1,搭建Flink集群,在节点node1,node2,node3安装
修改配置文件:
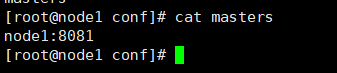
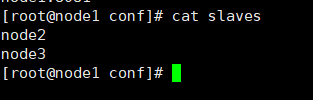
flink-conf.yaml 配置文件
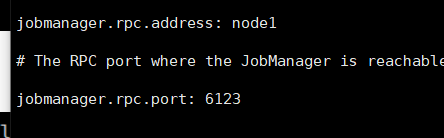
2,启动hadoop集群,保证hive也是正常的:
启动Flink,成功如下:

3,Flink1.10与Hive的生产级别集成

内存优化点:使用多少内存就用多少内存。

4,我们需要做的流程:

1)使用flink-sql-benchmark创建Hive测试数仓库表跟数据
工具地址:
https://github.com/ververica/flink-sql-benchmark
按照流程:

实践步骤:1) yum install gcc 同时已经安装maven,否则启动的时候会提醒你missing
2)cd hive-tpcds-setup
./tpcds-build.sh (编译,会去官网拖包,可能会很慢。。 注:在家里真是慢,草鸡慢)

3)生成数据
cd hive-tpcds-setup
./tpcds-setup.sh 1 (这个参数是指定需要产生数据的大小,单位为G)
4)生成的库叫 tpcds_bin_orc_1
会创建24张表,7张事实表,17张维表

5)下载hive对应jar包丢入到flink lib目录下面:

6)启动flink集群,我这里是重启
7)如果是通过sql-client 玩玩的话:
修改配置:
![]()


8)进入客户端:
效果图 :

命令执行:

代码方式:
1,先进入flink-tpcds 然后编译
2,然后执行命令
3,我们会在Flink web端看到任务

以及控制台的执行结果:

=========================================================================================
JDBC Driver连接Flink方式:

1)下面项目地址:
https://github.com/ververica/flink-sql-gateway
步骤哦:
1,先下载
2,配置文件.yaml:
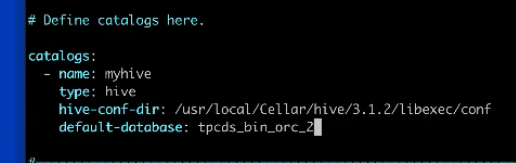
3,执行(需要配置Flink-home):

