Zookeeper环境搭建
一、准备工作
- 安装包下载:https://pan.baidu.com/s/1jh_93RZ_i9NfxnBGTNADtg
提取码:42jq - 解压安装:
tar -zxvf zookeeper-3.4.6.tar.gz -C /opt
注:安装ZooKeeper前需搭建好Hadoop环境:
参考:https://blog.csdn.net/and52696686/article/details/107287066
二、ZooKeeper配置
1):以hadoop-1为操作对象
- 配置全局环境变量:
vi /etc/profile
添加以下两行代码:
export ZK_HOME=/opt/zookeeper-3.4.6
export PATH=$PATH:$ZK_HOME/bin
使之立即生效: source /etc/profile
- 修改配置文件zoo.cfg
cd /opt/zookeeper-3.4.6/conf/
vi zoo.cfg
注:默认没有该文件,需创建,但目录下有zoo_sample.cfg文件参考
在文本中写入以下内容:
# The number of milliseconds of each tick
tickTime=2000
#最大访问数:不限制
maxClientCnxns=0
# The number of ticks that the initial
# synchronization phase can take
#初始化最小进程数:50
initLimit=50
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
#数据目录
dataDir=/opt/zookeeper-3.4.6/zookeeperdata
# the port at which the clients will connect
clientPort=2181
#配置三台以上的奇数台可用机器主机名或者ip,注如果不配集群不需要添加以下内容
server.1=hadoop-1:2888:3888
server.2=hadoop-2:2888:3888
server.3=hadoop-3:2888:3888
- 创建数据目录:
mkdir /opt/zookeeper-3.4.6/zookeeperdata
- 进入该数据目录,创建myid文件,输入对应主机名的编号,对照上文中zoo.cfg中插入的代码:

server.1对应的是虚拟机hadoop-1,则myid中写入数字1
cd /opt/zookeeper-3.4.6/zookeeperdata
vi myid
2):对于其他节点hadoop-2、hadoop-3需重复上述操作
三、启动和关闭ZooKeeper
- 启动:
zkServer.sh start - 关闭:
zkServer.sh stop
四、测试
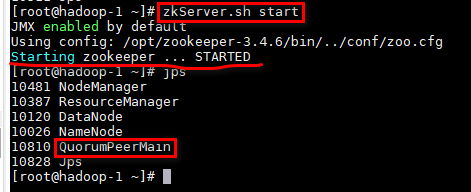
启动输入jps,出现QuorumPeerMain进程服务说明启动成功
zkServer.sh start
jps
如下图所示:
每台机器上分别执行:
zkServer.sh status
查看每台机器的Zookerpeer状态,正确的状态是只有一台机器是leader,其余机器都显示follower
注:hadoop生态系统所有节点需时间一致,必须要保证时间同步,最好与window本机时间一致,输入 date 查看虚拟机时间,若时间错误或不一致需要更改时间同步。
设置集群时间同步:
https://www.cnblogs.com/quchunhui/p/7658853.html