全文检索系统引擎
分析
需求:使用倒排索引算法实现一个简单的全文检索系统(只可以检索英文文档)。
实现步骤:
一、使用爬虫或其他方式,保存一些英文文档到数据库

二、对文档进行切分词操作,并去掉stopwords

三、 计算出文档中每个term的tf和df
tf:文档中该term(切分后的词)出现的次数
df:所有文档中,出现该term的文档个数
四、 将tf和df转化为tfw和dfw,并以json格式保存到数据库
tfw和dfw的计算方式
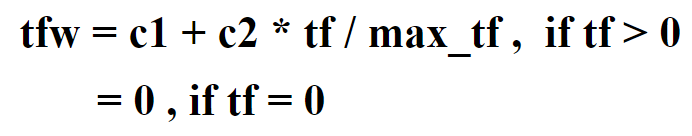
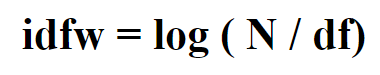
以json格式存储到数据库

五、通过tfw和dfw计算出文档每个term的权重w,并以json格式保存到数据库
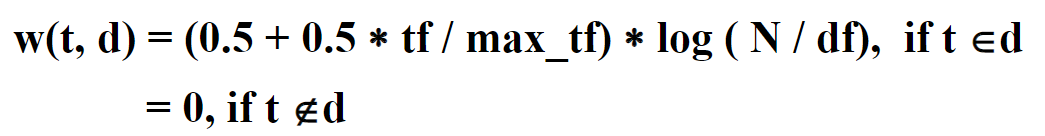
六、创建倒排索引库(提升检索的速率)
以文档中每个不同的term为key,以(doc为key,w为value)为value,进行存储,并保存到redis中
七、创建springboot(或SSM)项目,实现简单的搜索框业务,能够输入query并提交时,将query提交到后端

八、后端接收query,重复以上二到五步的操作,但不需要保存数据库
九、将query与倒排索引库进行相似度计算,返回所有(也可以限定个数)文档与query的相似度,并进行排序
十、将文档以相似度为基准,从高到低排序显示在搜索框下,并将关键字高亮显示

代码实现
SearchService
package org.example.service.impl;
import com.alibaba.fastjson.JSON;
import org.example.dao.SearchDao;
import org.example.pojo.Doc;
import org.example.service.SearchService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.text.DecimalFormat;
import java.util.*;
@Service
public class SearchServiceImpl implements SearchService {
@Autowired
private SearchDao searchDao;
@Autowired
private RedisTemplate redisTemplate;
/**
* 查询所有文档
* @return
*/
@Override
public List<Doc> findDocList() {
List<Doc> docList = searchDao.findDocList();
return docList;
}
/**
* 查询文档总数
* @return
*/
@Override
public Integer findCount() {
Integer count = searchDao.findCount();
return count;
}
/**
* 根据id查询文档
* @param id
* @return
*/
@Override
public Doc findDocById(String id) {
return searchDao.findDocById(id);
}
/**
* 计算tfw、dfw、w,并以json数据存储到数据库
* @param docList
* @return
*/
@Override
public List<Doc> preprocessDocList(List<Doc> docList) {
//遍历文档对象,获取tf
if (docList!=null) {
for (Doc doc : docList) {
//1、处理文档
String document = doc.getDocument();
//去除标点
document = document.replaceAll("\\p{Punct}", "");
//空格分割,获得索引
String[] words = document.split(" ");
//2、获取tf
Map<String, Integer> tfMap = getTf(words);
//将tf处理成tfw
Map<String, Double> tfwMap = processTf(tfMap);
////转成json存储到数据库
String tfwJsonStr = JSON.toJSONString(tfwMap);
searchDao.addTf(tfwJsonStr, doc.getId());
//System.out.println(tfwMap);
}
}
//重新获取文档集合
docList = searchDao.findDocList();
//遍历文档对象,获取df
if (docList!=null) {
for (Doc doc : docList) {
String tfStr = doc.getTf();
Map<String, Double> tfwMap = JSON.parseObject(tfStr, Map.class);
//3、获取df
Map<String, Integer> dfMap = getDf(tfwMap, docList);
//将df处理成dfw
Map<String, Double> dfwMap = processDf(dfMap, findCount());
//转成json存储到数据库
String dfwJsonStr = JSON.toJSONString(dfwMap);
searchDao.addDf(dfwJsonStr,doc.getId());
//System.out.println(dfwMap);
//3.计算w
Map<String, Double> wMap = processW(tfwMap, dfwMap);
//System.out.println(wMap);
//转成json存储数据库
String wJSONStr = JSON.toJSONString(wMap);
searchDao.addW(wJSONStr,doc.getId());
}
}
return docList;
}
/**
* 根据查询和文档集合,获取数据
* @param document
* @param docList
* @param demand 如果为tf,则获取tf;df,则获取df;w,则获取w
* @return
*/
public Map<String, Double> preprocessQuery(String document, List<Doc> docList, String demand){
//去除标点
document = document.replaceAll( "\\p{Punct}", "");
//空格分割,获得索引
String[] words = document.split(" ");
//2、获取tf
Map<String, Integer> tfMap = getTf(words);
//将tf处理成tfw
