什么是集成学习?
集成学习:简单概括就是通过某种合理的方式将多个简单的基学习器结合起来,以期获得更准确,更高效的模型。 对某些机器学习任务,有的时候我们使用单个模型已经调到最优,很难再有改进。这时候为了提高性能,往往会用很少量的工作,组合多个基模型(基学习器),使得系统性能提高。 如果基学习器是从某⼀种学习 算法从训练数据中产⽣,称该集成学习是同质的(homogenerous)。如果基学习器是从⼏种不同学习算法从训练数据中产⽣,则称集成学习是异质的(heterogenous )。集成学习中, 通常基学习器之间的互补性越强,或者基学习器更多样的话,集成效果更好。
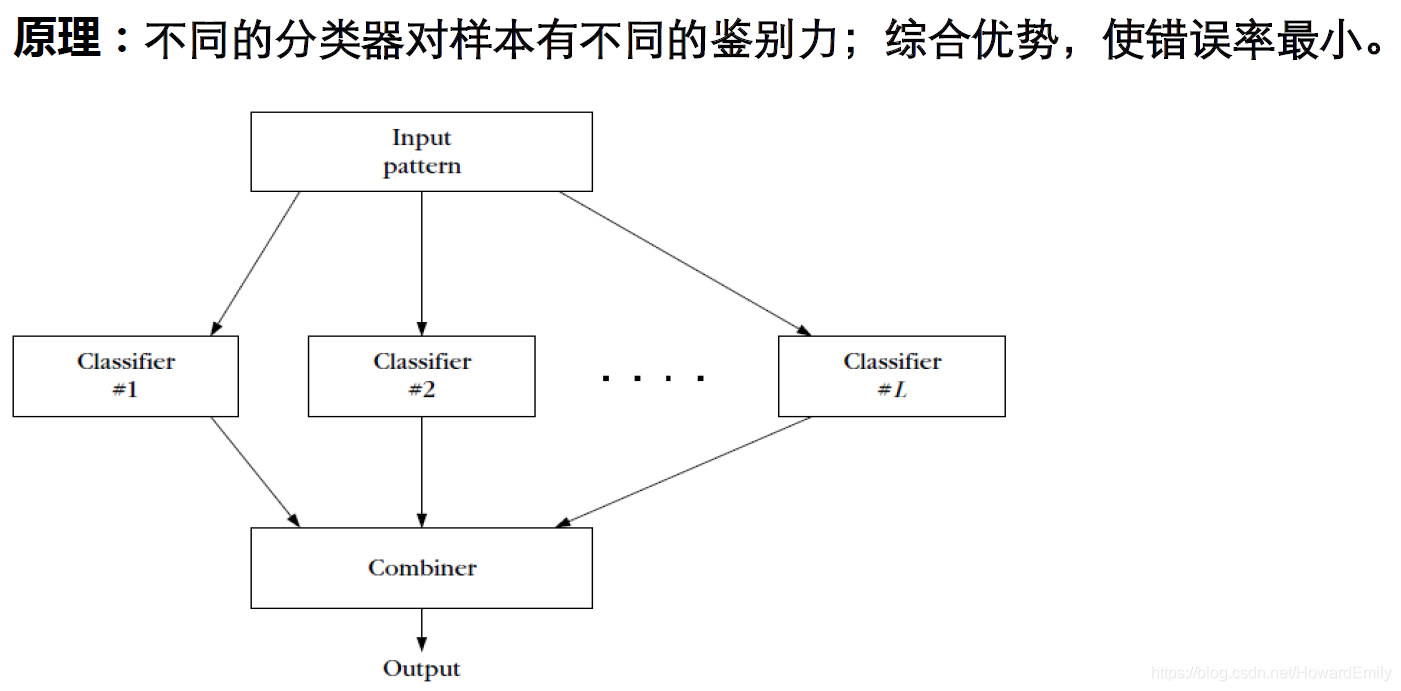

为了帮助大家更好的理解各种集成模型到底在作什么,以及如何减少误差提升性能的;我们先来看一下误差的偏差-方差分解。
误差的偏差-方差分解
点估计的偏差和方差
记训练样本数据集
D上对参数
θ的点估计为:
θ^=g(D),根据频率学派的观点,真实值
θ是固定的,但是未知,而
θ^是一个关于数据
D的函数。由于数据是随机采样的,因此
θ^是一个随机变量。
于是,点估计的偏差定义为:
bias(θ^)=E[θ^]−θ
这里的期望作用在所有数据上。为了理解这里的期望,假设我们可以对整个流程重复多次,每次收集得到数据集
D,利用训练数据得到估计
θ^, 如果将每次收集到的训练样本
D看成是关于总体数据的独立同分布的样本,那么每次收集到的D会有些不同,从而每次得到的参数估计
θ^肯定也会不同,这多个不同的估计可以看成是期望
E[θ^]的估计。
如果
bias(θ^)=0,那么我们就称这个估计是无偏的。
顺便提一嘴,统计上还有个概念叫Fisher一致性,它是从稳健性估计的角度来看