Flink SQL Gateway
Flink SQL gateway is a service that allows other applications to easily interact with a Flink cluster through a REST API.
User applications (e.g. Java/Python/Shell program, Postman) can use the REST API to submit queries, cancel jobs, retrieve results, etc.
Flink JDBC driver enables JDBC clients to connect to Flink SQL gateway based on the REST API.
Currently, the REST API is internal API and we recommend users to interact with the gateway through JDBC API. Flink SQL gateway stores the session properties in memory now. If the service is stopped or crashed, all properties are lost. We will improve this in future.
This project is at an early stage. Feel free to file an issue if you meet any problems or have any suggestions.
Startup gateway service
There are four steps to starting the service from scratch:
Downloads (or builds) the Flink package. Flink SQL gateway only supports Apache Flink-1.10 now, you can download it through https://flink.apache.org/downloads.html#apache-flink-1100.
Starts up a Flink cluster. Flink SQL gateway requires a running Flink cluster where table programs can be executed. For more information about setting up a Flink cluster see the Cluster & Deployment part.
Configures the FLINK_HOME environment variable using the following command (and add the same into ~/.bashrc): export FLINK_HOME=<flink-install-dir>
Downloads (or builds) the Flink SQL gateway package and executes
./bin/sql-gateway.shThe gateway can be started with the following optional CLI commands.
./bin/sql-gateway.sh -h The following options are available: -d,--defaults <default configuration file> The properties with which every new session is initialized. Properties might be overwritten by session properties. -h,--help Show the help message with descriptions of all options. -j,--jar <JAR file> A JAR file to be imported into the session. The file might contain user-defined classes needed for statements such as functions, the execution of table sources, or sinks. Can be used multiple times. -l,--library <JAR directory> A JAR file directory with which every new session is initialized. The files might contain user-defined classes needed for the execution of statements such as functions, table sources, or sinks. Can be used multiple times. -p,--port <service port> The port to which the REST client connects to.If no configuration file is specified, the gateway will read its default configuration from the file located in ./conf/sql-gateway-defaults.yaml. See the configuration part for more information about the structure of environment files. If no port is specified in CLI commands or in the configuration file, the gateway will be started with the default port 8083.
Configuration
A SQL query needs a configuration environment in which it is executed. The so-called environment file defines server properties, session properties, available catalogs, table sources and sinks, user-defined functions, and other properties required for execution and deployment.
Every environment file is a regular YAML file. An example of such a file is presented below.
# Define server properties. server: bind-address: 127.0.0.1 # optional: The address that the gateway binds itself (127.0.0.1 by default) address: 127.0.0.1 # optional: The address that should be used by clients to connect to the gateway (127.0.0.1 by default) port: 8083 # optional: The port that the client connects to (8083 by default) # Define session properties. session: idle-timeout: 1d # optional: Session will be closed when it's not accessed for this duration, which can be disabled by setting to zero. The minimum unit is in milliseconds. (1d by default) check-interval: 1h # optional: The check interval for session idle timeout, which can be disabled by setting to zero. The minimum unit is in milliseconds. (1h by default) max-count: 1000000 # optional: Max count of active sessions, which can be disabled by setting to zero. (1000000 by default) # Define tables here such as sources, sinks, views, or temporal tables. tables: - name: MyTableSource type: source-table update-mode: append connector: type: filesystem path: "/path/to/something.csv" format: type: csv fields: - name: MyField1 type: INT - name: MyField2 type: VARCHAR line-delimiter: "\n" comment-prefix: "#" schema: - name: MyField1 type: INT - name: MyField2 type: VARCHAR - name: MyCustomView type: view query: "SELECT MyField2 FROM MyTableSource" # Define user-defined functions here. functions: - name: myUDF from: class class: foo.bar.AggregateUDF constructor: - 7.6 - false # Define available catalogs catalogs: - name: catalog_1 type: hive property-version: 1 hive-conf-dir: ... - name: catalog_2 type: hive property-version: 1 default-database: mydb2 hive-conf-dir: ... hive-version: 1.2.1 # Properties that change the fundamental execution behavior of a table program. execution: parallelism: 1 # optional: Flink's parallelism (1 by default) max-parallelism: 16 # optional: Flink's maximum parallelism (128 by default) current-catalog: catalog_1 # optional: name of the current catalog of the session ('default_catalog' by default) current-database: mydb1 # optional: name of the current database of the current catalog # (default database of the current catalog by default) # Configuration options for adjusting and tuning table programs. # A full list of options and their default values can be found # on the dedicated "Configuration" page. configuration: table.optimizer.join-reorder-enabled: true table.exec.spill-compression.enabled: true table.exec.spill-compression.block-size: 128kb # Properties that describe the cluster to which table programs are submitted to. deployment: response-timeout: 5000This configuration:
- defines the server startup options that it will be started with bind-address
127.0.0.1, address127.0.0.1and port8083,- defines the session's limitations that a session will be closed when it's not accessed for
1d(idle-timeout), the server checks whether the session is idle timeout for every1h(check-interval), and only1000000(max-count ) active sessions is allowed.- defines an environment with a table source
MyTableSourcethat reads from a CSV file,- defines a view
MyCustomViewthat declares a virtual table using a SQL query,- defines a user-defined function
myUDFthat can be instantiated using the class name and two constructor parameters,- connects to two Hive catalogs and uses
catalog_1as the current catalog withmydb1as the current database of the catalog,- the default parallelism is 1, and the max parallelism is 16,
- and makes some planner adjustments around join reordering and spilling via configuration options.
Properties that have been set (using the
SETcommand) within a session have highest precedence.Dependencies
The gateway does not require to setup a Java project using Maven or SBT. Instead, you can pass the dependencies as regular JAR files that get submitted to the cluster. You can either specify each JAR file separately (using
--jar) or define entire library directories (using--library). For connectors to external systems (such as Apache Kafka) and corresponding data formats (such as JSON), Flink provides ready-to-use JAR bundles. These JAR files can be downloaded for each release from the Maven central repository.The full list of offered SQL JARs and documentation about how to use them can be found on the connection to external systems page.
Supported statements
The following statements are supported now.
statement comment SHOW CATALOGS Lists all registered catalogs SHOW CURRENT_CATALOG Shows current catalog SHOW DATABASES Lists all databases in the current catalog SHOW CURRENT DATABASE Shows current database in current catalog SHOW TABLES Lists all tables in the current database of the current catalog SHOW FUNCTIONS Lists all functions SHOW MODULES Lists all modules USE CATALOG catalog_name Sets a catalog with given name as the current catalog USE database_name Sets a database with given name as the current database of the current catalog CREATE TABLE table_name ... Creates a table with a DDL statement DROP TABLE table_name Drops a table with given name ALTER TABLE table_name Alters a table with given name CREATE DATABASE database_name ... Creates a database in current catalog with given name DROP DATABASE database_name ... Drops a database with given name ALTER DATABASE database_name ... Alters a database with given name CREATE VIEW view_name AS ... Adds a view in current session with SELECT statement DROP VIEW view_name ... Drops a table with given name SET xx=yy Sets given key's session property to the specific value SET Lists all session's properties RESET Resets all session's properties set by SETcommandDESCRIBE table_name Shows the schema of a table EXPLAIN ... Shows string-based explanation about AST and execution plan of the given statement SELECT ... Submits a Flink SELECTSQL jobINSERT INTO ... Submits a Flink INSERT INTOSQL jobINSERT OVERWRITE ... Submits a Flink INSERT OVERWRITESQL job
2) JDBC Driver:
1,下载:https://github.com/ververica/flink-jdbc-driver
2,build之后jar放在hive lib下
3,使用beeline连接flink

验证:

==================================================================================