0.怕了怕了,看网络
MobileNet-V2,谷歌,2018年提出(CVPR18)。准确率更好,模型更小。引入了:
- Inverted Residuals
- Linear Bottlenecks
(从论文名字就看出来了:MobileNetV2: Inverted Residuals and Linear Bottlenecks)
1.problem
将数据映射到高维空间,通过非线性层,再映射回来,会有信息损失。映射到高维的维度越高,损失越小。
如图:

由于MobileNet-V1的depthwise convolution是单通道的卷积,然后再通过ReLU会有很大的信息损失。
所以:先升维,升维后每个channel的特征图,都包含了上一层的特征图的信息。然后再ReLU,信息损失就会减小。
2.main contribution
原文:Our main contribution is a novel layer module: the inverted residual with linear bottleneck。
-
就是将 bottleneck 的设计,换成了先升维再降维。刚好相反(inverted)。还有,特征图映射到低维时,用了一个线性的卷积。
具体操作:

-
同时,ResNet, DenseNet 等结构已经证明通过复用图像特征,使用 Concat/Eltwise+ 等操作进行融合,能极大提升网络的性价比。所以用了 resnet 这种的跨层连接。
3.architecture
convolutional blocks 结构如下:
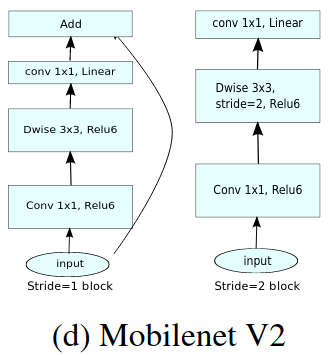
主要解决了ReLU对于低维映射存在信息损失的问题。同时用了ResNet,DenseNet等已经证明的 Eltwise+ / Concat 很好用的跨层连接。