文章目录
Time 与 Window
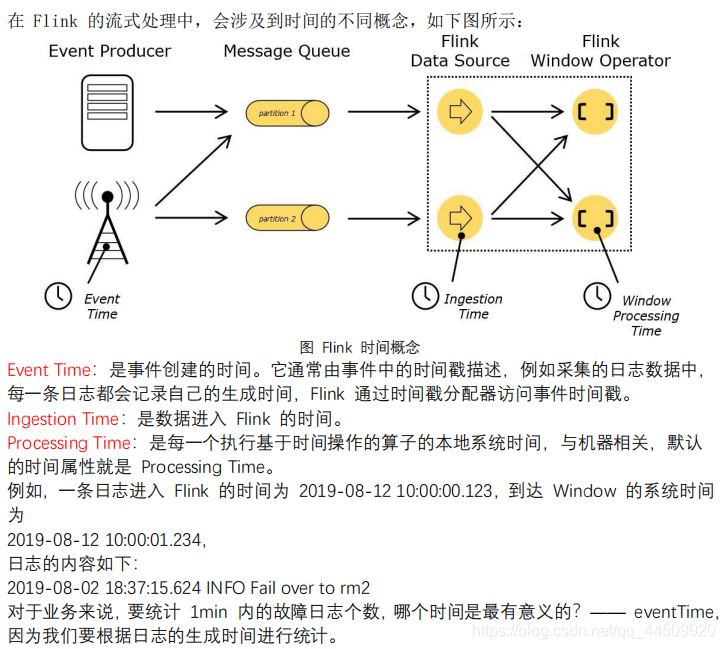
1. Time
2. Window
-
Window 概述
streaming 流式计算是一种被设计用于处理无限数据集的数据处理引擎,而无限数据集 是指一种不断增长的本质上无限的数据集,而 window 是一种切割无限数据为有限块进行处 理的手段。Window 是无限数据流处理的核心,Window 将一个无限的 stream 拆分成有限大 小的”buckets”桶,我们可以在这些桶上做计算操作。 -
Window 类型
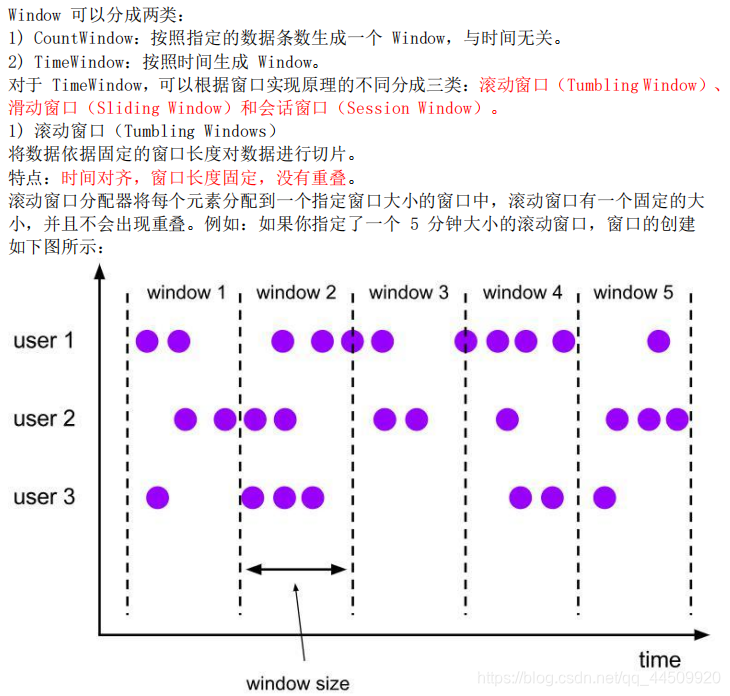

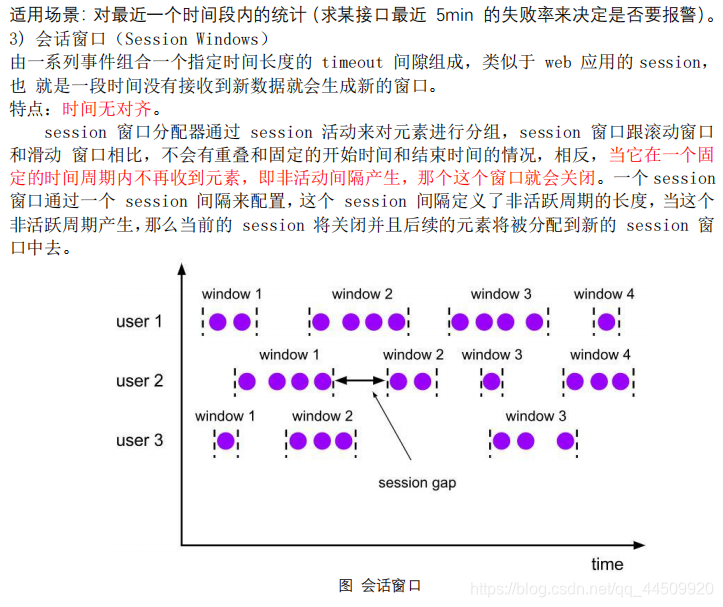
3. Window API
3.1CountWindow

参考代码
package com.czxy.flink.stream.window
import org.apache.flink.streaming.api.scala.{DataStream, KeyedStream, StreamExecutionEnvironment, WindowedStream}
import org.apache.flink.streaming.api.windowing.windows.GlobalWindow
/**
* 思路步骤:
* 1.获取执行环境
* 2.创建 SocketSource
* 3.对 stream 进行处理并按 key 聚合
* 4.countWindow 操作
* 5.执行聚合操作
* 6.将聚合数据输出
* 7.执行程序
*
* 集群输入 nc -lk 9999
*/
object StreamCountWindow {
def main(args: Array[String]): Unit = {
//1.创建执行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//2.构建数据源,创建 SocketSource
val socketSource: DataStream[String] = env.socketTextStream("node01",9999)
//3.对 stream 进行处理并按 key 聚合
import org.apache.flink.api.scala._
val groupKeyedStream: KeyedStream[(String, Int), String] = socketSource.flatMap(x=>x.split(" ")).map((_,1)).keyBy(_._1)
//4.引入countWindow 操作,每5条数据计算一次
val countWindowStream: WindowedStream[(String, Int), String, GlobalWindow] = groupKeyedStream.countWindow(5)
//5.执行聚合操作
val resultDataStream: DataStream[(String, Int)] = countWindowStream.sum(1)
//6.将聚合数据输出
resultDataStream.print()
//7.执行程序
env.execute("StreamCountWindow")
}
}
3.2 TimeWindow

参考代码
package com.czxy.flink.stream.window
import org.apache.flink.streaming.api.scala.{DataStream, KeyedStream, StreamExecutionEnvironment, WindowedStream}
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
/**
* 思路步骤:
* 1.获取执行环境
* 2.创建你 socket 链接获取数据
* 3.进行数据转换处理并按 key 聚合
* 4.引入 timeWindow
* 5.执行聚合操作
* 6.输出打印数据
* 7.执行程序
*/
object StreamTimeWindow {
def main(args: Array[String]): Unit = {
//1.获取执行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//2.创建你 socket 链接获取数据
val socketSource = env.socketTextStream("node01",9999)
//3.进行数据转换处理并按 key 聚合
import org.apache.flink.api.scala._
val groupKeyedStream: KeyedStream[(String, Int), String] = socketSource.flatMap(x=>x.split(" ")).map((_,1)).keyBy(_._1)
//4.引入 滚动窗口timeWindow,每3秒钟计算一次
val timeWindowStream: WindowedStream[(String, Int), String, TimeWindow] = groupKeyedStream.timeWindow(Time.seconds(3))
//4.引入 滑动窗口timeWindow,窗口大小为10秒,滑动距离为5秒=>重复消费
