线段树优化dp
当递推的时候,整个区间的变化都是一样的,就可以考虑用线段树加速dp递推。
单调队列优化dp
对于某一个 i 进行 dp 时,其左边的最优决策点假如是 j,如果 j 随着 i 的增长是单调递增的,那么可以用单调队列优化:队首是最优决策点,然后每次把不符合条件的队首弹出,把更劣的队尾弹出,然后把当前决策点加入队尾。这样保证每个点入队一次出队一次,复杂度为 。
- 比如对于这道题 烽火传递 :
有 n 个烽火台,每个烽火台点亮的代价为 a[i],连续 m 个烽火台至少要有一个点亮,问最小代价。
设 表示点亮第 i 个烽火台的最小代价,显然有 。而且这里的 j ,也就是决策点, 一定是单调递增的,因为如果存在一个地方是递减的,那么之前的那个 i 做决策时也应该选择这一个 j,而不应该选择更大的 j 。或者可以这样想:j 越大说明后面的选择越宽裕,而优先队列维护的是对于当前的 i 合法的决策点,更新这个队列时把更劣的踢出去,然后把 加入队尾。
观察这个式子 可以发现,对于每个 i 它的决策点 j 只作用于左边那一块,右边的 不受 j 影响,这是为什么可以用单调队列优化的原因。
分治优化dp
如果右边的 变成了 ,单纯地单调队列就优化不了了,因为 a 这一部分处于不断变化之中。对于这种情况: ,而且满足决策单调性,要么用二分栈,不过我更喜欢用分治去做。
因为满足决策点调性,假如当前我要处理的是 ,并且可能的决策区间为 ,那么我们可以定义一个 ,然后在 中找到 mid 的最优决策点 k,那么 的决策区间就在 上,而 的决策区间就在 上,这样就实现了分治。每一层找最优决策点的复杂度为 O(n),总体复杂度 O(nlogn) 。
这里先补一个小小的算法,然后再讲一个例题,这个算法是 莫队:
它用于解决若干个区间询问的问题,是一种离线算法,因为它要合理地把询问区间进行排序,然后达到相邻区间变化很小的目的。比如我要询问三个区间 [1,3], [9,11], [4, 10],按照原来的顺序就是这样子变化,但是莫队算法会维护 l 和 r,然后对区间合理排序为 [1, 3], [4, 10], [9, 11],以保证 l 和 r 的变化尽量少。具体的排序方法如下:将原数列按照 进行分块,然后第一关键字按照左端点块号排序(升序),第二关键字按照右端点排序(如果块号是奇数,按照从小到大排;如果块号是偶数,按照从大到小排)。这样保证复杂度大致为 。
如果询问的区间本身就是非常的接近,那么就不用排序了。
一个模板(洛谷P3901 数列找不同):
#include <bits/stdc++.h> #define mem(a,b) memset(a,b,sizeof(a)) #define REP(i,a,b) for(int i=(a);i<=(int)(b);i++) #define REP_(i,a,b) for(int i=(a);i>=(b);i--) #define pb push_back using namespace std; typedef long long LL; typedef vector<int> VI; int read() { int x=0,flag=1; char c=getchar(); while((c>'9' || c<'0') && c!