概念
以下概念可以结合关系型数据库来理解
| ES | mysql |
|---|---|
| 索引库(index) | 数据库 |
| type | 表 |
| document | 一条数据 |
| field | 字段 |
| mapping映射 | 表结构ddl |
索引库(index) ,document,field 对应Lucene中的相同概念,es底层基于lucene
分片 | 复制
- 高吞吐,高效率
加入一个索引有10亿个文档,占1t空间,一个集群中每个节点都不能消化这1T数据,这样把数据进行切分,例如5片,每一片放置到不同的节点中,可提供es的横向扩展能力;对一个搜索请求,将同时对不同节点上的每一片单独进行搜索,因为每一片对应的是lucene的一个索引库,都具备查询条件,增加了查询的效率。 - 高可用
es对每一片备份,默认是一份,对一个索引来说默认有10片,这10在实际物理存储时,会放在不同的节点中,复制与被复制片又会放置在不同的节点中,这样即使一个服务挂了,es仍然可以提供服务。
基本操作
通过postman和head插件基于es的restful接口进行操作
- 添加index1索引附带映射
PUT http://localhost:9200/index1
{
"mappings":{
"custom":{
"properties":{
"id":{
"type":"long",//类型
"store":true,//是否存储
"index":"not_analyzed"//是否分析
},
"title":{
"type":"text",
"store":true,
"index":"analyzed",
"analyzer":"standard"
},
"content":{
"type":"text",
"store":true,
"index":"analyzed",
"analyzer":"standard"
}
}
}
}
}
- 向索引index1中添加名为custom的type 对应的mapping
post http://localhost:9200/index1/custom/_mappings
{
"custom":{
"properties":{
"id":{
"type":"long",
"store":true,
"index":"not_analyzed"
},
"title":{
"type":"text",
"store":true,
"index":"analyzed",
"analyzer":"standard"
},
"content":{
"type":"text",
"store":true,
"index":"analyzed",
"analyzer":"standard"
}
}
}
}
- 向index1索引下的custom的type添加文档
post http://localhost:9200/index1/custom/1
{
"id":1,
"title":"这是一个文档标题",
"content":"断了的弦"
}
-
根据文档id查询
GET http://localhost:9200/index1/custom/1

-
termQuery进行查询
POST http://localhost:9200/index1/custom/_search
指定域为content
{
"query":{
"term":{
"content":"断"
}
}
}
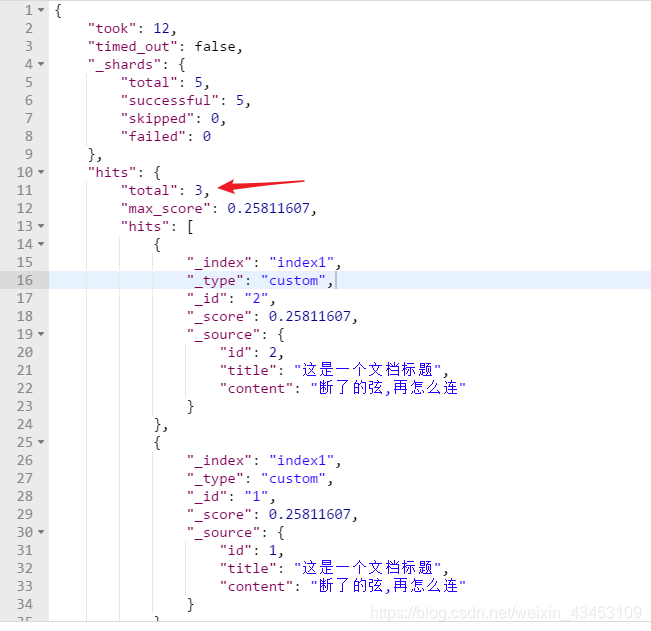
6. queryString进行查询
查询时首先对输入的内容进行分词 , 得到关键词 , 然后再根据关键词查询
POST http://localhost:9200/index1/custom/_search
{
"query":{
"query_string":{
"default_field":"content",
"query":"断了的弦该怎么连我的世界你已听不见"
}
}
}
