生产者发送消息流程
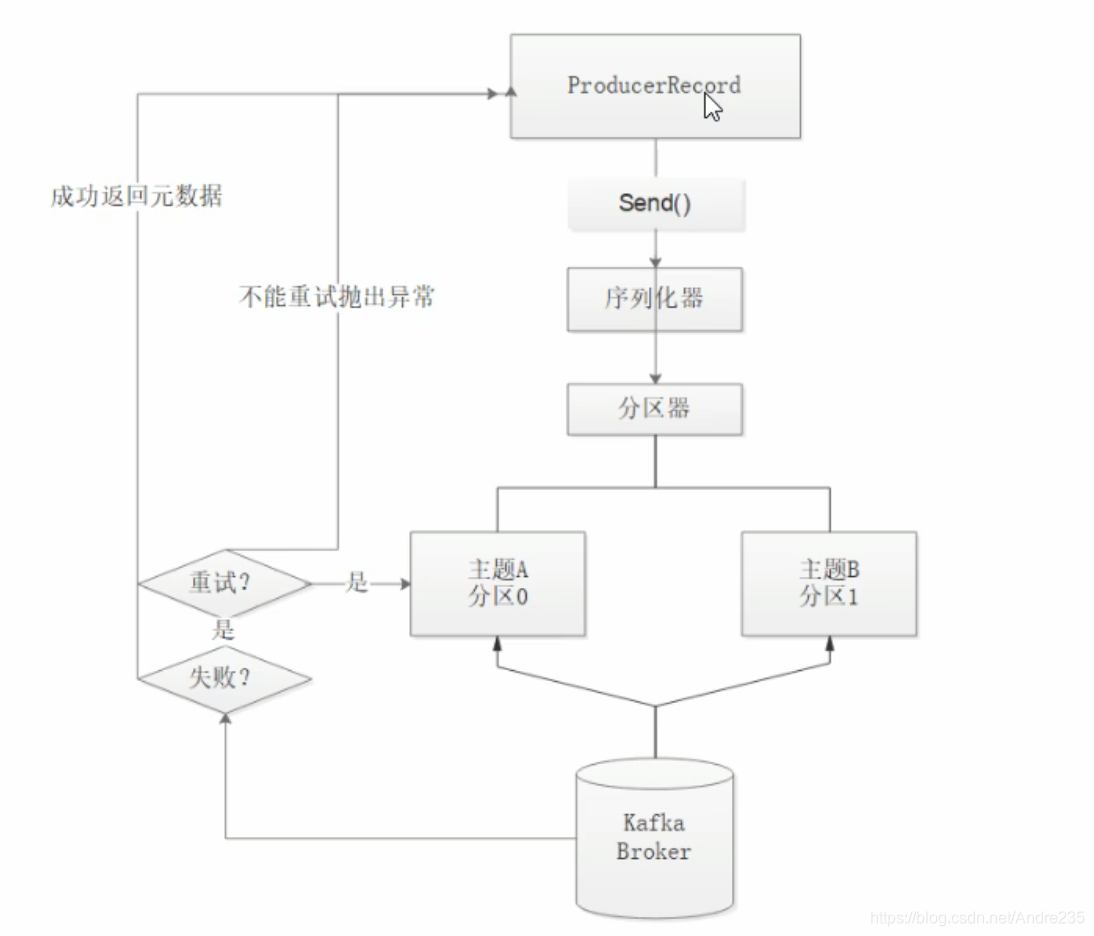
发送消息类型
-
同步发送
//同步发送消息 //通过send()方法发送完一个消息后返回一个Future,然后调用Future对象的get()方法等待Kafka响应 Future<RecordMetadata> future = producer.send(record); //如果Kafka正常响应,返回一个RecordMetadata记录元数据对象,该对象存储的是记录的偏移量 //如果Kafka没有正常响应则会抛出异常 RecordMetadata recordMetadata = future.get(); String topic = recordMetadata.topic(); log.info("topic:{}",topic); int partition = recordMetadata.partition(); log.info("分区:{}",partition); long offset = recordMetadata.offset(); log.info("消息偏移量:{}",offset); producer.close(); -
异步发送
//异步发送消息,重新起了一个线程,当Kafka收到消息后会进行异步回调 producer.send(record, new Callback() { @Override public void onCompletion(RecordMetadata metadata, Exception exception) { if(exception == null){ String topic = recordMetadata.topic(); log.info("topic:{}",topic); int partition = recordMetadata.partition(); log.info("分区:{}",partition); long offset = recordMetadata.offset(); log.info("消息偏移量:{}",offset); } } });
序列化器
生产者发送消息必须先通过序列化器进行序列化后才可以在网络上进行传输,消费者从网络上接收到消息后需要先经过反序列化。
Kafka提供的序列化器类型:
- 字符串型序列化器
- 整型序列化器
- 字节数组序列化器
自定义序列化器
分区器
Kafka本身有自己的分区策略,如果没有指定,则Kafka使用默认的分区策略
默认分区策略:Kafka根据消息的key进行分区的分配,即hash(key) % numPartitions,如果值相同,则被分配到同一个分区。
自定义分区器
拦截器
概念: Producer拦截器和Consumer拦截器是主要用于实现客户端定制化业务逻辑。拦截器可以在消息发送或者接受之前做一下定制工作,类比设计模式中的代理模式。
使用场景:
- 按照某个规则过滤掉不符合要求的消息
- 修改消息内容
- 对消息进行统计
- 等等
自定义拦截器:
@Slf4j
public class MyProducerInterceptor implements ProducerInterceptor<String,String> {
private static volatile long sendSuccessCount = 0L;
private static volatile long sendFailCount = 0L;
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
//获取消息
