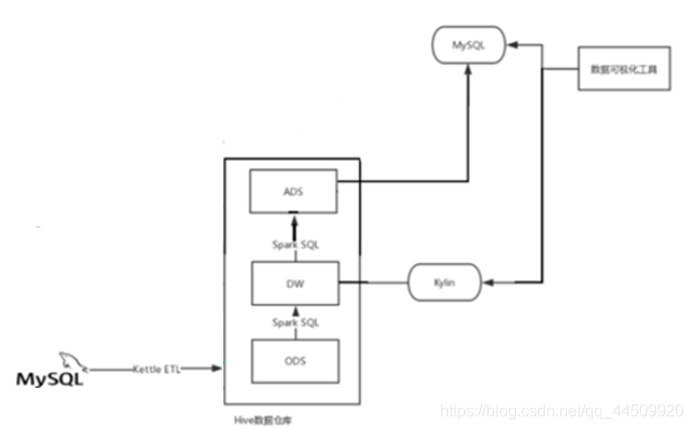
项目流程
-
1、原始数据在mysql存储
-
2、使用kettle将数据在mysql同步到数据仓库(hive),同步分为全量同步+增量同步=拉链表(目标:既能够保存历史的数据,又不会有数据冗余)
-
3、数据存储到Hive,
Hive内部结构:
ODS: 存储在数据源同步过来的数据
DW:对ODS存储的数据进行过滤、填充,预计算,以及数据的拉宽。(拉宽:就是将业务上需要的字段,但是字段不在一个表中,使用拉宽(join)将这些字段合并到一个表中)
ADS:存储最终计算后的结果 -
4、使用kylin对hive中的结果数据查询进行加速。(kylin对数据进行预计算)
-
5、使用kettle,Sqoop将计算结果同步到mysql
技术选型
- 数据来源:mysql
- 同步数据:kettle
- 数据存储:hive
- 计算模型(数仓): ODS 层,DW层,ADS 层
- 计算完毕的结构数据存储到哪?
结果存储: Hive的ads和Mysql - 加速查询的组件: Kylin
数据存储
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能(HQL)。其本质是将SQL转换为MapReduce的任务进行运算,底层由HDFS来提供数据的存储,hive可以理解为一个将SQL转换为MapReduce的任务的工具。
使用Hive的好处:
√ 操作接口采用类SQL语法,提供快速开发的能力。
√ 避免了去写MapReduce,减少开发人员的学习成本。
√ 功能扩展很方便。
Hive与传统RDBMS的对比
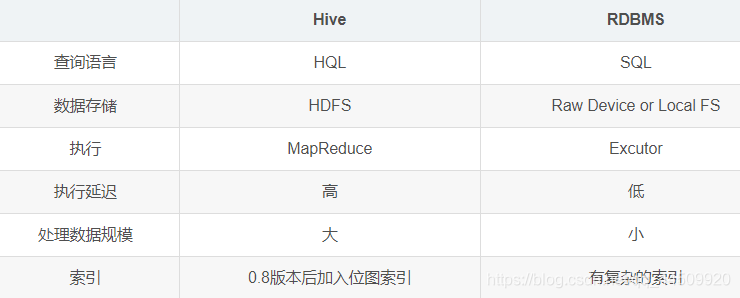
总结:
hive具有sql数据库的外表,但应用场景完全不同
hive只适合用来做批量数据统计分析
数据同步
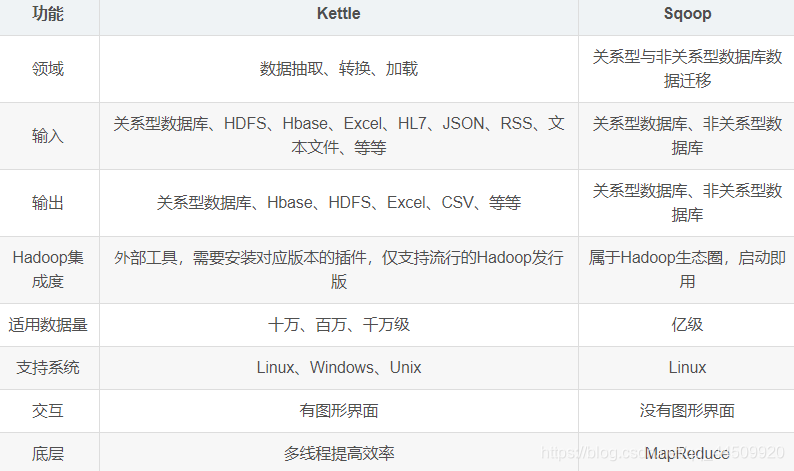
Kettle与Sqoop同步差异对比的表格
计算模型
每个企业根据自己的业务需求可以分成不同的层次,但是最基础的分层思想,理论上数据分为三个层,数据运营层、数据仓库层和数据服务层。基于这个基础分层之上添加新的层次,来满足不同的业务需求。
数仓分层通过数据分层管控数据质量,需要对数据清洗等操作,不必改一次业务就需要重新接入数据,每一层数据都是单独的作用,同时规范数据分层,减少业务开发、直接抽取数据。
其中
数据运营层ODS存储着数据源同步过来的数据
数据仓库层DW需要对ODS层数据进行预处理(数据过滤,数据填充)
数据服务层存储最终结果
结果存储
通过上面的分析,在Hive中ADS层负责存储着结果数据,可以根据用户需求,利用简易sql而查询出最终结果。
而数据源来自MySQL,我们自然也可以选择将结果存储至MySQL当中。数据同步组件根据实际情况选择Kettle或者Sqoop。
kylin加速查询
✔ 可扩展的超快的 OLAP 引擎
✔ 提供 ANSI-SQL 接口
✔ 交互式查询能力
✔ MOLAP Cube 的概念
✔ 与 BI 工具可无缝整合
Kylin 的核心思想是利用空间换时间,在数据 ETL 导入 OLAP 引擎时提前计算各维度的聚合结果并持久化保存。