取反,所以默认一个像素是一个字节,(如果是彩色24位的图像,24位=3个字节,(5×3+1)×8=128,128位包含5+1/3个像素信息,具体处理办法下篇文章再谈)。SSE代码部分能同时处理16个像素,从上到下,从左到右依次处理,每行余下的不能被16整除的像素则由C++代码进行处理。
以下分别是SSE代码和C++代码:
void IM_Invert_SSE(cv::Mat InImg, cv::Mat& OutImg)
{
unsigned char *Src= InImg.data;
unsigned char *Dst = OutImg.data;
int Width = InImg.cols;
int Height = InImg.rows;
const int BlockSize = 16;
int Block = Width / BlockSize;
for (int Y = 0; Y < Height; Y++)
{
unsigned char *LinePS = Src + Y * Width;
unsigned char *LinePD = Dst + Y * Width;
for (int X = 0; X < Block * BlockSize; X += BlockSize, LinePS += BlockSize, LinePD += BlockSize)
{
__m128i Src, Result;
Src = _mm_loadu_si128((__m128i *)(LinePS + 0));
Result = _mm_andnot_si128(Src, _mm_set1_epi8(255));
_mm_storeu_si128((__m128i*)(LinePD), Result);
}
for (int X = Block * BlockSize; X < Width; X++, LinePS ++, LinePD++)
{
LinePD[0] = 255- LinePS[0];
}
}
}
void IM_Invert(cv::Mat InImg, cv::Mat& OutImg)
{
unsigned char *Src = InImg.data;
unsigned char *Dst = OutImg.data;
int Width = InImg.cols;
int Height = InImg.rows;
const int BlockSize = 16;
int Block = Width / BlockSize;
for (int Y = 0; Y < Height; Y++)
{
unsigned char *LinePS = Src + Y * Width;
unsigned char *LinePD = Dst + Y * Width;
for (int X = 0; X < Width; X++, LinePS++, LinePD++)
{
LinePD[0] = 255 - LinePS[0];
}
}
}
这里选用犬子2160×2160的照片作为实验图像
原图:

灰度图这里就不放了(无意打开,有怪莫怪,但愿人没事,奠奠奠)。
灰度图二值化后:

取反后的图:

实验结果: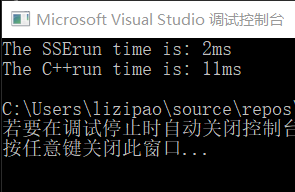
如图可见在64位debug模式下,SSE优化后,对于2160×2160的图,取反的速度比纯C++代码快了5倍多。