\qquad
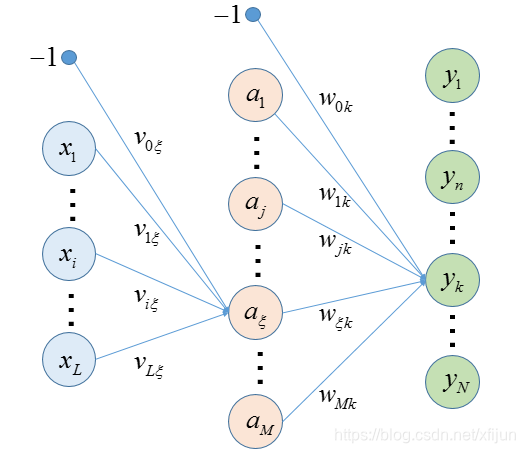
本文只考虑一个隐层的情况。
输入层有
L
L
L
x
i
x_{i}
x i
i
i
i
M
M
M
a
j
a_{j}
a j
j
j
j
N
N
N
y
k
y_{k}
y k
k
k
k
输入层的权值为
v
=
[
v
i
ξ
]
\boldsymbol{v}=[v_{i\xi}]
v = [ v i ξ ]
w
=
[
w
j
k
]
\boldsymbol{w}=[w_{jk}]
w = [ w j k ]
\newline\qquad
\newline
\qquad
ξ
\xi
ξ
a
ξ
a_{\xi}
a ξ
g
(
⋅
)
g(\cdot)
g ( ⋅ )
s
i
g
m
o
i
d
sigmoid
s i g m o i d
\newline
a
ξ
=
g
(
α
ξ
)
=
g
(
∑
i
=
0
L
x
i
v
i
ξ
)
(
1
)
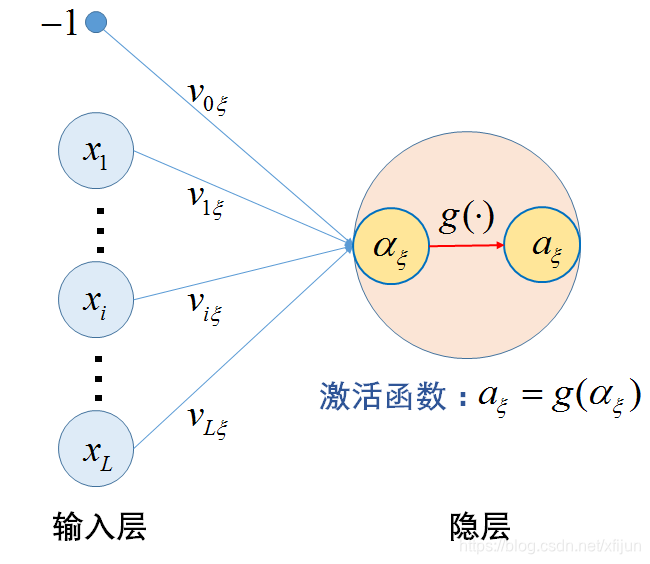
\qquad \qquad a_{\xi}=g(\alpha_{\xi})=g\left(\displaystyle\sum_{i=0}^{L}x_{i}v_{i\xi}\right) \ \qquad\qquad\qquad\qquad\qquad(1)\newline
a ξ = g ( α ξ ) = g ( i = 0 ∑ L x i v i ξ ) ( 1 )
\qquad\qquad
x
0
=
−
1
x_{0}=-1
x 0 = − 1
\newline\qquad\qquad
隐层单元的激活函数
g
(
⋅
)
g(\cdot)
g ( ⋅ )
\qquad
k
k
k
y
k
y_{k}
y k
h
(
⋅
)
h(\cdot)
h ( ⋅ )
\newline
y
k
=
h
(
β
k
)
=
h
(
∑
j
=
0
M
a
j
w
j
k
)
(
2
)
\qquad \qquad y_{k}=h(\beta_{k})=h\left(\displaystyle\sum_{j=0}^{M}a_{j}w_{jk}\right) \qquad\qquad\qquad\qquad\qquad(2)
y k = h ( β k ) = h ( j = 0 ∑ M a j w j k ) ( 2 )
\qquad\qquad
a
0
=
−
1
a_{0}=-1
a 0 = − 1
\newline\qquad\qquad
输出层单元的激活函数
h
(
⋅
)
h(\cdot)
h ( ⋅ )
对于回归问题,
h
(
⋅
)
h(\cdot)
h ( ⋅ )
“
“
“ 恒等函数
”
”
”
h
(
β
k
)
=
β
k
h(\beta_{k})=\beta_{k}
h ( β k ) = β k
对于分类问题,
h
(
⋅
)
h(\cdot)
h ( ⋅ )
“
“
“ softmax函数
”
”
”
h
(
β
k
)
=
e
β
k
∑
n
=
1
N
e
β
n
=
e
β
k
e
β
1
+
⋯
+
e
β
k
+
⋯
+
e
β
N
h(\beta_{k})=\dfrac{e^{\beta_{k}}}{\sum\limits_{n=1}^{N}e^{\beta_{n}}}=\dfrac{e^{\beta_{k}}}{ e^{\beta_{1}}+\cdots+e^{\beta_{k}}+\cdots+e^{\beta_{N}}}
h ( β k ) = n = 1 ∑ N e β n e β k = e β 1 + ⋯ + e β k + ⋯ + e β N e β k
2.1
前
向
传
播
过
程
示
意
图
\boldsymbol{2.1}\ \ \ 前向传播过程示意图\newline
2 . 1 前 向 传 播 过 程 示 意 图
\qquad
(
p
e
r
c
e
p
t
r
o
n
)
(perceptron)
( p e r c e p t r o n )
“
“
“
”
”
”
(
m
u
l
t
i
l
a
y
e
r
p
e
r
c
e
p
t
r
o
n
)
(multilayer\ perceptron)
( m u l t i l a y e r p e r c e p t r o n )
引自Machine Learning - An Algorithmic Perspective 2nd Edition,Fig 4.9
引自Machine Learning - An Algorithmic Perspective 2nd Edition,Fig 4.10
多层感知器的所有参数为
(
v
,
w
)
(\boldsymbol{v}, \boldsymbol{w})
( v , w )
若经过训练的多层感知器的参数为
(
v
,
w
)
(\boldsymbol{v}, \boldsymbol{w})