String value = "prefix" + record.value();
return new ProducerRecord<>(record.topic(), record.partition(), record.timestamp(), record.key(), value, record.headers());
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
if(exception == null){
sendSuccessCount ++;
}else {
sendFailCount ++;
}
}
@Override
public void close() {
double rate = (double) sendSuccessCount / (sendSuccessCount + sendFailCount);
String radio = String.format("%f",rate * 100) + "%" ;
log.info("消息发送成功率:{}",radio);
}
@Override
public void configure(Map<java.lang.String, ?> configs) {
}
}
其他生产者参数
-
acks
这个参数用来指定分区中必须有多少个副本收到这条消息,之后生产者才会认为这条消息时写入成功 的。acks是生产者客户端中非常重要的一个参数,它涉及到消息的可靠性和吞吐量之间的权衡
- ack=0, 生产者在成功写入消息之前不会等待任何来自服务器的响应。如果出现问题生产者是感知 不到的,消息就丢失了。不过因为生产者不需要等待服务器响应,所以它可以以网络能够支持的最 大速度发送消息,从而达到很高的吞吐量
- ack=1,默认值为1,只要集群的首领节点收到消息,生产这就会收到一个来自服务器的成功响 应。如果消息无法达到首领节点(比如首领节点崩溃,新的首领还没有被选举出来),生产者会收 到一个错误响应,为了避免数据丢失,生产者会重发消息。但是,这样还有可能会导致数据丢失, 如果收到写成功通知,此时首领节点还没来的及同步数据到follower节点,首领节点崩溃,就会导 致数据丢失
- ack=-1, 只有当所有参与复制的节点都收到消息时,生产这会收到一个来自服务器的成功响应, 这种模式是最安全的,它可以保证不止一个服务器收到消息
注意:acks参数配置的是一个字符串类型,而不是整数类型,如果配置为整数类型会抛出异常
-
retries
生产者从服务器收到的错误有可能是临时性的错误(比如分区找不到首领)。在这种情况下,如果达到 了 retires 设置的次数,生产者会放弃重试并返回错误。默认情况下,生产者会在每次重试之间等待 100ms,可以通过 retry.backoff.ms 参数来修改这个时间间隔
-
batch.size
当有多个消息要被发送到同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可 以使用的内存大小,按照字节数计算,而不是消息个数。当批次被填满,批次里的所有消息会被发送出 去。不过生产者并不一定都会等到批次被填满才发送,半满的批次,甚至只包含一个消息的批次也可能 被发送。所以就算把 batch.size 设置的很大,也不会造成延迟,只会占用更多的内存而已,如果设置 的太小,生产者会因为频繁发送消息而增加一些额外的开销
-
该参数用于控制生产者发送的请求大小,它可以指定能发送的单个消息的最大值,也可以指单个请求里 所有消息的总大小。 broker 对可接收的消息最大值也有自己的限制( message.max.size ),所以两 边的配置最好匹配,避免生产者发送的消息被 broker 拒绝