正则表达式
正则表达式,又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。
正则表达式是对字符串(包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为“元字符”))操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。正则表达式是一种文本模式,该模式描述在搜索文本时要匹配的一个或多个字符串。
元字符
正则表达式由一些普通字符和一些元字符(metacharacters)组成。普通字符包括大小写的字母和数字,而元字符则具有特殊的含义,以下给出解释:
| 元字符 | 含义 |
|---|---|
| . | 匹配任意单个字符 |
| * | 匹配前一个字符出现0次或连续多次 |
| .* | 匹配任意长度 |
| ^ | 匹配以……开头 |
| $ | 匹配以……结尾 |
| ^$ | 匹配空行 |
| [ ] | 匹配指定范围内的单个或多个字符 |
| [^ ] | 匹配不包含括号里任意单个或一组字符 |
| ^[ ] | 匹配以括号内的单个或多个字符开头 |
| ^[^ ] | 匹配不以括号内的单个或多个字符开头 |
| \< | 匹配以……开头的行 |
| \> | 匹配以……结尾的行 |
| \<……\> | 匹配某一个单词的行 |
| \{n\} | 匹配前一个字符出现n次 |
| \{n,\} | 匹配前一个字符至少出现n次 |
| \{n,m\} | 匹配前一个字符至少出现n次,至多出现m次 |
| ^$ | 空行 |
grep
grep (缩写来自Globally search a Regular Expression and Print)是一种强大的文本搜索工具,它能使用特定模式匹配(包括正则表达式)搜索文本,并默认输出匹配行。Unix的grep家族包括grep、egrep和fgrep
linux使用GNU版本的grep。它功能更强,它也可以通过-E命令行选项来使用egrep功能
grep的常用参数
| 参数 | 说明 |
|---|---|
| -i | 不区分大小写 |
| -v | 过滤 |
| -n | 显示行号 |
| -w | 精确匹配单词 |
| -E | 可用扩展元字符 |
| -o | 把匹配到的字符按行打印出来 |