( v , w )
x
\boldsymbol{x}
x
y
k
(
x
,
v
,
w
)
y_{k}(\boldsymbol{x},\boldsymbol{v}, \boldsymbol{w})
y k ( x , v , w )
y
k
(
x
,
v
,
w
)
=
h
(
∑
j
=
0
M
w
j
k
g
(
∑
i
=
0
L
v
i
j
x
i
)
)
,
k
=
1
,
⋅
⋅
⋅
,
N
(
3
)
\qquad y_{k}(\boldsymbol{x},\boldsymbol{v}, \boldsymbol{w})=h \left( \displaystyle\sum_{j=0}^{M}w_{jk}g\left( \displaystyle\sum_{i=0}^{L}v_{ij}x_{i}\right) \right)\ ,\ k=1,\cdot\cdot\cdot,N\qquad(3)
y k ( x , v , w ) = h ( j = 0 ∑ M w j k g ( i = 0 ∑ L v i j x i ) ) , k = 1 , ⋅ ⋅ ⋅ , N ( 3 )
2.2
s
e
q
u
e
n
t
i
a
l
和
b
a
t
c
h
两
种
训
练
模
式
时
的
数
据
表
示
\boldsymbol{2.2}\ \ \ sequential\ 和\ batch\ 两种训练模式时的数据表示
2 . 2 s e q u e n t i a l 和 b a t c h 两 种 训 练 模 式 时 的 数 据 表 示
s
e
q
u
e
n
t
i
a
l
sequential
s e q u e n t i a l 顺序模式
\newline
\qquad
{
x
,
t
}
\{\boldsymbol{x},\boldsymbol{t}\}
{ x , t }
\qquad
x
∈
R
L
+
1
\boldsymbol{x} \in R^{L+1}
x ∈ R L + 1
x
=
(
x
0
,
x
1
,
⋅
⋅
⋅
,
x
L
)
\boldsymbol{x}=(x_{0},x_{1},\cdot\cdot\cdot,x_{L})
x = ( x 0 , x 1 , ⋅ ⋅ ⋅ , x L )
x
0
=
−
1
x_{0}=-1
x 0 = − 1
\qquad
t
∈
R
N
\boldsymbol{t} \in R^{N}
t ∈ R N
t
=
(
t
1
,
t
2
,
⋅
⋅
⋅
,
t
N
)
\boldsymbol{t}=(t_{1},t_{2},\cdot\cdot\cdot,t_{N})
t = ( t 1 , t 2 , ⋅ ⋅ ⋅ , t N )
\qquad
y
∈
R
N
\boldsymbol{y} \in R^{N}
y ∈ R N
y
=
(
y
1
,
y
2
,
⋅
⋅
⋅
,
y
N
)
\boldsymbol{y}=(y_{1},y_{2},\cdot\cdot\cdot,y_{N})
y = ( y 1 , y 2 , ⋅ ⋅ ⋅ , y N )
\qquad
误差 定义为:
E
=
1
2
∑
k
=
1
N
(
y
k
−
t
k
)
2
E=\dfrac{1}{2}\displaystyle\sum_{k=1}^{N}(y_{k}-t_{k})^{2}
E = 2 1 k = 1 ∑ N ( y k − t k ) 2
\newline
b
a
t
c
h
batch
b a t c h 批处理模式
\newline
\qquad
P
P
P
{
x
(
p
)
,
t
(
p
)
}
p
=
1
P
\{\boldsymbol{x}^{(p)},\boldsymbol{t}^{(p)}\}_{p=1}^{P}
{ x ( p ) , t ( p ) } p = 1 P
\qquad
x
(
p
)
∈
R
L
+
1
\boldsymbol{x}^{(p)} \in R^{L+1}
x ( p ) ∈ R L + 1
x
(
p
)
=
(
x
0
(
p
)
,
x
1
(
p
)
,
⋅
⋅
⋅
,
x
L
(
p
)
)
\boldsymbol{x}^{(p)}=(x_{0}^{(p)},x_{1}^{(p)},\cdot\cdot\cdot,x_{L}^{(p)})
x ( p ) = ( x 0 ( p ) , x 1 ( p ) , ⋅ ⋅ ⋅ , x L ( p ) )
x
0
(
p
)
=
−
1
x_{0}^{(p)}=-1
x 0 ( p ) = − 1
\qquad
t
(
p
)
∈
R
N
\boldsymbol{t}^{(p)} \in R^{N}
t ( p ) ∈ R N
t
(
p
)
=
(
t
1
(
p
)
,
t
2
(
p
)
,
⋅
⋅
⋅
,
t
N
(
p
)
)
\boldsymbol{t}^{(p)}=(t_{1}^{(p)},t_{2}^{(p)},\cdot\cdot\cdot,t_{N}^{(p)})