='-') c=getchar(); if(c=='-') flag=0,c=getchar(); while(c<='9' && c>='0') {x=(x<<3)+(x<<1)+c-'0';c=getchar();} return flag?x:-x; } const int maxn=1e5+5; struct query {int l,r,id,bl;} q[maxn]; int n,m,a[maxn],L=1,R=0,ans[maxn],c[maxn],cnt; bool cmp(query x,query y) { if(x.bl==y.bl) return x.bl&1?x.r<y.r:x.r>y.r; return x.bl<y.bl; } void get(int l,int r) { while(R<r) {c[a[++R]]++; if(c[a[R]]==1) cnt++;} while(R>r) {c[a[R--]]--; if(c[a[R+1]]==0) cnt--;} while(L<l) {c[a[L++]]--; if(c[a[L-1]]==0) cnt--;} while(L>l) {c[a[--L]]++; if(c[a[L]]==1) cnt++;} } int main() { n=read(),m=read(); REP(i,1,n) a[i]=read(); int sn=sqrt(n); REP(i,1,m) { q[i].l=read(),q[i].r=read(); q[i].id=i; q[i].bl=q[i].l/sn+1; } sort(q+1,q+m+1,cmp); REP(i,1,m) get(q[i].l,q[i].r),ans[q[i].id]=cnt==q[i].r-q[i].l+1; REP(i,1,m) puts(ans[i]?"Yes":"No"); return 0; }可以看到每次询问完 [l, r] 后,全局指针 [L, R] 都会等于询问的区间,L 维护的是要减去的,R维护的是要加上的。莫队算法就是一种优雅的暴力。
这里补充莫队算法是因为这个例子单纯地用分治dp会TLE,这个例子是 Yet Another Minimization Problem:
给定一个数列,把它分成连续的 k 段,每一段的值为其中相等元素的对数,数列分割之后的值为每一段的值之和,求最后的最小值。
设 为把前 i 个元素分成 j 份的最小值,那么转移式很明显: ,其中 表示 [k+1, i] 这个区间内相等元素的对数。可以发现通过计算 k 次可以对其降维,变成 ,而且显然 k 关于 i 单调,因为如果存在 ,那么对于 i 来说 一定是更优的决策点。所以应该用分治dp,但是这里单纯地分治还是会TLE,在分治过程中查询 w(k+1, i) 用莫队的话就不会TLE,因为分治过程中区间两两相隔很近,所以也不用刻意改变查询序列。
斜率优化dp
这个结合一道题目来讲,玩具装箱 :
给出 n 个玩具,每个玩具的长度为 ,从第 i 个玩具到第 j 个玩具装成一箱的总长度为 ,装一箱的花费为 ,其中 L 是一个常数。问把所有玩具装箱的最小花费。
设
表示前 i 个玩具全部装箱的最小花费,并且把 C 的意义变为长度前缀和,那么很容易得出转移式:
我们设
,
,那么转移式变为:
为了方便变化,可以把 min 先去掉然后之后再考虑,然后就可以把式子变成:
也就是说,给出了一个确定的斜率
,我们要在之前的若干个
这些点中找到一个点,使得穿过这个点斜率为给定值的直线的截距最小。那么其实目标就是用队列维护一个凸的点序列:
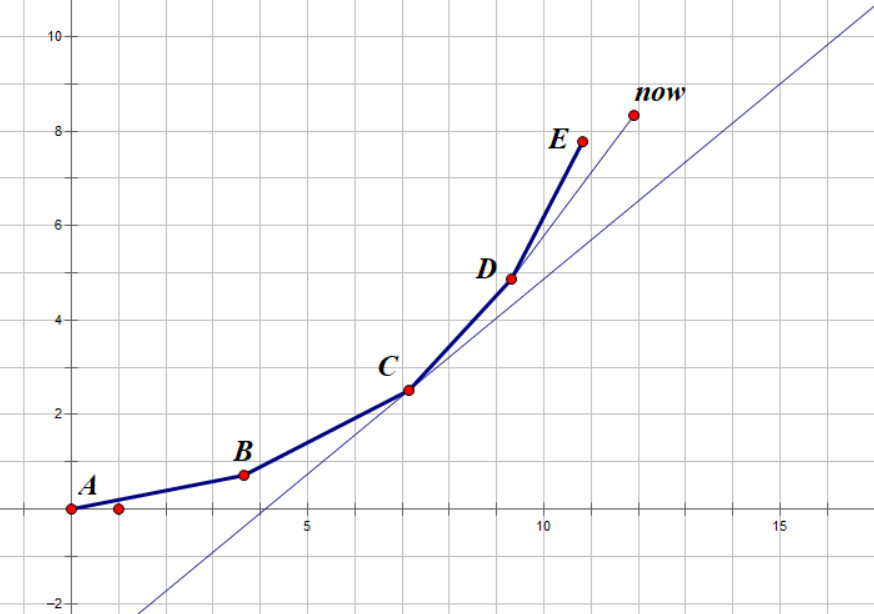
假设 ABCDE 这五个点是当前队列维护的下凸序列,对于当前处理的 i,有一个给定的斜率固定值,我们要找到一个最优点,找的方法就是从队首(A)开始往后找,更劣的就弹出,这里更劣的可以舍弃掉是因为,斜率 一定是单调递增的,所以这些点在以后也不可能是最优点。然后计算完 i 的最优值 之后,i 又贡献了一个新的点 ,这时则应该从队尾开始,把所有不符合下凸的点弹出,然后把 now 入队。
所以斜率优化dp的主要步骤就是:
- 找到可以斜率优化的递推式,确定队列需要维护的点是什么;
- 循环处理:弹队首 --> 计算最优值 --> 更新队尾维护凸序列
因为每个点最多入队一次,出队一次,所以复杂度为 。