点估计的⽅差为
V(θ^) ,它刻画的是从潜在的数据分布中独⽴地获取样本集时,点估计的变化程度。
例题:从均值为
μ的伯努利分布中,得到独立同分布样本
x1,x2,…,xN,
E(xi)=μ,V(xi)=μ(1−μ)。
样本均值可作为参数
μ的⼀个点估计,即:
μ^=N1∑i=1Nxi
因为
E(μ^)=E[N1i=1∑Nxi]=N1E[i=1∑Nxi]=μ
所以
μ^为
μ的一个无偏估计。
估计的⽅差为:
V(μ)=V[N1i=1∑Nxi]=N21V[i=1∑Nxi]=N1μ(1−μ)
这表明估计的方差随样本数量
N增加而下降,估计的⽅差随着样本数量的增加⽽下降,这是所有估计的共性,这也是为什么说可能的情况下,我们希望训练样本数据越多越好。
预测误差的偏差-方差分解
我们希望模型能够尽可能准确的描述数据产生的真实规律,这里的准确是指模型测试集上的预测误差尽可能小。模型在未知数据上的误差,称为泛化误差。,它主要有三种来:随机误差,偏差和方差。
-
随机误差。
随机误差
η是不可消除的,与我们数据的产生或收集机制密切相关,并且认为其与真值
y∗是独立的,若
y∗为实值则一般认为其随机误差服从
η∼N(0,ση2)的正态分布, 于是可以的真实值
y∗与我们的观测值
y的关系如下:
y=y∗+η
也就是说观测值
y是服从
y∼N(y∗,ση2)的正态分布。
-
偏差。 偏差来源于模型中的错误假设。偏差过高就意味着模型所代表的特征和标签之间的关系是错误的,对应欠拟合现象。
给定数据
D,在
D上训练得到我们的模型设为
fD。根据
fD对训练样本进行测试,得到的预测结果记为
y^D=fD(x)。模型预测的偏差的平方度量模型预测
y^D的期望与真实值
y∗之间的差异:
bias2(y^D)=(E(y^D)−y∗)2
偏差表示学习算法的期望预测与真实值之间的偏离程度,即偏差刻画了我们的模型本身对数据的拟合能力。
-
方差。方差来源于模型对训练数据波动的过度敏感。方差过高意味着模型对
数据中的随机噪声也进行了建模,将本不属于“特征– 标签”关系
中的随机特性也纳入到模型之中,对应着过拟合现象.
V[y^D]=E[(y^D−E[y^D])2]
方差表示由于训练集的变动所导致的学习性能的变化(不稳定性),刻画了数据扰动造成的影响。
偏差-方差分解推导
通常情况下,我们一般使用
L2损失作为我们的损失函数
L(y^D,y)=(y−y^D)2,
注意这里的
y为上面提到的观测值,
y=y∗+η。
令
y=E[y^D],泛化误差定义为损失函数的数学期望:
Err=E[(y−y^D)2]=E[(y^D−(y∗+η))2]=E[(y^D−y∗)2+η2−2η(y^D−y∗)]=E[(y^D−y∗)2]+E[η2]=E[(y^D−y∗)2]+var[η]=E[(y^D−y)+(y−y∗)2]+var[η]=E[(y^D−y)2]+E[(y−y∗)2]+2E[(y^D−y)(y−y∗)]+var[η]=var[y^D]+(y−y∗)2+2(y−y∗)2(E[y^D]−y)+var[η]=var[y^D]+bias2(y^D)+var[η]
即泛化误差可以分解为为预测的偏差的平方、预测的⽅差以及数据的噪声。我们称之为泛化误差的偏差——方差分解。虽然其他损失函数不能解析证明泛化误差可分解为偏差的平方、方差和噪声,但大致趋势相同。
偏差-方差分解表明模型的性能是由模型的拟合能力,数据的充分性以及学习任务本身的难度共同决定的:
- 偏差:度量模型的期望预测与真实结果之间的偏离程度,刻画了模型本身的拟合能力。
- 方差: 度量训练集的变动所导致的模型性能的变化,刻画了数据扰动造成的影响。
- 噪声:度量在当前任务上任何模型所能达到的期望泛化误差的下界,刻画了学习问题本身的难度。
至此,看完了偏差——方差分解,我们已经清楚对于某个任务来说,模型的性能受哪几方面的影响,由于噪声的存在且我们很难去减少噪声,所以主要是从减少模型的偏差(Bagging方法)和减少模型的方差(Boosting等)两方面提高模型的性能,这也是主流集成学习所希望完成的事情。
结合策略
下面简单介绍下集成学习对基学习器几种简单的结合策略,为我们下一篇打下基础。
Geometric Average Rule

Arithmetic Average Rule

Majority Voting Rule


参考文献
- 卿来云,中国科学院大学《模式识别与机器学习》第七章
- 周晓飞,中国科学院大学《机器学习》 第六章