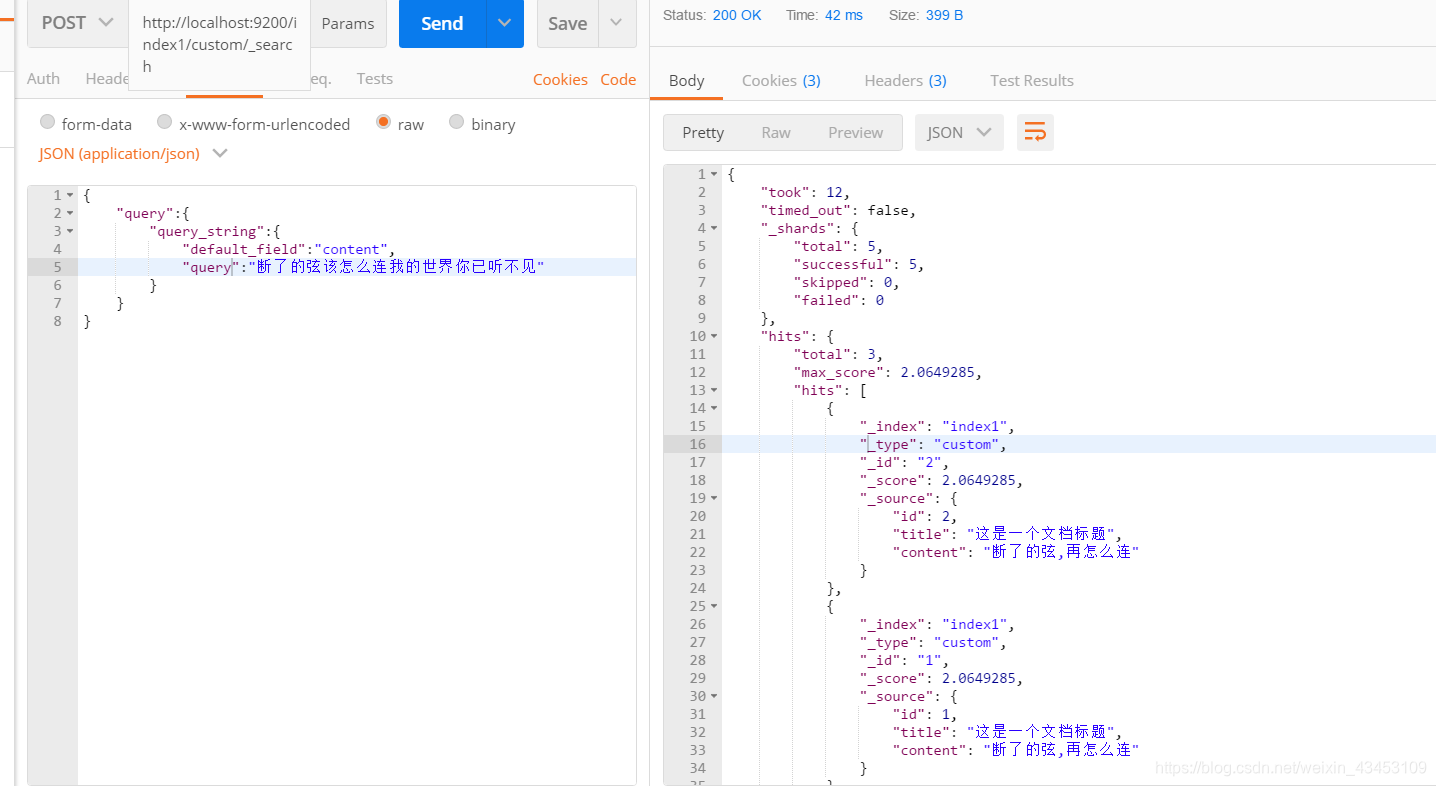
使用head插件的基本查询可以获取到查询语句
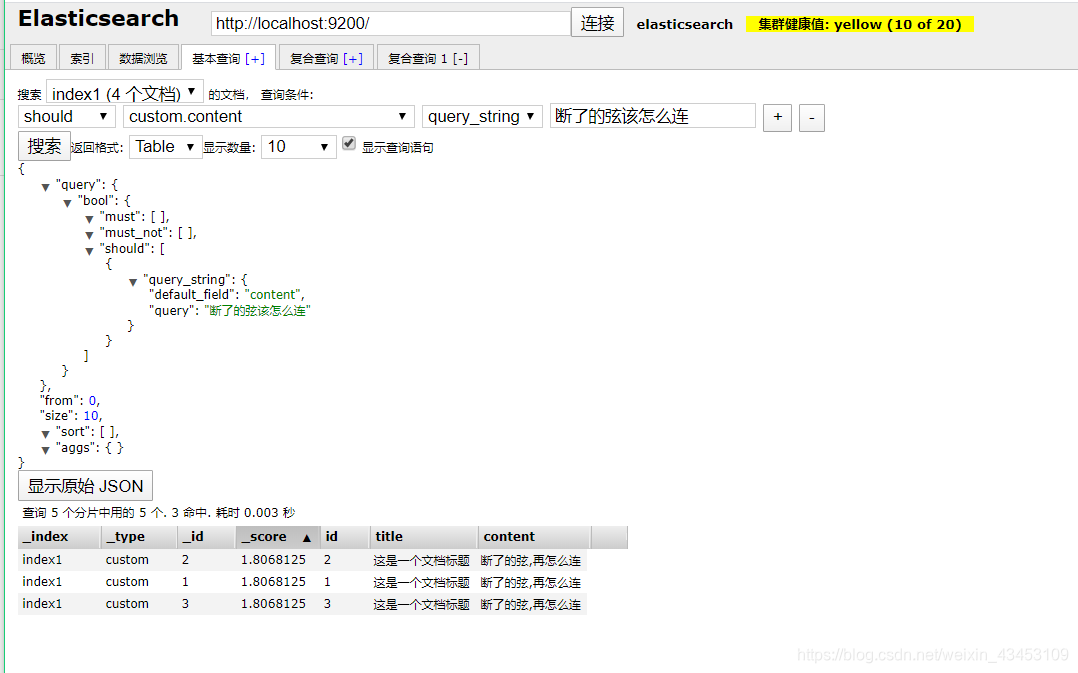
查询分词器效果 , 关键词已经被小写
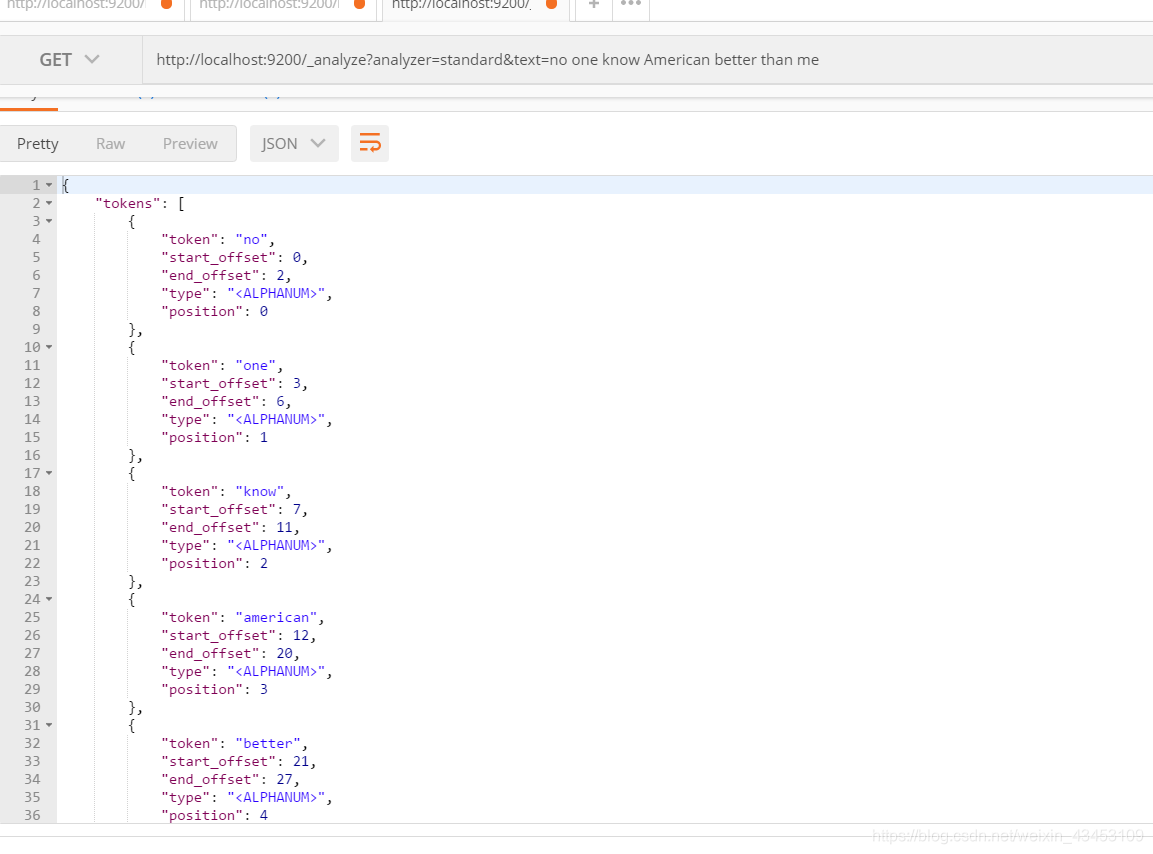
集群
更改config文件夹中的yml
http.cors.enabled: true
http.cors.allow-origin: "*"
#cluster.name可以确定你的集群名称,当你的elasticsearch集群在同一个网段中elasticsearch会自动的找到具有相同cluster.name的elasticsearch服务.
# 所以当同一个网段具有多个elasticsearch集群时cluster.name就成为同一个集群的标识.
cluster.name: my-elasticsearch
# 节点名称 不能出现相同的
node.name: node-1
#绑定监听IP
network.host: 127.0.0.1
# 设置对外服务的http端口,默认为9200
http.port: 9201
# 设置节点间交互的tcp端口,默认是9300
transport.tcp.port: 9301
# 这是一个集群中的主节点的初始列表,当节点(主节点或者数据节点)启动时使用这个列表进行探测
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9301","127.0.0.1:9302"]
启动错误
- access denied …IKAnalyzer.cfg.xml” “read
ailed - recovering as closed
java.security.AccessControlException: access denied (“java.io.FilePermission” “F
:\Program%20Files\ElasticSearch\elasticsearch-5.6.8\plugins\elasticsearch\config
\IKAnalyzer.cfg.xml” “read”)
可能是因为路径中出现了空格
https://blog.csdn.net/weixin_43043173/article/details/86769576 - index索引名称不能有大写

对集群添加索引之后,观察分片位置,边框粗的为原片,对应的复制片都在不同的节点上
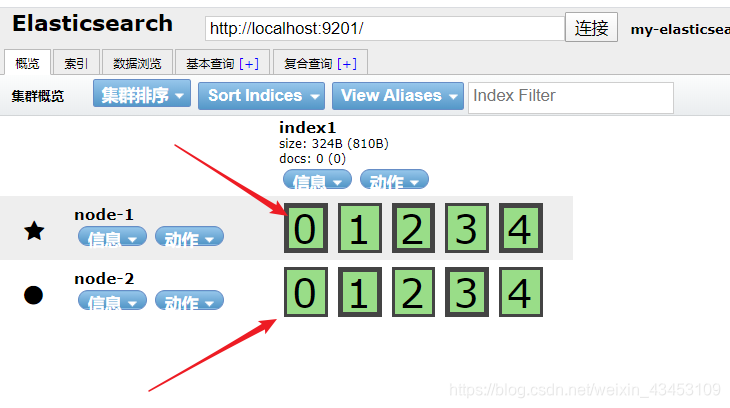
附测试用例
import org.elasticsearch.action.admin.indices.create.CreateIndexResponse;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.common.xcontent.XContentBuilder;
import org.elasticsearch.common.xcontent.XContentFactory;
import org.elasticsearch.index.query.*;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.elasticsearch.transport.client.PreBuiltTransportClient;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.net.InetAddress;
import java.net.UnknownHostException;
import java.util.Iterator;
import java.util.Map;
public class ESClientBasic {
Settings settings;
PreBuiltTransportClient preBuiltTransportClient;
