一、初识
在我们日常的计算机处理数据时,都是cpu、主内存、缓存、高速缓存。

不了解RAM的可以参考文章:RAM和ROM的区别
为什么会有高速缓存这个说法?
现在的cpu越来越贵,贵的不是材料,而是每一代的处理运算效率,这个效率的快慢,就在于cpu寄存器、cpu高速缓存的处理效率上,通俗而言,cpu的处理速率是远远高于主内存的处理速率的,为了防止cpu处理速率受限于主内存,所以在cpu和主内存之间加入了高速缓存。
最近有朋友问我知不知道volatile这个关键字,以及这个关键字的作用和底层实现的流程是什么,完全懵逼,所以查找各种资料,大致总结了下volatile关键字的知识。
接下来我们一起学习volatile关键字吧。
二、了解volatile
大家都知道volatile关键字的作用,简单而言,就是为了保证多线程变量副本的可见性。
可能这个概念太抽象了,我们接下来一起看几个demo吧
demo1:无volatile关键字修饰变量
public class VolatilePreDemo {
public static boolean isChanged = false;
public static void main(String[] args) throws InterruptedException {
//开启线程一
new Thread(()->{
System.out.println("等待数据-------");
//死循环 等待数据变更(当全局变量变更,则死循环结束)
while(!isChanged){
}
System.out.println("数据变更了------");
}).start();
//主线程等待
Thread.sleep(3000);
//线程二
new Thread(()->{
changeData();
}).start();
}
public static void changeData(){
System.out.println("数据变更前");
isChanged = true;
System.out.println("数据变更了");
}
}
代码流程的解析:
开启两个线程,线程一死循环等待全局变量的修改,如果修改成功,则打印数据变更了------。
线程二在主线程等待3000毫秒后开启,主要用于修改全局变量值。
运行后的结果:
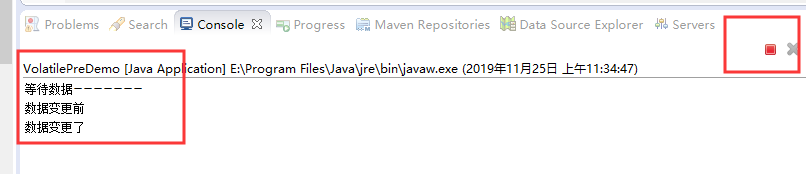
我们发现此时有两个现象:
1、线程二变更了全局变量值,但线程一中的数据并未获取到变更后的操作。(类似数据两者被隔离处理)
2、程序执行后,就一直在运行,没有正常走完。(死循环)
所以可以了解到:
线程二修改的"共享变量"并不会影响到其他内存。
主内存中的"共享变量"加载至各项线程中是副本,并非数据主体本身。

如何才能实现我线程二修改全局变量后,线程一也能收到影响呢?
所以我们接下来一起看volatile
demo2:有volatile关键字修饰变量
public class VolatileDemo {
public static volatile boolean isChanged = false;
public static void main(String[] args) throws InterruptedException {
//开启线程一
new Thread(()->{
System.out.println("等待数据-------");
//死循环 等待数据变更(当全局变量变更,则死循环结束)
while(!isChanged){
}
System.out.println("数据变更了------");
}).start();
//主线程等待
Thread.sleep(3000);
//线程二
new Thread(()->{
changeData();
}).start();
}
public static void changeData(){
System.out.println("数据变更前");
isChanged = true;
System.out.println("数据变更了");
}
}
运行后的结果:

三、JMM(java memory mode)数据原子操作
| 标识 | 名称 | 描述 |
|---|---|---|
| read | 读取 | 从主内存中读取数据 |
| load | 载入 | 将主内存读取到的数据写入工作内存 |
| use | 使用 | 从工作内存读取数据来计算 |
| assign | 赋值 | 将计算好的值重新赋值到工作内存中 |
| store | 存储 | 将工作内存数据写入主内存 |
| write | 写入 | 将store过去的变量值赋值给主内存中的变量 |
| lock | 锁定 | 将主内存变量加锁,标识为线程独占状态 |
| unlock | 解锁 | 将主内存变量解锁,解锁后其他线程可以锁定该变量 |
我们接下来再来看上面的第二个demo。两个线程数据处理分别的流程是什么?
3.1、开始处理数据前

3.2、线程一处理流程

1、程序运行,会将代码加载至内存中。
2、线程一执行,会将变量从主内存(RAM)中读取(read);并载入(load)至工作内存中。
3、cpu会读取工作区中的变量,进行计算,由于isChanged为false,所以此时为死循环,代码会停顿在循环处,不会打印其他信息。
3.3、线程二的处理流程