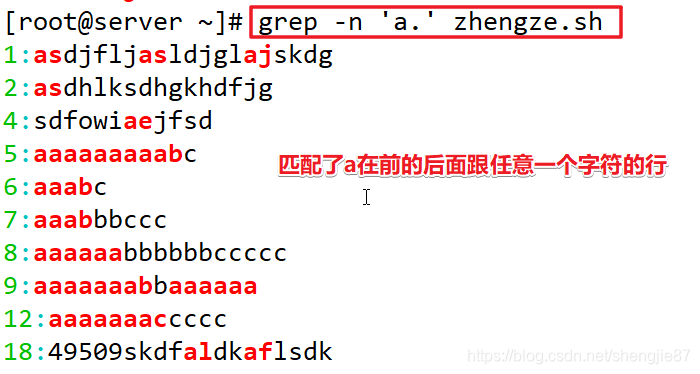
注意:‘a.’不代表只有2个字符,如果一行存在多个’a.'这样的形式它会一起匹配出来!
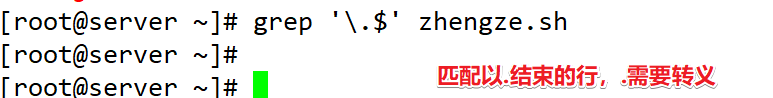
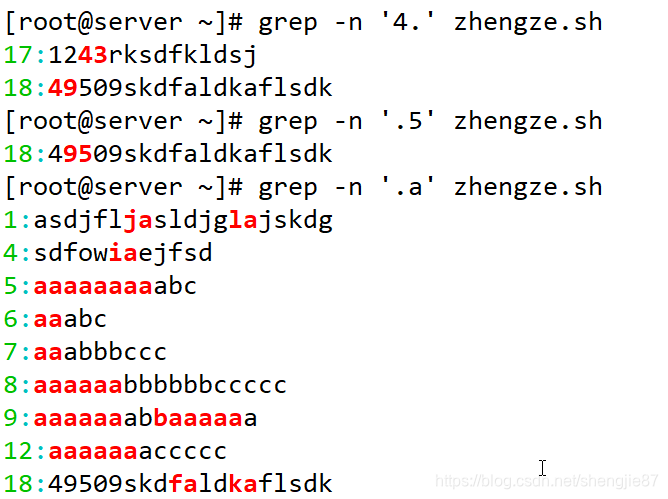
注意:1、a不一定是字符串的开头或者行的开头
2、第一个字符a是固定的,肯定会出现的,而第二个a可能没有或有多个,所以它把有a的行都匹配了
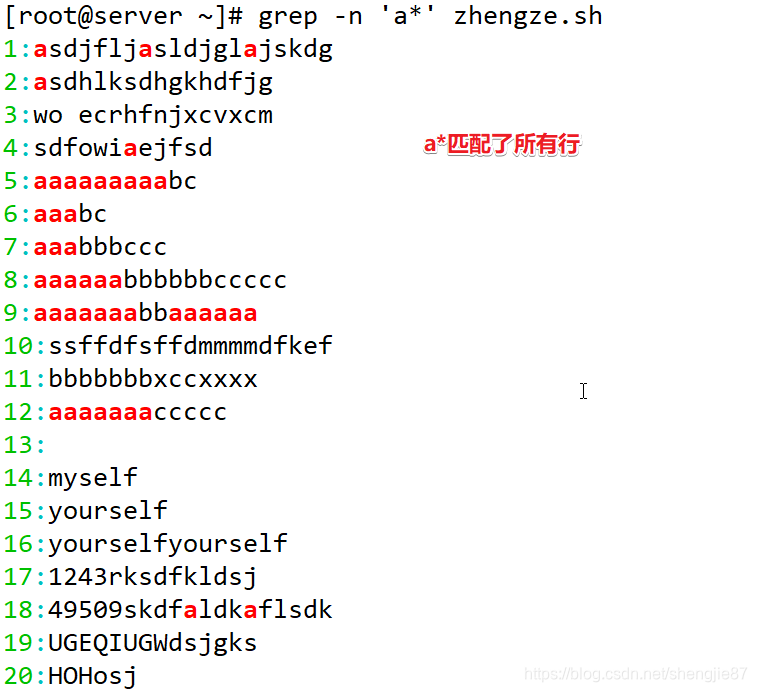
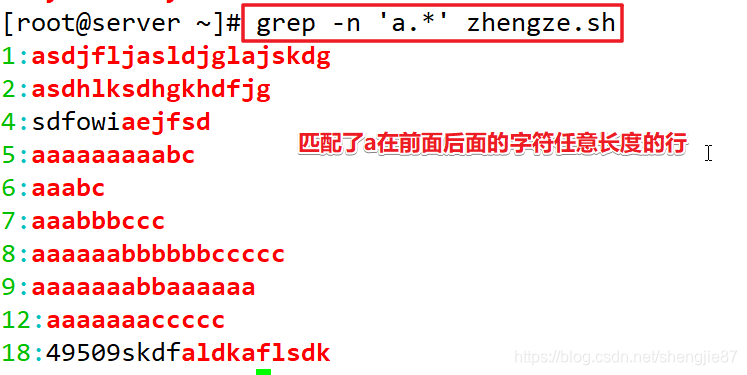
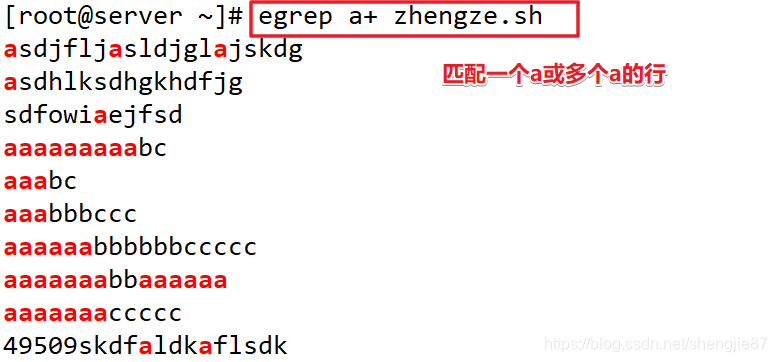
注意:字符a肯定会出现,后面跟1个到多个字符