t ( p ) = ( t 1 ( p ) , t 2 ( p ) , ⋅ ⋅ ⋅ , t N ( p ) )
\qquad
y
(
p
)
∈
R
N
\boldsymbol{y}^{(p)} \in R^{N}
y ( p ) ∈ R N
y
(
p
)
=
(
y
1
(
p
)
,
y
2
(
p
)
,
⋅
⋅
⋅
,
y
N
(
p
)
)
\boldsymbol{y}^{(p)}=(y_{1}^{(p)},y_{2}^{(p)},\cdot\cdot\cdot,y_{N}^{(p)})
y ( p ) = ( y 1 ( p ) , y 2 ( p ) , ⋅ ⋅ ⋅ , y N ( p ) )
\qquad
平均误差 定义为:
E
=
1
2
P
∑
p
=
1
P
(
∑
k
=
1
N
(
y
k
(
p
)
−
t
k
(
p
)
)
2
)
E=\dfrac{1}{2P}\displaystyle\sum_{p=1}^{P}\left( \displaystyle\sum_{k=1}^{N}(y_{k}^{(p)}-t_{k}^{(p)})^{2}\right)
E = 2 P 1 p = 1 ∑ P ( k = 1 ∑ N ( y k ( p ) − t k ( p ) ) 2 )
\newline
2.3
相
关
矩
阵
表
示
\boldsymbol{2.3}\ \ \ 相关矩阵表示
2 . 3 相 关 矩 阵 表 示
3
个
数
据
矩
阵
:
3个数据矩阵:
3 个 数 据 矩 阵 :
1
)
1)
1 ) 输入矩阵 ,第
p
p
p
p
p
p
x
(
p
)
\boldsymbol{x}^{(p)}
x ( p )
“
−
1
”
“-1”
“ − 1 ”
\newline
i
n
p
u
t
s
:
[
x
1
(
1
)
⋯
x
i
(
1
)
⋯
x
L
(
1
)
−
1
⋮
⋮
⋮
⋮
x
1
(
p
)
⋯
x
i
(
p
)
⋯
x
L
(
p
)
−
1
⋮
⋮
⋮
⋮
x
1
(
P
)
⋯
x
i
(
P
)
⋯
x
L
(
P
)
−
1
]
P
×
(
L
+
1
)
⟵
\qquad inputs:\qquad\left[ \begin{matrix} x_{1}^{(1)} & \cdots & x_{i}^{(1)} & \cdots & x_{L}^{(1)} & -1 \\ \vdots & & \vdots & & \vdots & \vdots \\ x_{1}^{(p)} & \cdots & x_{i}^{(p)} & \cdots & x_{L}^{(p)} & -1 \\ \vdots & & \vdots& & \vdots & \vdots \\ x_{1}^{(P)} & \cdots & x_{i}^{(P)} & \cdots & x_{L}^{(P)} & -1 \end{matrix} \right]_{P\times (L+1)} \begin{matrix} \\ \\ \longleftarrow\\ \\ \\ \end{matrix} \newline
i n p u t s : ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ x 1 ( 1 ) ⋮ x 1 ( p ) ⋮ x 1 ( P ) ⋯ ⋯ ⋯ x i ( 1 ) ⋮ x i ( p ) ⋮ x i ( P ) ⋯ ⋯ ⋯ x L ( 1 ) ⋮ x L ( p ) ⋮ x L ( P ) − 1 ⋮ − 1 ⋮ − 1 ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ P × ( L + 1 ) ⟵
2
)
\qquad2)
2 ) 隐层矩阵 ,第
p
p
p
p
p
p
x
(
p
)
\boldsymbol{x}^{(p)}
x ( p )
a
(
p
)
\boldsymbol{a}^{(p)}
a ( p )
“
−
1
”
“-1”
“ − 1 ”
\newline
h
i
d
d
e
n
:
[
a
1
(
1
)
⋯
a
j
(
1
)
⋯
a
M
(
1
)
−
1
⋮
⋮
⋮
⋮
a
1
(
p
)
⋯
a
j
(
p
)
⋯
a
M
(
p
)
−
1
⋮
⋮
⋮
⋮
a
1
(
P
)
⋯
a
j
(
P
)
⋯
a
M
(
P
)
−
1
]
P
×
(
M
+
1
)
⟵