public static void main(String[] args) {
//创建settings对象
Settings settings = Settings.builder().put("cluster.name", "my-elasticsearch").build();
//创建客户端对象 绑定连接的server
PreBuiltTransportClient preBuiltTransportClient = new PreBuiltTransportClient(settings);
try {
preBuiltTransportClient.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9301));
preBuiltTransportClient.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9302));
} catch (UnknownHostException e) {
e.printStackTrace();
}
//创建索引库
CreateIndexResponse response = preBuiltTransportClient.admin().indices().prepareCreate("index_by_client3").get();
String index = response.index();
System.out.println(index);
//关闭流
preBuiltTransportClient.close();
}
@Before
public void before() {
//创建settings对象
settings = Settings.builder().put("cluster.name", "my-elasticsearch").build();
//创建客户端对象 绑定连接的server
preBuiltTransportClient = new PreBuiltTransportClient(settings);
try {
preBuiltTransportClient.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9301));
preBuiltTransportClient.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9302));
} catch (UnknownHostException e) {
e.printStackTrace();
}
}
//添加文档
@Test
public void AddDocument() {
XContentBuilder builder = null;
for (int i = 2; i < 100; i++) {
//创建document文档json
try {
builder = XContentFactory.jsonBuilder()
.startObject()
.field("id", i)
.field("title", "elasticsearch是一个基于lucene的搜索服务" + i)
.field("content", "我只能永远读者对白,读到我给你的伤害 ,我原谅不了我,就请你当作我已不在" + i)
.endObject();
//创建索引库
IndexResponse response = preBuiltTransportClient.prepareIndex()
.setIndex("index_by_client")
.setType("custom")
.setId(i + "").setSource(builder).get();
System.out.println(response.status());
} catch (IOException e) {
e.printStackTrace();