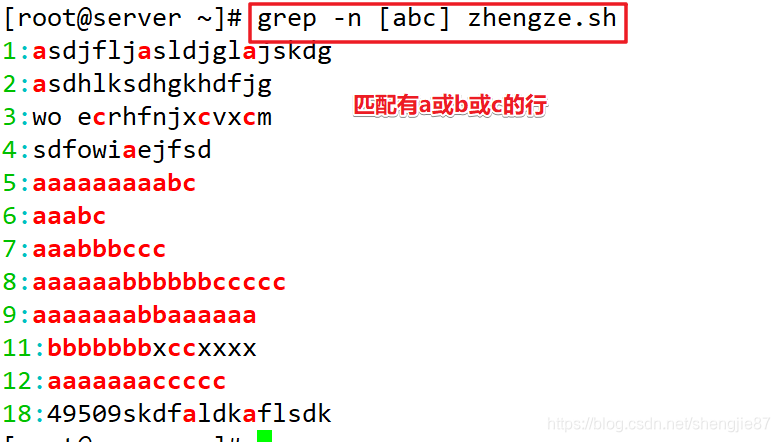
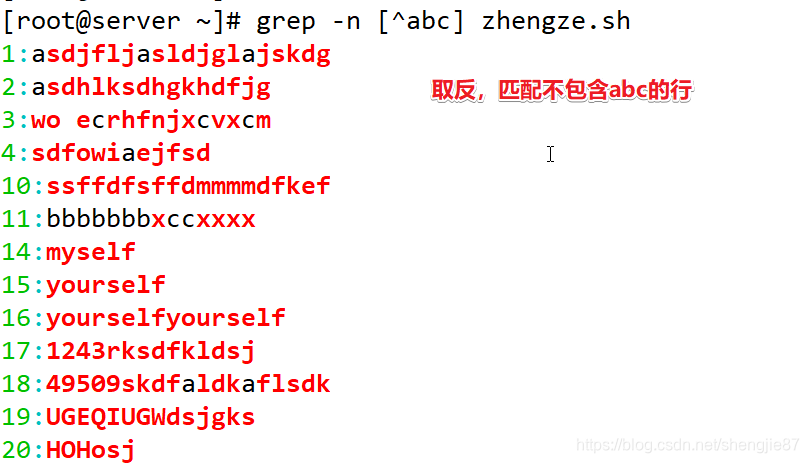
注意:如果一行abc全有它直接过滤掉不会出现,如果只是有abc其中的一个字符它会显示但不会匹配,相当于过滤的意思了,把中括号里^字符后面的看成一个整体过滤掉显示出来
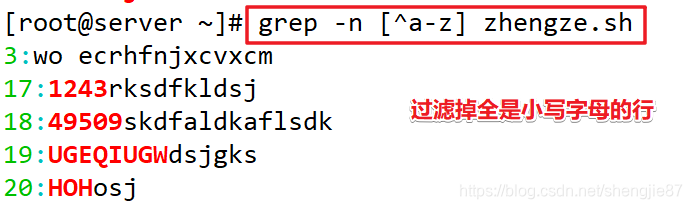