1、程序运行,会将代码加载至内存中。
2、线程二执行,会将变量从主内存(RAM)中读取(read);
并载入(load)至工作内存中。
3、线程二会使用(use)工作内存中的变量,载入并计算。
4、计算好了之后,将计算好的值重新赋值(assign)到工作内存中。
5、工作内存中的值重新被赋值后,会将值继续存储(store)至主内存中。(此时只是存储在主内存中,并未修改主内存中的数据)
6、将store过去的变量值赋值给主内存中的变量(write)。
以上分析是截至demo1的流程,类比线程一和线程二的流程处理,我们发现,线程二变更了主内存中的“共享变量”,但并未及时的通知线程一(线程一和线程二是两个分开的操作,执行的“共享变量”是副本)。
demo2中全局变量isChanged被volatile修饰,此时在线程二处理完成后,又有了什么操作流程呢?
了解处理流程之前,我们先查看发展历史。参考以下资料:
《总线锁、缓存锁、MESI》
《缓存一致性协议MESI和MOESI》
《并发编程-JMM基础》
在《并发编程-JMM基础》中有说到在多 cpu 下,当其中一个处理器要对共享内存进行操作的时候,在总线上发出一个 LOCK# 信号,这个信号使得其他处理器无法通过总线来访问到共享内存中的数据,总线锁定把 CPU 和内存之间的通信锁住了,这使得锁定期间,其他处理器不能操作其他内存地址的数据,总线锁定的开销比较大,这种机制显然是不合适的。
一大段白话,可能相对难懂,说简单点就是
CPU从主内存中取得数据并放入高速缓存中,会在总线对这个数据加锁,让其他cpu没法去读或写这个数据,直到这个cpu使用完后释放锁,其他cpu才能继续操作该数据。
在使用总线加锁机制操作数据时,其他线程需要操作数据,必须等待拿到数据的那个线程释放锁,性能太低(多核处理数据为并行,加锁类似消息队列挨个进行),所以后续出现了一个新的方式——MESI缓存一致性协议。
MESI缓存一致性协议原理:《总线锁、缓存锁、MESI》
多个cpu从主内存中读取同一个数据到各自的高速缓存区中,当其中某个cpu对这个数据进行了修改操作,该数据会及时同步到主内存中,其他cpu通过总线嗅探机制感知到数据的变化从而将自己高速缓存分区(工作副本) 中的数据失效(只要数据变更经过了总线,则会触发 嗅探/监听 ),然后重新加载。
额外补充总线:
数据传输的共有通道。
关于volatile关键字修饰的变量,像demo2一样,线程二变更“共享变量”信息后,线程一能够嗅探主缓存中的对应变量信息变更,及时的失效自己cpu中的变量信息,重新从主缓存中加载最新的信息值。

如上图所示:
线程二变更了变量,经过store(将工作内存数据写入主内存)操作,由于经过了总线,触发了其他线程对该变量的监听,使得其他线程会失效工作区内的共享变量副本信息,重新从主内存中进行获取新的变量信息。
上面我们了解了MESI缓存一致性协议和==各个线程处理数据时,volatile的处理方式,那么volatile处理“共享资源”的原理是什么呢?
四、volatile实现可见性的原理
此处查看资料:
《volatile底层实现原理和其应用》
《怎么查看Java代码对应的汇编》
《volatile的底层实现原理》
在《volatile的底层实现原理》中,这篇博客讲解了如何查看java代码运行时的汇编语句,其中的demo明确的展示了被volatile关键字修饰的变量在汇编中是如何操作的。
总结上述资料中的各种说法,volatile缓存可见性实现原理为:
底层实现主要是通过汇编lock前缀指令,
他会锁定这块区域的缓存(缓存行锁定)并写回到主内存
IA-32架构软件开发者手册对lock指令的解释:
1、会将当前处理器缓存行的数据立刻写回到系统内存(store、write) —— 不管后面是否还有其他业务代码,都会先同步回主内存。
2、这个写回内存的操作会引起在其他CPU里缓存了该内存地址的数据无效(MESI协议)。
如果上面的解释还是不能理解,可以参考下图的标注:

关于java代码汇编查看和IA-32架构软件开发者手册,可以查看链接:
https://github.com/765199214/java-tools
五、总线加锁和MESI缓存一致性协议的区别
| 名称 | 总线加锁 | MESI |
|---|---|---|
| 加锁区域: | 主内存开始加锁 | store操作之前开始加锁 |
| 释放锁区域: | 主内存释放锁 | 同步后(write操作完成)释放锁 |
MEISI缓存一致性协议为什么需要加lock的操作?
场景一:多个线程执行相同的操作(如:变更全局变量),可能同时会去对主内存进行数据变更操作,此时会出现并发问题。
场景二:store操作到总线时,其他线程操作感知到总线数据的变动,对其所在的线程中的工作内存中的信息进行失效操作。
但此时变量数据变更的操作并未成功执行完主内存中的数据变更(write)。其他线程重新获取的值依旧还是未变更的原始值,并且变更的线程不再触发总线操作了。
同样是都需要进行加锁操作,为什么MESI协议的加锁比总线加锁更好?
1、总线的加锁和释放锁是在主内存中进行的,加锁操作后,需要等待一个线程执行完全的 read–load–use–assign–store–write 流程后,才能释放锁,占据了数据操作的整个流程,极大的占用了系统资源和影响了处理数据的效率问题。
2、MESI协议加锁只是在assign操作,将use操作修改的值重新覆盖至工作内存后,到写回主内存这个流程前后加锁和释放锁,相对总线加锁而言,需要耗时量很小,对其他线程操作数据不存在太大的影响。