}
}
//关闭流
preBuiltTransportClient.close();
}
//指定文档id查询
@Test
public void searchById() {
//创建查询对象 指定文档id
QueryBuilder queryBuilder = QueryBuilders.idsQuery().addIds("1");
executeQuery(queryBuilder);
}
//根据termquery查询
@Test
public void searchByTermQuery() {
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("content", "我");
executeQuery(termQueryBuilder);
}
//根据queryString查询
@Test
public void searchByQueryString() {
// QueryStringQueryBuilder queryStringQueryBuilder = QueryBuilders.queryStringQuery("5").defaultField("content");
// QueryBuilder queryStringQueryBuilder = QueryBuilders.fuzzyQuery("content", "5");;
//模糊查询
QueryBuilder queryStringQueryBuilder = QueryBuilders.wildcardQuery("content", "*5");
;
executeQuery(queryStringQueryBuilder);
}
//根据queryString查询
@Test
public void searchByQueryStringWithHighlight() {
// QueryStringQueryBuilder queryStringQueryBuilder = QueryBuilders.queryStringQuery("5").defaultField("content");
// QueryBuilder queryStringQueryBuilder = QueryBuilders.fuzzyQuery("content", "5");;
//模糊查询
QueryBuilder queryStringQueryBuilder = QueryBuilders.wildcardQuery("content", "*5");
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("content");
highlightBuilder.preTags("<h1>");
highlightBuilder.postTags("</h1>");
executeQueryWithHighLight(queryStringQueryBuilder, highlightBuilder);
}
private void executeQueryWithHighLight(QueryBuilder queryBuilder, HighlightBuilder highlightBuilder) {
//执行查询 指定索引 , type
SearchResponse response = preBuiltTransportClient.prepareSearch()
.setIndices("index_by_client")
.setTypes("custom")
.setQuery(queryBuilder)
.setFrom(0)
.setSize(10)
.highlighter(highlightBuilder)
.get();
SearchHits hits = response.getHits();
System.out.println(hits.totalHits);