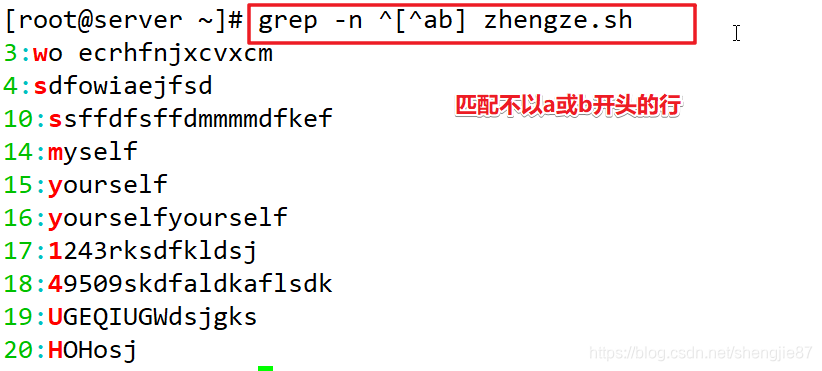
注意:^在中括号里表示不匹配,在中括号外表示以……开头

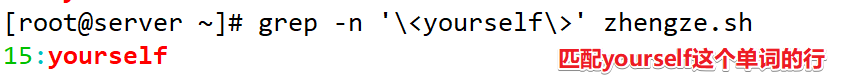

注意:<……>这个里面是精确匹配一个单词!而<和>不是,只是匹配开头结尾,等同于^和$的用法



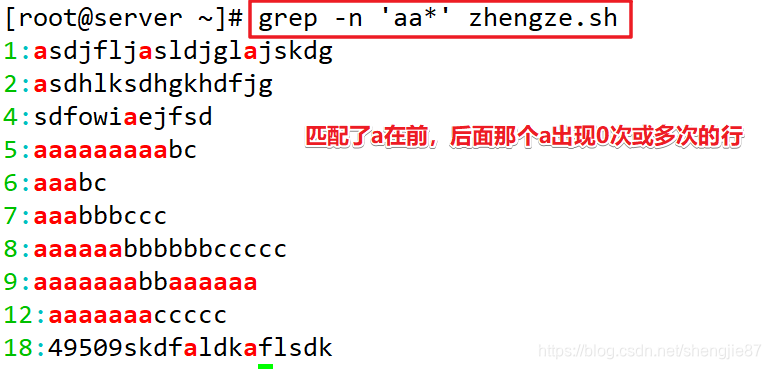
注意:这里匹配的是a+几个a的倍数的行,而不是几次就是几次



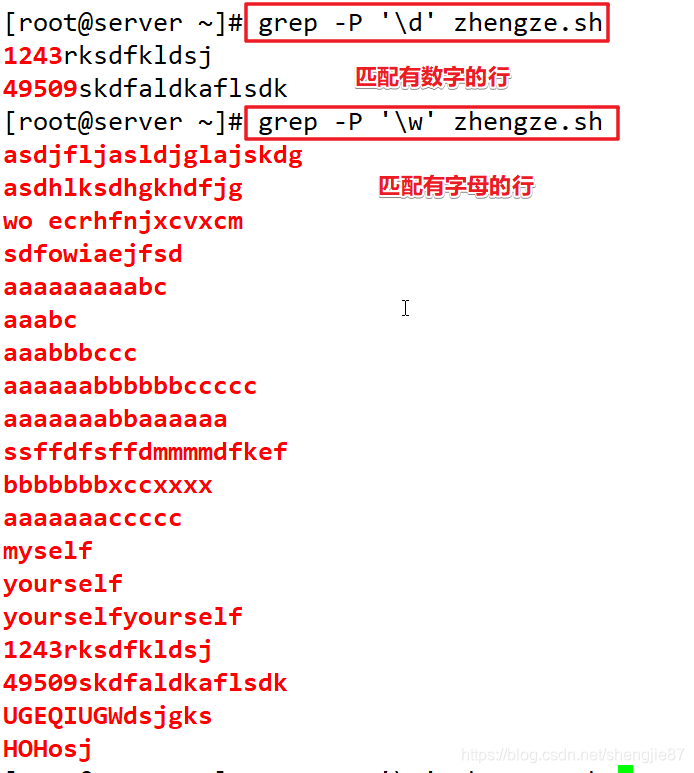
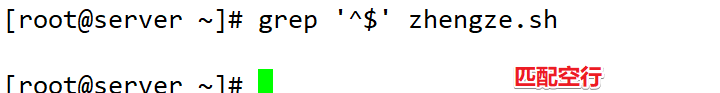
扩展元字符
| 元字符 | 含义 |
|---|---|
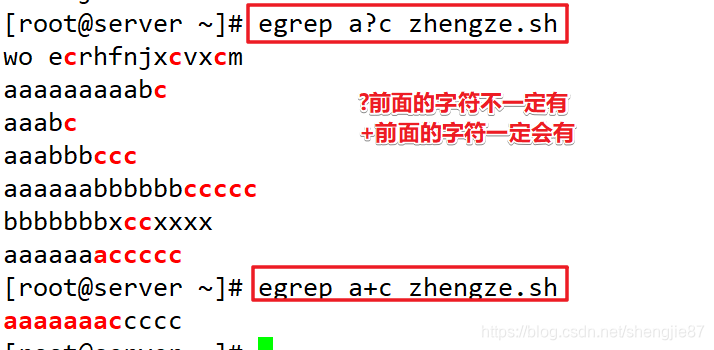
| + | 匹配前一个字符1个或多个 |
| ? | 匹配0个或1个字符 |
| | | 或 |
| () | 匹配括号里的整体 |
| {n} | 前一个字符重复n次 |
| {n,} | 前一个字符至少重复n次 |
| {n,m} | 前一个字符出现n-m次 |
egrep
egrep命令只跟grep有很小不同。egrep是grep的扩展,支持更多的元字符
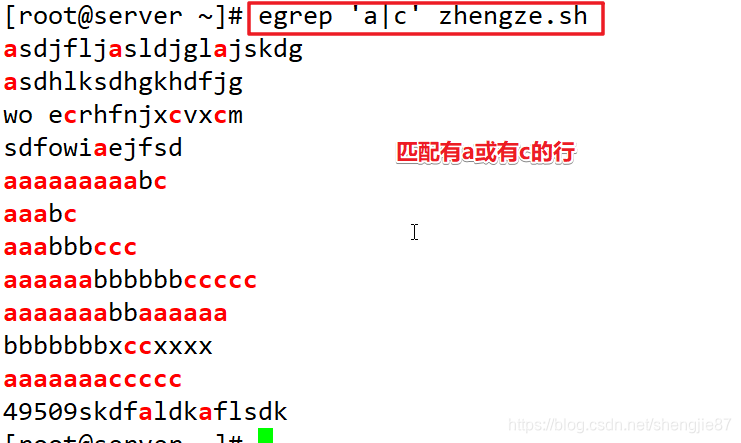



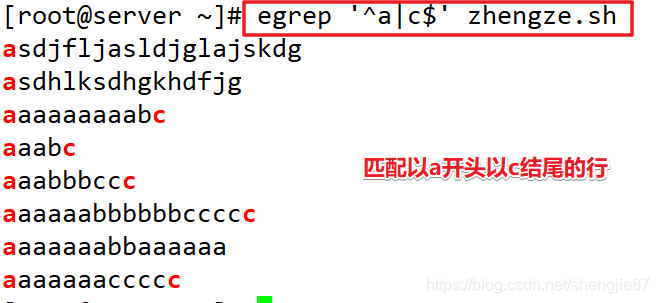
注意:竖线两边不能有空格