为什么要用Hive?
前面我用MapReduce端join操作两张表,大家也看到很麻烦,而现在有一个工具可以不用那么麻烦的去写MapReduce程序了,只需要用Hive就可以照样显示需要的结果。
Hive是基于Hadoop的一个数据仓库工具;它是MapReduce的一个封装,底层就是MapReduce程序;
Hive可以将结构化的数据文件(按照各字段分类的数据)映射成一张虚表,并提供类SQL查询功能;
有了Hive后我们就不用再写麻烦的MapReduce程序了。
说白了Hive的本质是把SQL语句转化成了MapReduce程序。
Hive中处理的数据分两部分存放:
① 处理的结构化数据,存储在HDFS中
② 表的元数据存储在元数据库mysql中
表的元数据和mysql中的结构化数据,通过映射,构成一张虚表,用于Hive查询数据分析。
接下来就看如何建表,其实和mysql语法有很多类似地方;
在添加mysql配置的时候就已经配置好了数据库名叫hive。
数据表分为内部表和外部表
(1)内部表(管理表)
HDFS中为所属数据库目录下的子文件夹
数据完全由Hive管理,删除表(元数据)会删除hdfs中数据
(2)外部表(External Tables)
数据保存在指定位置的HDFS路径中
Hive不完全管理数据,删除表(元数据)不会删除hdfs中数据
新建一张外部表
cerate external table [if not exists] customs(
cust_id string,
cust_name string,
work_place array < string>,
sex_age struct < sex:string,age:int>,
rst_score map<string,int>
)
comment ‘This is an external table’
row format delimited
fields terminated by ‘,’
collection items terminated by ‘,’
map keys terminated by ‘:’
stored as textfile
location ‘/user/root/custom.csv’;
当然只有安装了hadoop和hive才能建表,给大家讲解一下什么意思;
有"external" 说明这是张外部表,不写的话就是内部表;
[IF NOT EXISTS] 表示不存在这个表名可以创建,"[]"为可选参数;
括号里面的数据指得是所有的列和数据类型,可以是数组,键值对等等;
"comment"是注释,可以不写
"row format delimited“ 行格式分割
"fields terminated by ‘,’ 以逗号分隔列字段
"collection items terminated by ‘,’ 以逗号分隔集合和映射
"map keys terminated by ‘:’ 以:分隔键值对
"stored as textfile 文件存储格式是 textfile
"location ‘/user/root/custom.csv’ 数据存储在hdfs的路径
建好后要把custom.csv这个文件上传到hdfs上才能读取,
上传好以后在查询表,就能读取hdfs中数据了。
删除库和表
删数据库
drop database if exists 数据库名 cascade;
注意 使用cascade可删除含表的数据库
删除表,不保留表结构
drop table if exists 表名;
永久删除表中数据,保留表结构,及其列、约束、索引等
truncate table 表名;
用overwrite 加载本地数据到hive数据仓库
load data local inpath ‘/user/root/custom.csv’ overwrite into table 表名;
local:加上local指本地的数据路径,也就是在linux系统下的文件路径
不加local:指文件在hdfs下的路径,文件上传到hdfs后的路径
注意:很多人在建表的时候会报一个错
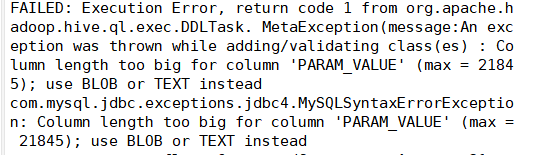 报这个错的一个原因是创建mysql数据库的时候,修改了指定的字符集,改成了utf-8,所以出问题了;将字符集改成默认编码格式latin1就行了
报这个错的一个原因是创建mysql数据库的时候,修改了指定的字符集,改成了utf-8,所以出问题了;将字符集改成默认编码格式latin1就行了
alter database hive character set latin1;
或者删了数据库,重新在创建的时候不要改字符集,就用默认的字符集就好了。