\qquad \qquad hidden:\qquad\left[ \begin{matrix} a_{1}^{(1)} & \cdots & a_{j}^{(1)} & \cdots & a_{M}^{(1)} & -1 \\ \vdots & & \vdots & & \vdots & \vdots \\ a_{1}^{(p)} & \cdots & a_{j}^{(p)} & \cdots & a_{M}^{(p)} & -1 \\ \vdots & & \vdots& & \vdots & \vdots \\ a_{1}^{(P)} & \cdots & a_{j}^{(P)} & \cdots & a_{M}^{(P)} & -1 \end{matrix} \right]_{P\times (M+1)} \begin{matrix} \\ \\ \longleftarrow\\ \\ \\ \end{matrix} \newline
h i d d e n : ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ a 1 ( 1 ) ⋮ a 1 ( p ) ⋮ a 1 ( P ) ⋯ ⋯ ⋯ a j ( 1 ) ⋮ a j ( p ) ⋮ a j ( P ) ⋯ ⋯ ⋯ a M ( 1 ) ⋮ a M ( p ) ⋮ a M ( P ) − 1 ⋮ − 1 ⋮ − 1 ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ P × ( M + 1 ) ⟵
\qquad\qquad
偏置
−
1
-1
− 1
x
(
p
)
\boldsymbol{x}^{(p)}
x ( p )
a
(
p
)
\boldsymbol{a}^{(p)}
a ( p )
\newline
3
)
\qquad 3)
3 ) 输出矩阵 ,第
p
p
p
p
p
p
x
(
p
)
\boldsymbol{x}^{(p)}
x ( p )
y
(
p
)
\boldsymbol{y}^{(p)} \newline
y ( p )
o
u
t
p
u
t
:
[
y
1
(
1
)
⋯
y
k
(
1
)
⋯
y
N
(
1
)
⋮
⋮
⋮
y
1
(
p
)
⋯
y
k
(
p
)
⋯
y
N
(
p
)
⋮
⋮
⋮
y
1
(
P
)
⋯
y
k
(
P
)
⋯
y
N
(
P
)
]
P
×
N
⟵
\qquad \qquad output:\qquad\left[ \begin{matrix} y_{1}^{(1)} & \cdots & y_{k}^{(1)} & \cdots & y_{N}^{(1)} \\ \vdots & & \vdots & & \vdots \\ y_{1}^{(p)} & \cdots & y_{k}^{(p)} & \cdots & y_{N}^{(p)} \\ \vdots & & \vdots& & \vdots \\ y_{1}^{(P)} & \cdots & y_{k}^{(P)} & \cdots & y_{N}^{(P)} \end{matrix} \right]_{P \times N} \begin{matrix} \\ \\ \longleftarrow\\ \\ \\ \end{matrix} \newline
o u t p u t : ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ y 1 ( 1 ) ⋮ y 1 ( p ) ⋮ y 1 ( P ) ⋯ ⋯ ⋯ y k ( 1 ) ⋮ y k ( p ) ⋮ y k ( P ) ⋯ ⋯ ⋯ y N ( 1 ) ⋮ y N ( p ) ⋮ y N ( P ) ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ P × N ⟵
4
)
\qquad 4)
4 ) 目标值矩阵 ,第
p
p
p
p
p
p
x
(
p
)
\boldsymbol{x}^{(p)}
x ( p )
t
(
p
)
\boldsymbol{t}^{(p)} \newline
t ( p )
t
a
r
g
e
t
:
[
t
1
(
1
)
⋯
t
k
(
1
)
⋯
t
N
(
1
)
⋮
⋮
⋮
t
1
(
p
)
⋯
t
k
(
p
)
⋯
t
N
(
p
)
⋮
⋮
⋮
t
1
(
P
)
⋯
t
k
(
P
)
⋯
t
N
(
P
)
]
P
×
N
⟵
\qquad \qquad target:\qquad\left[ \begin{matrix} t_{1}^{(1)} & \cdots & t_{k}^{(1)} & \cdots & t_{N}^{(1)} \\ \vdots & & \vdots & & \vdots \\ t_{1}^{(p)} & \cdots & t_{k}^{(p)} & \cdots & t_{N}^{(p)} \\ \vdots & & \vdots& & \vdots \\ t_{1}^{(P)} & \cdots & t_{k}^{(P)} & \cdots & t_{N}^{(P)} \end{matrix} \right]_{P \times N} \begin{matrix} \\ \\ \longleftarrow\\ \\ \\ \end{matrix} \newline