Iterator<SearchHit> iterator = hits.iterator();
while (iterator.hasNext()) {
SearchHit searchHit = iterator.next();
Map<String, Object> document = searchHit.getSource();
System.out.println(document.get("title"));
System.out.println(document.get("content"));
System.out.println("-----------highlight result------");
Map<String, HighlightField> highlightFields = searchHit.getHighlightFields();
System.out.println(highlightFields);
System.out.println("************************************************************");
}
preBuiltTransportClient.close();
}
private void executeQuery(QueryBuilder queryBuilder) {
//执行查询 指定索引 , type
SearchResponse response = preBuiltTransportClient.prepareSearch()
.setIndices("index_by_client")
.setTypes("custom")
.setQuery(queryBuilder)
.setFrom(0)
.setSize(10)
.get();
SearchHits hits = response.getHits();
System.out.println(hits.totalHits);
Iterator<SearchHit> iterator = hits.iterator();
while (iterator.hasNext()) {
SearchHit searchHit = iterator.next();
Map<String, Object> document = searchHit.getSource();
System.out.println(document.get("title"));
System.out.println(document.get("content"));
System.out.println("----------------------------------------");
}
preBuiltTransportClient.close();
}
}
SpringDataES
可能出现的问题
…ine 18 in XML document from class path resource [application.xml] is invalid…elasticsearch:transport-client的声明
这个可能是你的配置文件有问题, 打开编译后的配置文件, 看看哪里是否有报红, 我当时是在网上考了一份xml头, 但是里面有springmvc的约束, 但是我又没有引入springmvc的依赖, 导致解析失败, 编译后的配置文件中es标签头就会报异常, 删除mvc的约束就好了
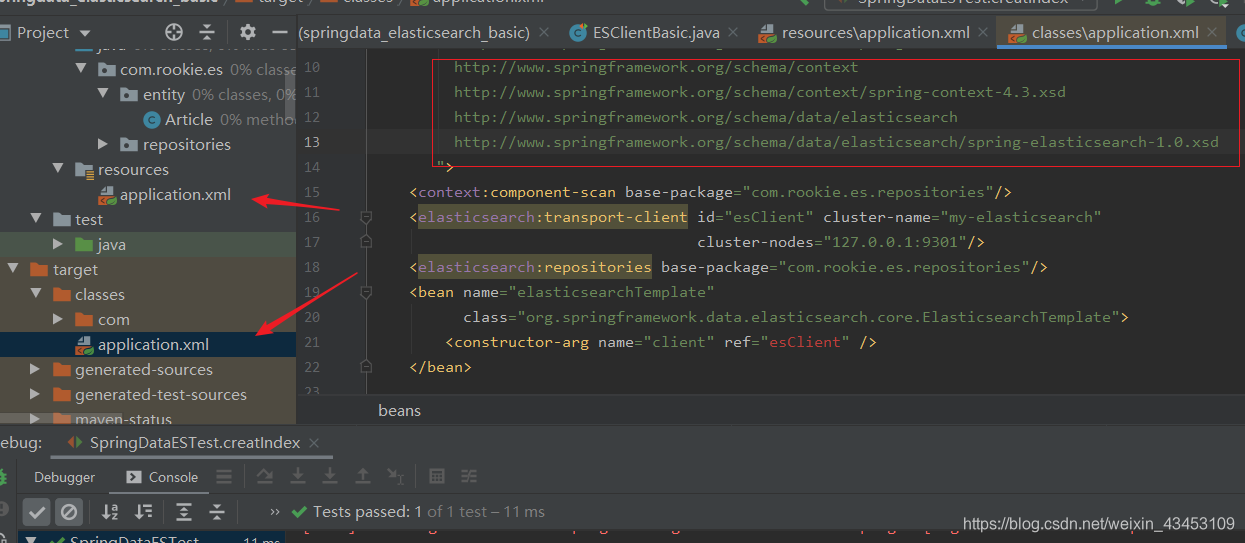
对于索引库中已存在的索引不能再次创建
spring配置文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:elasticsearch="http://www.springframework.org/schema/data/elasticsearch"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-4.3.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-4.3.xsd