Map<String, Double> tfwMap = processTf(tfMap);
if ("tf".equals(demand)){
return tfwMap;
}
//3、获取df
Map<String, Integer> dfMap = getDf(tfwMap, docList);
//将df处理成dfw
Map<String, Double> dfwMap = processDf(dfMap, findCount());
if ("df".equals(demand)){
return dfwMap;
}
//3.计算w
Map<String, Double> wMap = processW(tfwMap, dfwMap);
if ("w".equals(demand)){
return wMap;
}
return null;
}
/**
* 去除stopword
* @param word 单个索引
* @return 是否保留,true为删除,false为保留
*/
private Boolean removeStopWord(String word){
InputStream is = SearchServiceImpl.class.getClassLoader().getResourceAsStream("stopword");
BufferedReader br = new BufferedReader(new InputStreamReader(is));
try {
String s = null;
while ((s = br.readLine()) != null){
if (word.equals(s)){
return true;
}
}
return false;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 根据索引数组获取tf,并去除stopword
* @param words 索引数组
* @return 以索引为key,tf数值为value的map集合
*/
private Map<String,Integer> getTf(String[] words){
//将索引放入set集合中
Set<String> querySet = new HashSet<>();
for (String word : words) {
//去重
if (removeStopWord(word)){
continue;
}
querySet.add(word);
}
//获取tf
Map<String,Integer> tfMap = new HashMap<>();
for (String query : querySet) {
int tf = 0;
for (String word : words) {
if (word.contains(query) || word.equalsIgnoreCase(query)){
tf++;
}
}
tfMap.put(query,tf);
}
return tfMap;
}
/**
* 处理tf为tfw
* @param tfMap tf的map集合
* @return tfw的map集合
*/
private Map<String, Double> processTf(Map<String, Integer> tfMap){
if (tfMap!=null){
double c1 = 0.5;
double c2 = 0.5;
int max_tf = -1;
Map<String, Double> tfwMap = new HashMap<>();
Set<Map.Entry<String, Integer>> entries = tfMap.entrySet();
//获取max_tf
for (Map.Entry<String, Integer> entry : entries) {
Integer tfValue = entry.getValue();
if (tfValue>max_tf){
max_tf = tfValue;
}
}
for (Map.Entry<String, Integer> entry : entries) {
String key = entry.getKey();
Integer tfValue = entry.getValue();
tfwMap.put(key,c1 + (c2 * tfValue)/max_tf);
}
return tfwMap;
}
return null;
}
/**
* 根据tf获取df
* @param tfMap tf集合
* @param docList 文档总集合
* @return df集合
*/
private Map<String,Integer> getDf(Map<String, Double> tfMap, List<Doc> docList) {
if (docList!=null && tfMap!=null){
//创建dfmap集合
Map<String,Integer> dfMap = new HashMap<>();
Set<Map.Entry<String, Double>> entries = tfMap.entrySet();
for (Map.Entry<String, Double> entry : entries) {
int num = 0;
String query = entry.getKey();
for (Doc doc : docList) {
String tfStr = doc.getTf();
Map<String,Integer> docTfMap = JSON.parseObject(tfStr, Map.class);
Set<Map.Entry<String, Integer>> entriesTf = docTfMap.entrySet();
for (Map.Entry<String, Integer> stringIntegerEntry : entriesTf) {
String key = stringIntegerEntry.getKey();
if (key.contains(query) || query.contains(key) || key.equalsIgnoreCase(query)){
num++;
}
}
}
dfMap.put(query,num);
}
return dfMap;
}
return null;
}
/**
* 将df处理成dfw,并保留小数后三位
* @param dfMap df集合
* @param N 总文档数量
* @return
*/
private Map<String,Double> processDf(Map<String,Integer> dfMap, double N){
Map<String,Double> dfwMap = new HashMap<>();
if (dfMap != null) {
DecimalFormat decimalFormat = new DecimalFormat("0.000");
Set<Map.Entry<String, Integer>> entries = dfMap.entrySet();
