一、 数据库的分类和应用区别
RDBMS:关系型数据库(MySQL)
一个网站最核心的可能就是用户表,当用户表的数据上亿的时候,对单条数据的查询就需要花费很久的时间,有的时候很可能是分钟级别。实际情况可能更复杂:
a 表会在查询的同时被其他连接进行插入和更新操作。
b 查询语句是非常复杂的,例如多表连接查询。
NOSQL:字母上意思为不使用sql,其实有些书上解释为不止是sql。都是一个意思 , 不支持sql语句。(非关系型数据库)
只做大数据的存储,应用场景用来存储非结构化的数据和半结构化的数据。
二、 hbase的特点和特殊概念
hbase是基于Hadoop诞生的大数据海量存储的数据库。
Hbase是采用 key value对的形式进行数据存储的。
最大的缺点,慢。少量的数据 还不如MySQL。当海量的数据的时候,hbases慢的不明显。
当你符合以下情况的时候 主要需求是数据分析,数据单表数据不超过千万的时候 请不要考虑hbase。
下面的情况请优先考虑hbase:
单表数据过千万,数据分析需求较弱,(一般存银行流水,游戏账号行为)。
1.hbase中的特殊概念的介绍:
先从大到小来看hbase的架构
主从架构:
主节点:Master
从节点:RegionServer

client客户端先找到zookeeper,zookeeper再告诉client RegionServer在哪里 Region Server从而直接将数据存储在hdfs中。
1.2 region是什么:
一段数据的集合,hbase中表一般拥有多个region ,region拥有以下几个特点:
region不能跨服务器 一个regionserver上有一个或者多个region。当数量大的时候,hbase会自动拆分region
1.3 regionserver是什么:
就是存放region的容器,一般一个服务器只安装一个regionserver 安装多个也是可以的
1.4 master是什么
不是rs的管理者,master比较接近打杂的。用来进行表创建,表修改,表删除,,,region的移动管理,,,这样做的好处是:减少单点故障。在hbase中主节点挂了,你依然可以正常的读取和存储数据,只是不能新建数据表。
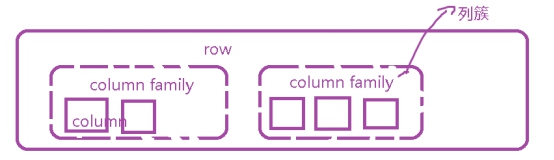
- 存储架构
最基本的单位是列(column),一个或者多个列组成一行(row)。传统的数据库是严格的行列对齐。
Hbase不是,行跟行可以完全不一样,这个行的数据跟另外行的数据也可以存储在不同的机器上,甚至每一行内的数据的列的数量也不一样。
2.1 行键rowkey
Rowkey和MySQL中的主键比起来要容易简单多,完全由用户指定,hbase无法根据某个column来进行排序,rowkey就决定row存储顺序的唯一凭证,这个排序也非常简单:根据字典排序。
例如:输入3条数据:row-1,row-2,row-11,
排序结果:row-1,row-11,row-2
如果新增的时候不小心行键重复了,那么就是修改。
2.1 列簇
若干列组成列簇。(列簇是表的最小单位,一个表至少有1个列簇)
2.2 单元格
列簇中存储的单位 称为单元格。当你使用相同rowkey新增条数据,实质上更新了那条数据
Insert row-1 新增
Insert row-1 修改
上面那条数据原来的值还在不在?还在,单元格有一个特点,支持版本号,原来的值被存储在上一个版本号中,你查询的时候,默认返回最新的版本号的值,如果要查询原来的值,需要加上查询条件 版本号。存储用户上一次的密码,上一次访问的网站等
开集群并切换到tools目录下:

传输文件:

查看上传文件:

解压文件:

进行重命名:

新开一个窗口 打印地址:

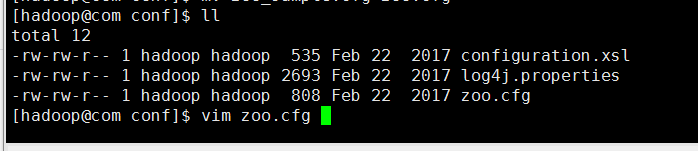
回到第一个窗口 配置zoo.cfg文件:




解压hbase:

切换到HBASE目录下 并查看文件:

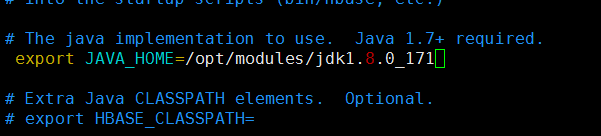

配置log4j.properties:

配置 hbase-site.xml:
<property >
<name>hbase.tmp.dir</name>
<value>/opt/modules/hbase-1.2.0-cdh5.7.6/datas</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://com.hadoop:8020/hbase</value>
</property>
<property>
<name>hbase.fs.tmp.dir</name>
<value>/user/${
user.name}/hbase-staging</value>
</property>
<property >
<name>hbase.bulkload.staging.dir</name>
<value>${hbase.fs.tmp.dir}</value>
</property>
<property >
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>com.hadoop</value>
</property>
配置regionserver:

启动主节点:

启动从节点:

进入cli界面:

关闭节点:

启动所有的集群节点:


进入界面:

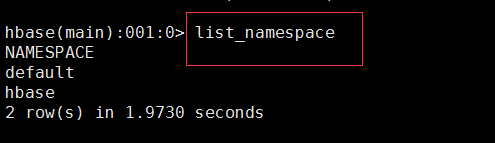
创建命名空间:

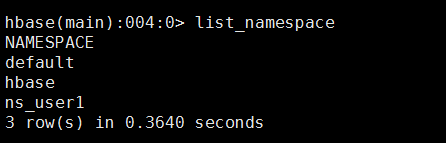
列表显示命名空间:
在默认的命名空间创建一张数据表:

在自定义的命名空间创建一张数据表:

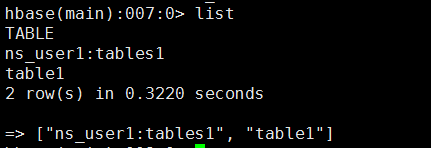
列表显示所有数据表:
添加数据:
put 'ns_user1:table1','110','info:name','jack'
put 'ns_user:table1','110','info:age','18'
put 'ns_user:table1','110','info:gender','1'
扫描全表:
scan 'ns_user:table1'
查看表:
get 'ns_user:table1','110'
get 'ns_user1:table1','110','info:name'
使用flume实现多sinks的数据采集:
创建对应的hbase表:
create 'test','cf'
启动Tomcat进行测试:



配置flume:
能让flume连接到hdfs的原因是:

如何让flume知道hbase在哪里:

将hbase下lib目录中的jar全部拷贝到flume的lib目录下:

编写properties文件:



显示结果: