内存字节对齐现象
我们首先通过两个结构体来观察iOS的内存字节对齐的现象。
typedef struct StructOne {
char a; //1字节
double b; //8字节
int c; //4字节
short d; //2字节
} MyStructOne;
typedef struct StructTwo {
double b; //8字节
int c; //4字节
short d; //2字节
char a; //1字节
} MyStructTwo;
NSLog(@"MyStructOne:%lu", sizeof(MyStructOne));
NSLog(@"MyStructTwo:%lu", sizeof(MyStructTwo));
上述代码打印出来的结果为:
MyStructOne:24
MyStructTwo:16
为什么定义相同的结构体,交换了变量在结构体中的顺序,结构体的内存大小就改变了呢?这就是iOS中“内存字节对齐”的现象。
内存字节对齐规则
每个特定平台上的编译器都有自己的默认“对齐系数”。可以通过预编译命令#pragma pack(n),n=1,2,4,8,16来指定对齐系数,其中的n就是“对齐系数”,也是需要对齐的字节数。
在了解为什么要进行内存字节对齐之前,我们先来看看内存字节对齐的规则:
①数据成员对齐规则:结构体每个数据成员相对结构体的首地址的偏移量都是“对齐系数”的整数倍,如不满足,对数据成员进行填充字节以满足。可以使用后面的数据成员进行字节填充。
②结构体对齐规则:结构体的首地址是“对齐系数”的整数倍,结构体的总大小也是“对齐系数”的整数倍,如不满足,最后填充字节以满足。
验证字节对齐规则:
Xcode中默认为#pragma pack(8),也就是8字节对齐。如果在设置为#pragma pack(1) 就代表不进行内存对齐,之前两个结构体的内存大小就都是16了。
MyStructOne的进行内存字节对齐后的结构体为:
// Shows the actual memory layout
struct StructOne {
char a; // 1 字节
char _pad0[7]; //占位char[]用于补齐7字节以满足8的整数倍(条件1)
double b; // 8 字节,因为double能占满8字节,所以无法使用double追加在char后面来补齐
int c; // 4 字节
short d; // 2 字节,追加在int c后面进行补齐
char _pad1[2]; // 再补齐2字节让结构体的大小满足8的整数倍,(条件1和条件2)
//c、d和_pad1[2]是组合起来补齐了8字节
}

MyStructTwo的进行内存字节对齐后的结构体为:
// Shows the actual memory layout
struct StructTwo {
double b; //8字节
int c; //4字节
short d; //2字节
char a; //1字节
char _pad0; //占位char让结构体的大小满足8的整数倍
}

MyStructOne通过内存字节对齐后增加了9字节,所以MyStructOne的内存大小为24字节。
而MyStructTwo通过4+2+1的组合,只需要补齐一个字节就满足内存字节对齐规则,所以MyStructTwo的内存大小为16字节。
如果结构体中数据成员为结构体:
struct StructTwo {
double b; //8字节
int c; //4字节
short d; //2字节
char a; //1字节
MyStructOne e;
} MyStructTwo;
NSLog(@"MyStructOne:%lu", sizeof(MyStructOne));
NSLog(@"MyStructTwo:%lu", sizeof(MyStructTwo));
上述代码打印出来的结果为:
MyStructOne:24
MyStructTwo:40
结果就是内存大小的累加,因为MyStructOne在成为MyStructTwo的数据成员前就已经进行了字节对齐。
内存字节对齐原理
实际中,内存对齐是编译器来处理的,这个过程对于大部分程序员来说都是透明的、隐藏的,但并不意味着我们不需要关注字节对齐的问题。
编译器为什么要进行内存字节对齐?
因为频繁存取字节未对齐的数据,会极大降低CPU的性能。
我们通常认为内存由一个个的字节组成。

但是CPU并不是以字节为单位存取数据的,而是以“块”为单位存取数据。“块”的大小称为内存存取粒度,由CPU的地址总线决定,例如32位就是以4字节为“块”,64位就是以8字节为“块”。
CPU每次存取都会产生一个固定的开销,减少存取次数可以有效提升程序的性能。

为了说明内存对齐背后的原理,我们通过一个例子来说明从未地址与对齐地址读取数据的差异。这个例子很简单:在一个存取粒度为 4 字节的内存中,先从地址 0 读取 4 个字节到寄存器,然后从地址 1 读取 4 个字节到寄存器。
我们举例说明存取字节对齐数据和为字节对齐数据之间的差异。
在一个存取粒度为4字节的内存中,有一个长度为4字节的数据,如果进行了字节对齐那么它的首地址为0,未进行字节对齐那么它的首地址为1。
当CPU从地址0(字节对齐地址)读取数据时,只需一次读取1次即可。
当CPU从地址1(非字节对齐地址)读取数据时,需要读取两次数据才能完成。
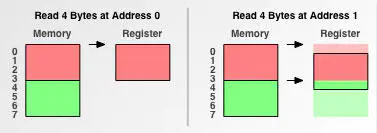
并且在读取完两次数据后,还要将0-3的数据向上偏移1字节,将4-7的数据向下偏移3字节,最后再将两块数据合并放入寄存器,才完成数据读取。