t a r g e t : ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ t 1 ( 1 ) ⋮ t 1 ( p ) ⋮ t 1 ( P ) ⋯ ⋯ ⋯ t k ( 1 ) ⋮ t k ( p ) ⋮ t k ( P ) ⋯ ⋯ ⋯ t N ( 1 ) ⋮ t N ( p ) ⋮ t N ( P ) ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ P × N ⟵
2
个
系
数
矩
阵
:
2个系数矩阵:
2 个 系 数 矩 阵 :
1
)
1)
1 )
j
j
j
j
j
j 隐层节点 对应于输入层节点的系数
\newline
w
e
i
g
h
t
s
1
:
[
v
11
⋯
v
1
j
⋯
v
1
M
⋮
⋮
⋮
v
i
1
⋯
v
i
j
⋯
v
i
M
⋮
⋮
⋮
v
L
1
⋯
v
L
j
⋯
v
L
M
v
01
⋯
v
0
j
⋯
v
0
M
]
(
L
+
1
)
×
M
\qquad weights1:\qquad\left[ \begin{matrix} v_{11} & \cdots & v_{1j} & \cdots & v_{1M} \\ \vdots & & \vdots & & \vdots \\ v_{i1} & \cdots & v_{ij} & \cdots & v_{iM} \\ \vdots & & \vdots& & \vdots \\ v_{L1} & \cdots & v_{Lj} & \cdots & v_{LM} \\ v_{01} & \cdots & v_{0j} & \cdots & v_{0M} \end{matrix} \right]_{(L+1) \times M}
w e i g h t s 1 : ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ v 1 1 ⋮ v i 1 ⋮ v L 1 v 0 1 ⋯ ⋯ ⋯ ⋯ v 1 j ⋮ v i j ⋮ v L j v 0 j ⋯ ⋯ ⋯ ⋯ v 1 M ⋮ v i M ⋮ v L M v 0 M ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ ( L + 1 ) × M
↑
\qquad \qquad\qquad\qquad\qquad\qquad\qquad\ \ \uparrow \newline
↑
2
)
\qquad 2)
2 )
k
k
k
k
k
k 输出节点 对应于隐层节点的系数
\newline
w
e
i
g
h
t
s
2
:
[
w
11
⋯
w
1
k
⋯
w
1
N
⋮
⋮
⋮
w
j
1
⋯
w
j
k
⋯
w
j
N
⋮
⋮
⋮
w
M
1
⋯
w
M
k
⋯
w
M
N
w
01
⋯
w
0
k
⋯
w
0
N
]
(
M
+
1
)
×
N
\qquad\qquad weights2:\qquad\left[ \begin{matrix} w_{11} & \cdots & w_{1k} & \cdots & w_{1N} \\ \vdots & & \vdots & & \vdots \\ w_{j1} & \cdots & w_{jk} & \cdots & w_{jN} \\ \vdots & & \vdots& & \vdots \\ w_{M1} & \cdots & w_{Mk} & \cdots & w_{MN} \\ w_{01} & \cdots & w_{0k} & \cdots & w_{0N} \end{matrix} \right]_{(M+1) \times N}
w e i g h t s 2 : ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ w 1 1 ⋮ w j 1 ⋮ w M 1 w 0 1 ⋯ ⋯ ⋯ ⋯ w 1 k ⋮ w j k ⋮ w M k w 0 k ⋯ ⋯ ⋯ ⋯ w 1 N ⋮ w j N ⋮ w M N w 0 N ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ ( M + 1 ) × N
↑
\qquad \qquad\qquad\qquad\qquad\qquad\qquad\qquad\ \ \ \ \ \uparrow \newline
↑
2.4
前
向
传
播
过
程
的
实
现
\boldsymbol{2.4}\ \ \ 前向传播过程的实现\newline
2 . 4 前 向 传 播 过 程 的 实 现
\qquad
(
3
)
(3)
( 3 )
\newline
\qquad
i
n
p
u
t
s
P
×
(