for (Map.Entry<String, Integer> entry : entries) {
String key = entry.getKey();
Integer df = entry.getValue();
if (df!=0 && df!=null){
dfwMap.put(key,Double.parseDouble(decimalFormat.format(Math.log(N/df))));
}else {
dfwMap.put(key,0.000);
}
}
return dfwMap;
}
return null;
}
/**
* 根据dfw和tfw获取w
* @param tfwMap
* @param dfwMap
* @return
*/
private Map<String,Double> processW(Map<String,Double> tfwMap, Map<String,Double> dfwMap){
if (tfwMap != null && dfwMap != null) {
Map<String,Double> wMap = new HashMap<>();
DecimalFormat decimalFormat = new DecimalFormat("0.000");
Set<Map.Entry<String, Double>> tfEntries = tfwMap.entrySet();
Set<Map.Entry<String, Double>> dfEntries = dfwMap.entrySet();
for (Map.Entry<String, Double> tfEntry : tfEntries) {
String tfKey = tfEntry.getKey();
for (Map.Entry<String, Double> dfEntry : dfEntries) {
String dfKey = dfEntry.getKey();
if (tfKey.equals(dfKey)){
Double tfEntryValue= Double.parseDouble(String.valueOf(tfEntry.getValue()));
Double dfEntryValue = Double.parseDouble(String.valueOf(dfEntry.getValue()));
wMap.put(tfKey,Double.parseDouble(decimalFormat.format(tfEntryValue*dfEntryValue)));
}
}
}
return wMap;
}
return null;
}
/**
* 根据数据库中的文档库,生成索引库
*/
public void getIndexW(){
List<Doc> docList = searchDao.findDocList();
Set<String> indexSet = new HashSet<>();
//建立索引
for (Doc doc : docList) {
String tfStr = doc.getTf();
Map<String,Object> map = JSON.parseObject(tfStr, Map.class);
Set<String> set = map.keySet();
for (String s : set) {
if (!indexSet.contains(s)){
indexSet.add(s);
}
}
}
//获取索引库
for (String index : indexSet) {
Map<String,Double> queryMap = new HashMap<>();
//遍历文档集合
for (Doc doc : docList) {
String wStr = doc.getW();
Map<String,Object> map = JSON.parseObject(wStr, Map.class);
Set<Map.Entry<String, Object>> entries = map.entrySet();
//遍历文档索引的w集合
for (Map.Entry<String, Object> entry : entries) {
String key = entry.getKey();
Double value = Double.parseDouble(String.valueOf(entry.getValue()));
if (index.equals(key) || index.contains(key) || key.contains(index)){
queryMap.put(doc.getId(),value);
break;
}
}
}
//将index,转化成小写后存入
index = index.toLowerCase();
redisTemplate.boundHashOps("search").put(index,queryMap);
}
}
}
SearchController
package org.example.controller;
import org.example.pojo.Doc;
import org.example.service.SearchService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.text.DecimalFormat;
import java.util.*;
@RestController
@RequestMapping("/search")
public class SearchController {
@Autowired
private SearchService searchService;
@Autowired
private RedisTemplate redisTemplate;
// /**
// * 接收并处理query,返回List<Doc></>集合
// * @param keywords
// * @return
// */
// @RequestMapping("/searchByKeywords")
// public List<String> searchByKeywords(String keywords){
// List<Doc> docList = searchService.findDocList();
// Map<String, Double> wMap = searchService.preprocessQuery(keywords, docList, "w");
// //System.out.println(wMap);
// //创建map集合,存储和doc的相似度大小
// Map<String, Double> similarMap = new HashMap<>();
// DecimalFormat decimalFormat = new DecimalFormat("0.000");
// //求每个文档的相似度
// for (Doc doc : docList) {