读取一个字节未对齐的数据需要进行了这么多额外的操作,这对 CPU 是很大的开销,所以处理器为了避免这种无端的损耗进行了字节对齐,以内存空间换性能效率。
内存字节对齐实践
了解内存字节对齐原理后,当我们再声明结构体就应该合理的安排内部数据成员的顺序,从而使其占用尽可能小的内存。
节约一点内存占用,你可能觉得这并没有什么大用,但苹果在Runloop的源码中就使用了_padding[3]来手动对齐内存。
struct __CFRunLoopMode {
CFRuntimeBase _base;
pthread_mutex_t _lock; /* must have the run loop locked before locking this */
CFStringRef _name;
Boolean _stopped;
char _padding[3];
CFMutableSetRef _sources0;
CFMutableSetRef _sources1;
CFMutableArrayRef _observers;
CFMutableArrayRef _timers;
//……
};
并且苹果对类的内存也进行了额外的优化,我们可以定义一个类来看一下:
@interface personModel : NSObject
@property (nonatomic, assign) char a;
@property (nonatomic, assign) double b;
@property (nonatomic, assign) int c;
@property (nonatomic, assign) short d;
@end
//调用、赋值
personModel *model = [[personModel alloc] init];
model.a = 'a';
model.b = 24.55;
model.c = 1;
model.d = 2;
//打印类的内存来观察
0x600003739d20: 0x0000000109620830 0x0000000100020061
0x600003739d30: 0x40388ccccccccccd 0x0000000000000000
我们可以从实例的内存中得到:0x0000000109620830是类isa指针地址,0x0000000100020061中前4字节是c,接着2字节是d,接着1字节应该是占位的补齐字节,最后1字节是a。
编译器并没有按类中声明属性的顺序进行字节对齐,而是对属性先进行了排序组合再进行字节对齐,这样不管你类声明成什么样子,编译器都尽可能的帮你减少了内存浪费。
因此,我们将类中属性顺序打乱,应该也没有任何改变:
@interface personModel : NSObject
@property (nonatomic, assign) double b;
@property (nonatomic, assign) char a;
@property (nonatomic, assign) short d;
@property (nonatomic, assign) int c;
@end
//打印类的内存来观察
0x6000015b47c0: 0x0000000106a2e830 0x0000000100020061
0x6000015b47d0: 0x40388ccccccccccd 0x0000000000000000
结果的确如此,只有isa指针改变了。
内存字节对齐算法
字节对齐本质就是将字节数调整为对齐系数的整数倍。
算法一:先判断是否已经对齐,然后以当前倍数+1再乘以对齐系数,就一定得到对齐系数的整数倍了。
unsigned int bytes_align(unsigned int bytes, unsigned int alignment) {
if (bytes % alignment == 0)
return bytes;
return (bytes / alignment + 1) * alignment;
}
算法二:算法一使用了除法和乘法,效率不高,那么我们想办法变成加减法和模运算。
首先(bytes / alignment + 1)是为了得到当前倍数,那么可以变成bytes + (alignment - 1),使未对齐的一定会产生进位,然后减去加法产生的多余的部分即可。
而已对齐的不会产生进位,多余的部分也会被减去,开头的判断就可删掉了。
unsigned int bytes_align(unsigned int bytes, unsigned int alignment) {
unsigned int temp = bytes + (alignment - 1);
return temp - (temp%alignment);
}
算法三:在算法二原理的基础上,我们还可以进一步将模运算改成位运算。使用位运算将低于对齐系数的二进制位都置为0,例如8字节对齐就将低3位置为0。这样算法效率更高了。
unsigned int bytes_align(unsigned int bytes, unsigned int alignment) {
return (bytes + (alignment - 1)) & ~(alignment - 1);
}
以下代码是苹果源码里的字节对齐算法:
define WORD_MASK 7UL
static inline uint32_t word_align(uint32_t x) {
return (x + WORD_MASK) & ~WORD_MASK;
}
static inline size_t word_align(size_t x) {
return (x + WORD_MASK) & ~WORD_MASK;
}
static inline size_t align16(size_t x) {
return (x + size_t(15)) & ~size_t(15);
}