L
+
1
)
inputs_{P \times (L+1)}
i n p u t s P × ( L + 1 )
(
P
×
L
(P \times L
( P × L
)
)
) 最后一列 加上值为
−
1
-1
− 1
\newline
\qquad
\qquad
:
:
:
\qquad
[
x
1
(
1
)
⋯
x
i
(
1
)
⋯
x
L
(
1
)
⋮
⋮
⋮
x
1
(
p
)
⋯
x
i
(
p
)
⋯
x
L
(
p
)
⋮
⋮
⋮
x
1
(
P
)
⋯
x
i
(
P
)
⋯
x
L
(
P
)
]
P
×
L
⟵
第
p
个
输
入
的
训
练
数
据
x
(
p
)
\begin{aligned} \qquad\qquad \left[ \begin{matrix} x_{1}^{(1)} & \cdots & x_{i}^{(1)} & \cdots & x_{L}^{(1)} \\ \vdots & & \vdots & & \vdots \\ x_{1}^{(p)} & \cdots & x_{i}^{(p)} & \cdots & x_{L}^{(p)} \\ \vdots & & \vdots& & \vdots \\ x_{1}^{(P)} & \cdots & x_{i}^{(P)} & \cdots & x_{L}^{(P)} \end{matrix} \right] _{P\times L} \begin{matrix} \\ \\ \longleftarrow\\ \\ \\ \end{matrix} \ 第p个输入的训练数据\boldsymbol{x}^{(p)} \end{aligned} \newline
⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ x 1 ( 1 ) ⋮ x 1 ( p ) ⋮ x 1 ( P ) ⋯ ⋯ ⋯ x i ( 1 ) ⋮ x i ( p ) ⋮ x i ( P ) ⋯ ⋯ ⋯ x L ( 1 ) ⋮ x L ( p ) ⋮ x L ( P ) ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ P × L ⟵ 第 p 个 输 入 的 训 练 数 据 x ( p )
\qquad
α
(
p
)
\boldsymbol{\alpha}^{(p)}
α ( p )
i
n
p
u
t
∗
w
e
i
g
h
t
s
1
input *weights1
i n p u t ∗ w e i g h t s 1
(
P
×
M
(P \times M
( P × M
)
)
)
p
p
p
\newline
\qquad
i
n
p
u
t
s
P
×
(
L
+
1
)
∗
w
e
i
g
h
t
s
1
(
L
+
1
)
×
M
=
[
x
1
(
1
)
⋯
x
i
(
1
)
⋯
x
L
(
1
)
−
1
⋮
⋮
⋮
⋮
x
1
(
p
)
⋯
x
i
(
p
)
⋯
x
L
(
p
)
−
1
⋮
⋮
⋮
⋮
x
1
(
P
)
⋯
x
i
(
P
)
⋯
x
L
(
P
)
−
1
]
[
v
11
⋯
v
1
j
⋯
v
1
M
⋮
⋮
⋮
v
i
1
⋯
v
i
j
⋯
v
i
M
⋮
⋮
⋮
v
L
1
⋯
v
L
j
⋯
v
L
M
v
01
⋯
v
0
j
⋯
v
0
M
]
=
[
∑
i
=
0
L
x
i
(
1
)
v
i
1
⋯
∑
i
=
0
L
x
i
(
1
)
v
i
j
⋯
∑
i
=
0
L
x
i
(
1
)
v
i
M
⋮
⋮
⋮
∑
i
=
0
L
x
i
(
p
)
v
i
1
⋯
∑
i
=
0
L
x
i
(
p
)
v
i
j
⋯
∑
i
=
0
L
x
i
(
p
)
v
i
M
⋮
⋮
⋮
∑
i
=
0
L
x
i
(
P
)
v
i
1
⋯
∑
i
=
0
L
x
i
(
P
)
v
i
j
⋯
∑
i
=
0
L
x
i
(
P
)
v
i
M
]
P
×
M
=
[
α
1
(
1
)
⋯
α
j
(
1
)
⋯
α
M
(
1
)
⋮
⋮
⋮
α
1
(
p
)
⋯
α
j
(
p
)
⋯
α
M
(
p
)
⋮
⋮
⋮
α
1
(
P
)
⋯
α
j
(
P
)
⋯
α
M
(
P
)
]
P
×
M
⟵
第
p
个
输
入
x
(
p
)
所
对
应
隐
层
节
点
的
输
入