// //初始化相似度值
// Double s = 0.0;
// String wJSONStr = doc.getW();
// Map<String,Object> map = JSON.parseObject(wJSONStr, Map.class);
// Set<Map.Entry<String, Object>> entries = map.entrySet();
// for (Map.Entry<String, Object> entry : entries) {
// String key = entry.getKey();
// Double value = Double.parseDouble(String.valueOf(entry.getValue()));
// Set<Map.Entry<String, Double>> queryEntries = wMap.entrySet();
// for (Map.Entry<String, Double> queryEntry : queryEntries) {
// String queryEntryKey = queryEntry.getKey();
// Double queryEntryValue = queryEntry.getValue();
// if (key.equalsIgnoreCase(queryEntryKey) || key.contains(queryEntryKey) || queryEntryKey.contains(key)){
// s += value * queryEntryValue;
// break;
// }
// }
// }
// similarMap.put(doc.getDocument(),Double.parseDouble(decimalFormat.format(s)));
//
// }
// //System.out.println(similarMap);
// //对相似度集合的value进行排序
// ArrayList<Map.Entry<String, Double>> entries = sortMap(similarMap);
// List<String> docs = new ArrayList<>();
// for (int i = 0; i < docList.size(); i++) {
// docs.add(entries.get(i).getKey());
// //System.out.println(entries.get(i).getValue());
// }
// //System.out.println(docs);
// return docs;
// }
/**
* 倒排索引算法
* 接收并处理query,返回List<Doc></>集合
* @param keywords
* @return
*/
@RequestMapping("/searchByKeywords")
public List<String> searchByKeywords(String keywords){
List<Doc> docList = searchService.findDocList();
Map<String, Double> wMap = searchService.preprocessQuery(keywords, docList, "w");
//创建map集合,存储和doc的相似度大小
Map<String, Double> similarMap = new HashMap<>();
//初始化相似度map集合
DecimalFormat decimalFormat = new DecimalFormat("0.000");
Set<Map.Entry<String, Double>> entries = wMap.entrySet();
//从redis中取出索引库
Map<String,Map> docQueryRedisMap = redisTemplate.boundHashOps("search").entries();
//遍历存储索引集合
for (Map.Entry<String, Double> entry : entries) {
String query = entry.getKey();
//将query转化成小写
query = query.toLowerCase();
Double queryValue = entry.getValue();
Map<String,Object> docQueryMap = docQueryRedisMap.get(query);
//如果根据query从索引库能获取到对应的索引
if (docQueryMap!=null) {
Set<Map.Entry<String, Object>> docQueryMapEntries = docQueryMap.entrySet();
//遍历当前索引的map
double sum = 0;
for (Map.Entry<String, Object> docQueryMapEntry : docQueryMapEntries) {
String docId = docQueryMapEntry.getKey();
Double docQueryValue = Double.parseDouble(String.valueOf(docQueryMapEntry.getValue()));
double similarValue = queryValue * docQueryValue;
if (similarMap.get(docId) != null) {
similarMap.put(docId, docQueryValue + similarValue);
} else {
similarMap.put(docId, similarValue);
}
}
} else {
//如果获取不到,就跳过
continue;
}
}
System.out.println(similarMap);
//创建docs,保存返回的文档
List<String> docs = new ArrayList<>();
if (similarMap!=null && similarMap.size()>0){
//创建doc集合,返回到前端页面
//对相似度集合的value进行排序
ArrayList<Map.Entry<String, Double>> sortEntries = sortMap(similarMap);
for (int i = 0; i < sortEntries.size(); i++) {
//将排序好的doc,按顺序加入到docs中
String document = searchService.findDocById(sortEntries.get(i).getKey()).getDocument();
for (Map.Entry<String, Double> entry : entries) {
String key = entry.getKey();
if (document.contains(key)){
