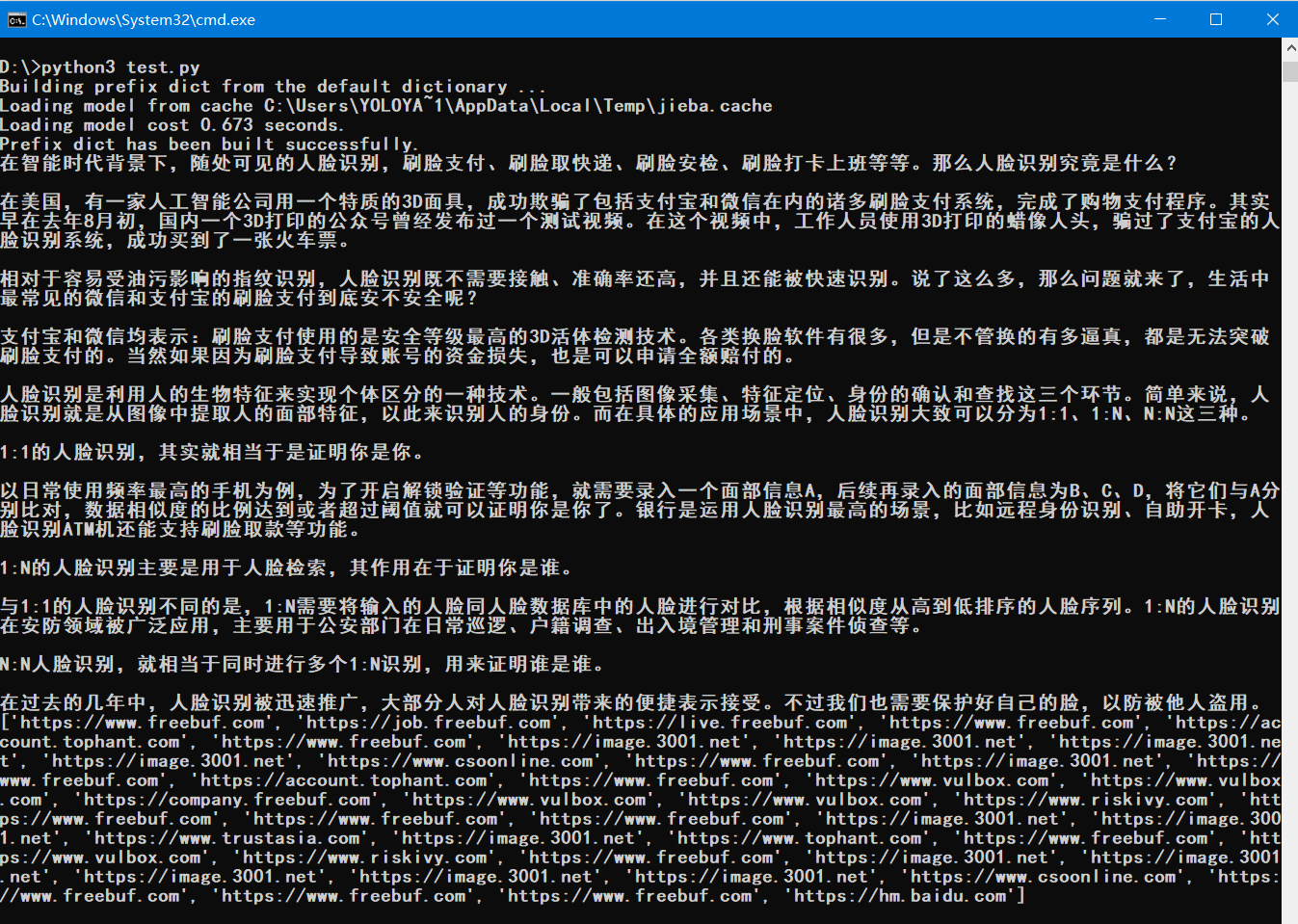
一个HTML文件,找出里面的正文和链接
代码
#coding: utf-8
from goose3 import Goose
from goose3.text import StopWordsChinese
import requests
from bs4 import BeautifulSoup
import re
# 要分析的网页url
url = 'https://www.freebuf.com/articles/network/244577.html'
# 提取正文
def extract(url):
g = Goose({'stopwords_class': StopWordsChinese})
article = g.extract(url=url)
return article.cleaned_text
# 提取url
def get_url(url):
html = requests.get(url)
urls = re.findall('http[s]://(?:[-\w.]|(?:%[\da-fA-F]{2}))+',html.text)
return urls
if __name__ == '__main__':
print(extract(url))
print(get_url(url))
提取结果