http://www.springframework.org/schema/data/elasticsearch
http://www.springframework.org/schema/data/elasticsearch/spring-elasticsearch-1.0.xsd
">
<context:component-scan base-package="com.rookie.es.repositories"/>
<elasticsearch:transport-client id="esClient" cluster-name="my-elasticsearch"
cluster-nodes="127.0.0.1:9301"/>
<elasticsearch:repositories base-package="com.rookie.es.repositories"/>
<bean name="elasticsearchTemplate"
class="org.springframework.data.elasticsearch.core.ElasticsearchTemplate">
<constructor-arg name="client" ref="esClient" />
</bean>
</beans>
实体类
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
@Document(indexName = "index_by_springdataes",type = "custom")
public class Article {
@Id
@Field(store = true,type = FieldType.Long)
private long id;
@Field(store = true,type = FieldType.text)
private String title;
@Field(store=true,type = FieldType.text)
private String content;
@Override
public String toString() {
return "Article{" +
"id=" + id +
", title='" + title + '\'' +
", content='" + content + '\'' +
'}';
}
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
}
dao接口
import com.rookie.es.entity.Article;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
public interface ArticleRepository extends ElasticsearchRepository<Article,Long> {
}
测试用例
import org.elasticsearch.index.query.QueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.elasticsearch.core.ElasticsearchTemplate;
import org.springframework.data.elasticsearch.core.query.NativeSearchQuery;
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import java.util.List;
import java.util.Optional;
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations = "classpath:application.xml")