document = document.replace(key,"<span style='color:red'>"+key+"</span>");
}
}
docs.add(document);
}
} else {
//当找不到文档时
docs.add("无法找到相关的文档!");
for (Doc doc : docList) {
docs.add(doc.getDocument());
}
}
//System.out.println(docs);
return docs;
}
/**
* 预处理文档
* @return
*/
@RequestMapping("/preprocess")
public Boolean Preprocess(){
List<Doc> docList = searchService.findDocList();
List<Doc> preprocess = searchService.preprocessDocList(docList);
return true;
}
/**
* 预处理文档
* @return
*/
@RequestMapping("/getIndexW")
public Boolean getIndexW(){
searchService.getIndexW();
return true;
}
public ArrayList<Map.Entry<String,Double>> sortMap(Map map) {
List<Map.Entry<String, Double>> entries = new ArrayList<Map.Entry<String, Double>>(map.entrySet());
Collections.sort(entries, new Comparator<Map.Entry<String, Double>>() {
public int compare(Map.Entry<String, Double> obj1, Map.Entry<String, Double> obj2) {
return (int)(obj2.getValue()-obj1.getValue());
}
});
return (ArrayList<Map.Entry<String, Double>>) entries;
}
}
search.html
<html>
<head>
<meta charset="UTF-8">
<title>搜索框</title>
<link rel="stylesheet" type="text/css" href="../css/bootstrap.min.css" />
<script type="text/javascript" src="../plugins/jQuery/jquery-2.2.3.min.js"></script>
<script type="text/javascript" src="../plugins/bootstrap/bootstrap.min.js"></script>
<style type="text/css">
*{
margin: 0;
padding: 0;
border: none;
}
.x{
display: inline-block;
margin-top: 100px;
margin-left: 500px;
position: relative;
}
.k{
width: 450px;
height: 38px;
border: 1px solid #cccccc;
float: left;
box-sizing: border-box;
}
.n{
width: 102px;
height: 38px;
line-height: 40px;
float: left;
background-color: #38f;
font-size: 16px;
/*鼠标悬停按钮上方,光标成手指样式*/
cursor: pointer;
}
.t{
z-index: 1;
position: absolute;
right: 113px;
top: 50%;
margin-top: -8px;
height: 16px;
width: 18px;
cursor: pointer;
}
</style>
</head>
<body>
<!--<input type="button" value="预处理" οnclick="preprocess()" class="n">-->
<!--<input type="button" value="获取索引库" οnclick="getIndexW()" class="n">-->
<div id="container" class="x">
<input type="text" id="keywords" name="keywords" class="k">
<input type="submit" value="搜索" onclick="search()" class="n">
<span class="t"></span>
</div>
<div id="searchDiv" style="text-align:center;margin-top: 30px;
margin-left: 250px;margin-right: 250px;">
</div>
</body>
<script type="text/javascript">
function search() {
var keywords = $("#keywords").val();
var s = "";
$.ajax({
url:"http://localhost:8080/search/searchByKeywords",
data:"keywords="+keywords,
success:function (data) {
var searchInfo = $("#searchDiv");
$.each(data, function(index,element) {
s += "<div class=\"panel panel-default\" style='text-align:center'>\n" +
"<div class=\"panel-body\" style='text-align:center'>"+element+"</div>\n" +
"</div>";
searchInfo.html(s);
});
},
dataType:"json",
type:"POST"
});
}
function preprocess() {
$.ajax({
url:"http://localhost:8080/search/preprocess",
success:function (data) {
alert("预处理完成!");
},
type:"GET"
});
}
function getIndexW() {
$.ajax({
url:"http://localhost:8080/search/getIndexW",
success:function (data) {
alert("索引库建立完成!");
},
type:"GET"
});
}
</script>
</html>