\begin{aligned} \qquad& inputs_{P\times (L+1)}*weights1_{(L+1) \times M} \\ &= \left[ \begin{matrix} x_{1}^{(1)} & \cdots & x_{i}^{(1)} & \cdots & x_{L}^{(1)} & -1 \\ \vdots & & \vdots & & \vdots & \vdots \\ x_{1}^{(p)} & \cdots & x_{i}^{(p)} & \cdots & x_{L}^{(p)} & -1 \\ \vdots & & \vdots& & \vdots & \vdots \\ x_{1}^{(P)} & \cdots & x_{i}^{(P)} & \cdots & x_{L}^{(P)} & -1 \end{matrix} \right] \left[ \begin{matrix} v_{11} & \cdots & v_{1j} & \cdots & v_{1M} \\ \vdots & & \vdots & & \vdots \\ v_{i1} & \cdots & v_{ij} & \cdots & v_{iM} \\ \vdots & & \vdots& & \vdots \\ v_{L1} & \cdots & v_{Lj} & \cdots & v_{LM} \\ v_{01} & \cdots & v_{0j} & \cdots & v_{0M} \end{matrix} \right] \\ &= \left[ \begin{matrix} \sum\limits_{i=0}^{L} x_{i}^{(1)}v_{i1} & \cdots & \sum\limits_{i=0}^{L} x_{i}^{(1)}v_{ij} & \cdots & \sum\limits_{i=0}^{L} x_{i}^{(1)}v_{iM} \\ \vdots & & \vdots & & \vdots \\ \sum\limits_{i=0}^{L} x_{i}^{(p)}v_{i1} & \cdots & \sum\limits_{i=0}^{L} x_{i}^{(p)}v_{ij} & \cdots & \sum\limits_{i=0}^{L} x_{i}^{(p)}v_{iM} \\ \vdots & & \vdots& & \vdots \\ \sum\limits_{i=0}^{L} x_{i}^{(P)}v_{i1} & \cdots & \sum\limits_{i=0}^{L} x_{i}^{(P)}v_{ij} & \cdots & \sum\limits_{i=0}^{L} x_{i}^{(P)}v_{iM} \end{matrix} \right] _{P\times M} \\ &= \left[ \begin{matrix} \alpha_{1}^{(1)} & \cdots & \alpha_{j}^{(1)} & \cdots & \alpha_{M}^{(1)} \\ \vdots & & \vdots & & \vdots \\ \alpha_{1}^{(p)} & \cdots & \alpha_{j}^{(p)} & \cdots & \alpha_{M}^{(p)} \\ \vdots & & \vdots& & \vdots \\ \alpha_{1}^{(P)} & \cdots & \alpha_{j}^{(P)} & \cdots & \alpha_{M}^{(P)} \end{matrix} \right] _{P\times M} \begin{matrix} \\ \\ \longleftarrow\\ \\ \\ \end{matrix} \ 第p个输入\boldsymbol{x}^{(p)}所对应隐层节点的输入 \end{aligned} \newline
i n p u t s P × ( L + 1 ) ∗ w e i g h t s 1 ( L + 1 ) × M = ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ x 1 ( 1 ) ⋮ x 1 ( p ) ⋮ x 1 ( P ) ⋯ ⋯ ⋯ x i ( 1 ) ⋮ x i ( p ) ⋮ x i ( P ) ⋯ ⋯ ⋯ x L ( 1 ) ⋮ x L ( p ) ⋮ x L ( P ) − 1 ⋮ − 1 ⋮ − 1 ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ v 1 1 ⋮ v i 1 ⋮ v L 1 v 0 1 ⋯ ⋯ ⋯ ⋯ v 1 j ⋮ v i j ⋮ v L j v 0 j ⋯ ⋯ ⋯ ⋯ v 1 M ⋮ v i M ⋮ v L M v 0 M ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ = ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ i = 0 ∑ L x i ( 1 ) v i 1 ⋮ i = 0 ∑ L x i ( p ) v i 1 ⋮ i = 0 ∑ L x i ( P ) v i 1 ⋯ ⋯ ⋯ i = 0 ∑ L x i ( 1 ) v i j ⋮ i = 0 ∑ L x i ( p ) v