1. 问题描述:
给你一个由 n 个节点(下标从 0 开始)组成的无向加权图,该图由一个描述边的列表组成,其中 edges[i] = [a, b] 表示连接节点 a 和 b 的一条无向边,且该边遍历成功的概率为 succProb[i] 。指定两个节点分别作为起点 start 和终点 end ,请你找出从起点到终点成功概率最大的路径,并返回其成功概率。如果不存在从 start 到 end 的路径,请 返回 0 。只要答案与标准答案的误差不超过 1e-5 ,就会被视作正确答案。
示例 1:
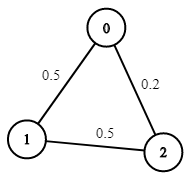
end = 2
输出:0.25000
解释:从起点到终点有两条路径,其中一条的成功概率为 0.2 ,而另一条为 0.5 * 0.5 = 0.25
示例 2:

输入:n = 3, edges = [[0,1],[1,2],[0,2]], succProb = [0.5,0.5,0.3], start = 0, end = 2
输出:0.30000
示例 3:
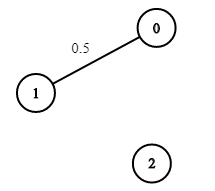
输入:n = 3, edges = [[0,1]], succProb = [0.5], start = 0, end = 2
输出:0.00000
解释:节点 0 和 节点 2 之间不存在路径
提示:
2 <= n <= 10^4
0 <= start, end < n
start != end
0 <= a, b < n
a != b
0 <= succProb.length == edges.length <= 2*10^4
0 <= succProb[i] <= 1
每两个节点之间最多有一条边
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/path-with-maximum-probability
2. 思路分析:
① 从题目中可以知道这是一道关于图论的问题,所以我们可以使用图论中的深度优先搜索或者是广度优先搜索去解决找到这条出现概率最大的路径,一开始使用的是深度优先搜索,也即dfs去解决,但是由于数据量太大了导致栈溢出了,但是使用dfs去解决的思路还是可以学习一下的,以后可能数据量小的时候可以计算出结果来
② dfs可以尝试所有的路径从而最终可以得到从起点到终点概率最大的路径,首先是需要解决图的存储问题,因为给出的边是随意给出来的,而使用dfs我们需要使用下标对应的顶点进行访问,一开始的时候使用的是列表来去解决,这个确实可以解决但是不太方便,后面发现可以使用python中的 defaultdict(list)创建一个字典,这样可以很方便地表示了图中各个节点之间的邻接关系,可以直接在遍历的时候使用下标进行访问,我们以后再存储图的时候就可以直接使用这种方式来存储。因为是无向边所以需要创建两个顶点的双向联系,而且因为是图的访问,所以需要标记当前已经访问过的点,可以避免重复访问节点的问题,这里可以在dfs的方法中传进来一个father参数来表示当前节点的上一个节点,并且可以在if判断中进行去重与限制,整体的思路还是比较好理解的,但是因为题目的数据量比较大所以递归肯定会导致栈的溢出
③ 除了使用dfs解决之外,还可以使用bfs,图的存储也是使用defaultdict(list)创建字典来解决,在遍历的时候直接使用下表访问进行存储,与之前不同宽度优先搜索不同的一个点是这里除了使用字典进行标记已经访问的顶点之外,还需要判断一下已经访问过的顶点是否可能构成概率最大的路径,所以我们在尝试的时候对已经访问过的顶点还需要判断一下,bfs代码是借用了领扣题解中的一位大佬写的,代码写的非常ok,对于理解bfs还是很有好处的,不懂的时候可以自己简单画出一个图来验证一下,并且可以在pycharm进行debug调试对理解也是很有帮助的
3. 代码如下:
bfs:
class Solution:
def maxProbability(self, n: int, edges: List[List[int]], succProb: List[float], start: int, end: int) -> float:
if not edges or not edges[0]: return 0
# 构造节点邻接表
from collections import defaultdict
st_maps = defaultdict(list)
for i, (s, e) in enumerate(edges):
st_maps[s].append((e, succProb[i]))
st_maps[e].append((s, succProb[i]))
ans = 0
queue = deque([(start, 1)])
visited = {start: 0}
while queue:
# 当前节点
cur_node, cur_prob = queue.popleft()
for next_node, p in st_maps[cur_node]:
# 下一个待遍历的节点
next_prob = cur_prob * p
if next_node == end:
ans = max(ans, next_prob)
continue
# 剪枝和去重:如果下一个待遍历节点的概率大于ans && (该节点为遍历过 或 遍历过该节点但是上次的概率比现在小)
if next_prob > ans and (next_node not in visited or visited[next_node] < next_prob):
visited[next_node] = next_prob
queue.append((next_node, next_prob))
return ansdfs:过了10个数据
from typing import List
class Solution:
def maxProbability(self, n: int, edges: List[List[int]], succProb: List[float], start: int, end: int) -> float:
res = 0.0
# 用来标记到达当前顶点符合条件的最大概率
flag = [0.0 for i in range(10005)]
flag[start] = 1.0
def dfs(graph, start, father, end, curpro):
# 到达了终点
if start == end:
# 使用nonlocal来修改局部变量的值
nonlocal res
if res == 0.0:
res = curpro
else: res = max(res, curpro)
length = len(graph[start])
for i in range(length):
now = graph[start][i][0]
t = curpro * graph[start][i][1]
if t < flag[now] and t - res < 10 ** -5: continue
if now != father:
flag[now] = t
dfs(graph, now, start, end, t)
graph = [list() for i in range(n)]
# 下面这个循环是建立无向边的双向联系这样在接下来的dfs才可以直接通过下表进行访问
for i in range(len(edges)):
curlist = list()
curlist.append(edges[i][1])
# 存储当前这条边的概率
curlist.append(succProb[i])
graph[edges[i][0]].append(curlist)
curlist = list()
curlist.append(edges[i][0])
curlist.append(succProb[i])
graph[edges[i][1]].append(curlist)
dfs(graph, start, -1, end, 1.0)
return float(res)