public class SpringDataESTest {
@Autowired
private ElasticsearchTemplate elasticsearchTemplate;
@Autowired
private ArticleRepository articleRepository;
@Test
public void creatIndex() {
elasticsearchTemplate.createIndex(Article.class);
}
//当id已存在时,操作为更新
@Test
public void addDoc(){
Article article = new Article();
article.setId(4);
article.setTitle("悟空");
// article.setContent("乱世当空,恩怨休怀");
article.setContent("跪一人为师,生死无关");
articleRepository.save(article);
}
@Test
public void delDoc(){
Article article = new Article();
article.setId(1);
article.setTitle("悟空");
article.setContent("乱世当空,恩怨休怀");
articleRepository.delete(article);
}
@Test
public void findAll(){
Iterable<Article> articles = articleRepository.findAll();
articles.forEach(article-> System.out.println(article));
}
@Test
public void findById(){
Optional<Article> optional = articleRepository.findById(1L);
System.out.println(optional.isPresent()?optional.get():"不存在");
}
//通过springdata规范查询,方法名代表api
@Test
public void findByCustomCondition(){
// List<Article> articles = articleRepository.findByTitle("悟空");
// PageRequest pageRequest = PageRequest.of(0, 2);
// List<Article> articles = articleRepository.findByTitleOrContent("悟空","跪一人为师,生死无关",pageRequest);
//这种方式查询关键字和关键字之间属于and关系 因为没有一个content包含以下的所有关键字,所以没有记录
// List<Article> articles = articleRepository.findByContent("叫一声佛祖跪一人为师,生死无关");
//原生api查询关键字和关键字之间属于or关系
NativeSearchQuery nativeSearchQuery = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.queryStringQuery("叫一声佛祖跪一人为师,生死无关")
.defaultField("content"))
.withPageable(PageRequest.of(0,2))
.build();
List<Article> articles = elasticsearchTemplate.queryForList(nativeSearchQuery, Article.class);
articles.forEach(article-> System.out.println(article));
}
}