//val timeWindowStream: WindowedStream[(String, Int), String, TimeWindow] = groupKeyedStream.timeWindow(Time.seconds(10),Time.seconds(5))
//5.执行聚合操作
val result: DataStream[(String, Int)] = timeWindowStream.sum(1)
//6.打印输出
result.print()
//7.执行程序
env.execute("StreamTimeWindow")
}
}
3.3 Window Reduce
WindowedStream → DataStream:给 window 赋一个 reduce 功能的函数,并返回一个聚合 的结果。
参考代码
package com.czxy.flink.stream.window
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment, WindowedStream}
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
object StreamReduceWindow {
def main(args: Array[String]): Unit = {
//1.获取执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.构建数据集
val socketSource = env.socketTextStream("node01",9999)
//3.分组
import org.apache.flink.api.scala._
val group = socketSource.flatMap(x=>x.split(" ")).map((_,1)).keyBy(_._1)
//4.引入窗口timeWindow
val timeWindow: WindowedStream[(String, Int), String, TimeWindow] = group.timeWindow(Time.seconds(5))
//5.聚合操作
val result: DataStream[(String, Int)] = timeWindow.reduce((v1, v2)=>(v1._1,v1._2+v2._2))
//6.输出打印
result.print()
//7.执行程序
env.execute()
}
}
3.4 Window Apply

参考代码
package com.czxy.flink.stream.window
import org.apache.flink.streaming.api.scala.function.RichWindowFunction
import org.apache.flink.streaming.api.scala.{DataStream, KeyedStream, StreamExecutionEnvironment, WindowedStream}
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
import org.apache.flink.api.scala._
//使用 apply 方法来实现单词统计
object StreamApplyWindow {
def main(args: Array[String]): Unit = {
/**
* 思路步骤:
* 1) 获取流处理运行环境
* 2) 构建 socket 流数据源, 并指定 IP 地址和端口号
* 3) 对接收到的数据转换成单词元组
* 4) 使用 keyBy 进行分流( 分组)
* 5) 使用 timeWindow 指定窗口的长度( 每 3 秒计算一次)
* 6) 实现一个 WindowFunction 匿名内部类
* a. apply 方法中实现聚合计算
* b. 使用 Collector.collect 收集数据
* 7) 打印输出
* 8) 启动执行
* 9) 在 Linux 中, 使用 nc -lk 端口号 监听端口, 并发送单词
*/
//1.获取流处理运行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//2. 构建 socket 流数据源, 并指定 IP 地址和端口号
val socketSource: DataStream[String] = env.socketTextStream("node01",9999)
//3.对接收到的数据转换成单词元组
val wordAndOne: DataStream[(String, Int)] = socketSource.flatMap(x=>x.split(" ")).map((_,1))
//4.使用 keyBy 进行分流( 分组)
val groupKeyedStream: KeyedStream[(String, Int), String] = wordAndOne.keyBy(_._1)
//5.使用 timeWindow 指定窗口的长度( 每 3 秒计算一次)
val timeWindow: WindowedStream[(String, Int), String, TimeWindow] = groupKeyedStream.timeWindow(Time.seconds(3))
//6.实现一个 WindowFunction 匿名内部类
val result: DataStream[(String, Int)] = timeWindow.apply(new RichWindowFunction[(String, Int), (String, Int), String, TimeWindow] {
