不同的引擎对于索引有不同的支持:Innodb和MyISAM默认的索引是Btree索引;而Mermory默认的索引是Hash索引。
我们在mysql中常用两种索引算法BTree和Hash,两种算法检索方式不一样,对查询的作用也不一样。
区别:
哈希索引适合等值查询,但是无法进行范围查询
哈希索引没办法利用索引完成排序
哈希索引不支持多列联合索引的最左匹配规则
如果有大量重复键值的情况下,哈希索引的效率会很低,因为存在哈希碰撞问题
详解
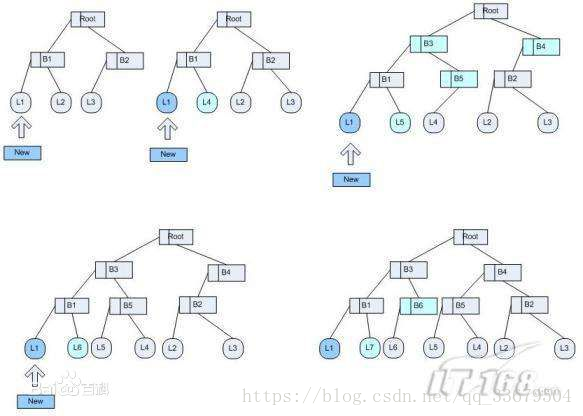
一、BTree
BTree索引是最常用的mysql数据库索引算法,因为它不仅可以被用在=,>,>=,<,<=和between这些比较操作符上,而且还可以用于like操作符,
只要它的查询条件是一个不以通配符开头的常量,例如:
select * from user where name like ‘jack%’;
select * from user where name like ‘jac%k%’;
如果一通配符开头,或者没有使用常量,则不会使用索引,例如:
select * from user where name like ‘%jack’;
select * from user where name like simply_name;
二、Hash
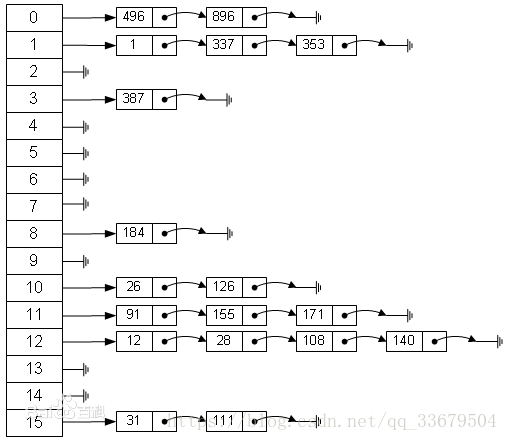
Hash索引只能用于对等比较,例如=,<=>(相当于=)操作符。由于是一次定位数据,不像BTree索引需要从根节点到枝节点,最后才能访问到页节点这样多次IO访问,所以检索效率远高于BTree索引。
但为什么我们使用BTree比使用Hash多呢?主要Hash本身由于其特殊性,也带来了很多限制和弊端:
1 Hash索引仅仅能满足“=”,“IN”,“<=>”查询,不能使用范围查询。 2 联合索引中,Hash索引不能利用部分索引键查询。 3 对于联合索引中的多个列,Hash是要么全部使用,要么全部不使用,并不支持BTree支持的联合索引的最优前缀,也就是联合索引的前面一个或几个索引键进行查询时,Hash索引无法被利用。 4 Hash索引无法避免数据的排序操作 5 Hash索引是将索引键通过Hash运算之后,将Hash运算结果的Hash值和所对应的行指针信息存放于一个Hash表中,由于不同索引键存在相同Hash值,所以即使满足某个Hash键值的数据的记录条数,
也无法从Hash索引中直接完成查询,还是要通过访问表中的实际数据进行比较,并得到相应的结果。 Hash索引遇到大量Hash值相等(hash碰撞)的情况后性能并不一定会比BTree高 6 对于选择性比较低的索引键,如果创建Hash索引,那么将会存在大量记录指针信息存于同一个Hash值相关联。这样要定位某一条记录时就会非常麻烦,会浪费多次表数据访问,而造成整体性能底下。
1. hash索引查找数据基本上能一次定位数据,当然有大量hash碰撞的话性能也会下降。而btree索引就得在节点上挨着查找了,很明显在数据精确查找方面hash索引的效率是要高于btree的;
2. 那么不精确查找呢,也很明显,因为hash算法是基于等值计算的,所以对于“like”等范围查找hash索引无效,不支持;所以这时候就只能全表扫描去查了
3. 对于btree支持的联合索引的最优前缀,hash也是无法支持的,联合索引中的字段要么全用要么全不用。
最左前缀匹配?
在创建多列索引时,我们根据业务需求,where子句中使用最频繁的一列放在最左边,因为MySQL索引查询会遵循最左前缀匹配的原则,即最左优先,在检索数据时从联合索引的最左边开始匹配。所以当我们创建一个联合索引的时候,如(key1,key2,key3),相当于创建了(key1)、(key1,key2)和(key1,key2,key3)三个索引,这就是最左匹配原则
一张表格说明白差异
| 索引名 | hash | Btree |
| 支持最左前缀匹配原则? | 不支持,只有索引的全部字段都用上才会匹配到 | 支持,用上索引的第一个字段就可以匹配索引 |
| MyISAM和InnoDB是否支持? | 不支持(只有Memory和NDB引擎索引支持) | 支持 |
| 范围查询能否命中索引? | 不可以,只有“=”,“IN”,“<=>”(等价于的意思)查询能命中 | 可以 |
| 一定会全表扫描吗? | 是(这儿没理解,为啥全表扫描了) | 否 |
| 数据结构 | hash表,通过键去找值的一种数据结构,hash碰撞的数据放到链表里
|
B-tree,多路搜索树,并不是二叉的
|