override def apply(key: String, window: TimeWindow, input: Iterable[(String, Int)], out: Collector[(String, Int)]): Unit = {
//apply 方法中实现聚合计算
val tuple: (String, Int) = input.reduce((v1, v2) => (v1._1, v1._2 + v2._2))
//使用 Collector.collect 收集数据
out.collect(tuple)
}
})
//7.打印输出
result.print()
//8.执行程序
env.execute("StreamApplyWindow")
}
}
3.5 Window Fold
WindowedStream → DataStream:给窗口赋一个 fold 功能的函数,并返回一个 fold 后的 结果。
参考代码
package com.czxy.flink.stream.window
import org.apache.flink.streaming.api.scala.{DataStream, KeyedStream, StreamExecutionEnvironment, WindowedStream}
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
object StreamFoldWindow {
def main(args: Array[String]): Unit = {
// 1获取执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 2创建 SocketSource
val stream = env.socketTextStream("node01", 9999)
// 3对 stream 进行处理并按 key 聚合
val streamKeyBy: KeyedStream[(String, Int), String] = stream.flatMap(x => x.split(" ")).map((_, 1)).keyBy(_._1)
// 4引入滚动窗口,每3秒计算一次
val timeWindow: WindowedStream[(String, Int), String, TimeWindow] = streamKeyBy.timeWindow(Time.seconds(3))
// 5执行 fold 操作
val result: DataStream[Int] = timeWindow.fold(100) {
(begin, item) => begin + item._2
}
//6将聚合数据写入文件
result.print()
//7执行程序
env.execute("StreamFoldWindow")
}
}
3.6 Aggregation on Window
WindowedStream → DataStream:对一个 window 内的所有元素做聚合操作。min 和 minBy 的区别是 min 返回的是最小值,而 minBy 返回的是包含最小值字段的元素(同样的原理适 用于 max 和 maxBy)。
参考代码
package com.czxy.flink.stream.window
import org.apache.flink.streaming.api.scala.{DataStream, KeyedStream, StreamExecutionEnvironment, WindowedStream}
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.api.scala._
object StreamAggregationWindow {
def main(args: Array[String]): Unit = {
//1.获取流处理运行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//2. 构建 socket 流数据源, 并指定 IP 地址和端口号
val socketSource: DataStream[String] = env.socketTextStream("node01",9999)
//3.对接收到的数据转换成单词元组
val wordAndOne: DataStream[(String, Int)] = socketSource.flatMap(x=>x.split(" ")).map((_,1))
//4.使用 keyBy 进行分流( 分组)
val groupKeyedStream: KeyedStream[(String, Int), String] = wordAndOne.keyBy(_._1)
//5.使用 timeWindow 指定窗口的长度( 每 3 秒计算一次)
val timeWindow: WindowedStream[(String, Int), String, TimeWindow] = groupKeyedStream.timeWindow(Time.seconds(3))
//6.执行聚合操作
val result: DataStream[(String, Int)] = timeWindow.max(1)
//7.打印输出
result.print()
//8.执行程序
env.execute(this.getClass.getSimpleName)
}
}