i j ⋮ i = 0 ∑ L x i ( P ) v i j ⋯ ⋯ ⋯ i = 0 ∑ L x i ( 1 ) v i M ⋮ i = 0 ∑ L x i ( p ) v i M ⋮ i = 0 ∑ L x i ( P ) v i M ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ P × M = ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ α 1 ( 1 ) ⋮ α 1 ( p ) ⋮ α 1 ( P ) ⋯ ⋯ ⋯ α j ( 1 ) ⋮ α j ( p ) ⋮ α j ( P ) ⋯ ⋯ ⋯ α M ( 1 ) ⋮ α M ( p ) ⋮ α M ( P ) ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ P × M ⟵ 第 p 个 输 入 x ( p ) 所 对 应 隐 层 节 点 的 输 入
\qquad
s
i
g
m
o
i
d
sigmoid
s i g m o i d
g
(
⋅
)
g(\cdot)
g ( ⋅ )
a
(
p
)
=
g
(
α
(
p
)
)
\boldsymbol{a}^{(p)}=g(\boldsymbol{\alpha}^{(p)})
a ( p ) = g ( α ( p ) )
\newline
\qquad
\qquad
:
g
(
i
n
p
u
t
s
∗
w
e
i
g
h
t
s
1
)
:g(inputs*weights1)
: g ( i n p u t s ∗ w e i g h t s 1 )
\qquad
g
(
i
n
p
u
t
s
∗
w
e
i
g
h
t
s
1
)
=
g
(
[
α
1
(
1
)
⋯
α
j
(
1
)
⋯
α
M
(
1
)
⋮
⋮
⋮
α
1
(
p
)
⋯
α
j
(
p
)
⋯
α
M
(
p
)
⋮
⋮
⋮
α
1
(
P
)
⋯
α
j
(
P
)
⋯
α
M
(
P
)
]
P
×
M
)
=
[
a
1
(
1
)
⋯
a
j
(
1
)
⋯
a
M
(
1
)
⋮
⋮
⋮
a
1
(
p
)
⋯
a
j
(
p
)
⋯
a
M
(
p
)
⋮
⋮
⋮
a
1
(
P
)
⋯
a
j
(
P
)
⋯
a
M
(
P
)
]
P
×
M
⟵
第
p
个
输
入
x
(
p
)
所
对
应
的
隐
层
节
点
数
据
\begin{aligned} \qquad& g(inputs*weights1) \\ &=g\left( \left[ \begin{matrix} \alpha_{1}^{(1)} & \cdots & \alpha_{j}^{(1)} & \cdots & \alpha_{M}^{(1)} \\ \vdots & & \vdots & & \vdots \\ \alpha_{1}^{(p)} & \cdots & \alpha_{j}^{(p)} & \cdots & \alpha_{M}^{(p)} \\ \vdots & & \vdots& & \vdots \\ \alpha_{1}^{(P)} & \cdots & \alpha_{j}^{(P)} & \cdots & \alpha_{M}^{(P)} \end{matrix} \right] _{P\times M}\right) \\ &=\left[ \begin{matrix} a_{1}^{(1)} & \cdots & a_{j}^{(1)} & \cdots & a_{M}^{(1)} \\ \vdots & & \vdots & & \vdots \\ a_{1}^{(p)} & \cdots & a_{j}^{(p)} & \cdots & a_{M}^{(p)} \\ \vdots & & \vdots& & \vdots \\ a_{1}^{(P)} & \cdots & a_{j}^{(P)} & \cdots & a_{M}^{(P)} \end{matrix} \right] _{P\times M} \begin{matrix} \\ \\ \longleftarrow\\ \\ \\ \end{matrix} \ 第p个输入\boldsymbol{x}^{(p)}所对应的隐层节点数据 \end{aligned} \newline
g ( i n p u t s ∗ w e i g h t s 1 ) = g ⎝ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎛ ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ α 1 ( 1 ) ⋮ α 1 ( p ) ⋮ α 1 ( P ) ⋯ ⋯ ⋯ α j ( 1 ) ⋮ α j ( p ) ⋮ α j ( P ) ⋯ ⋯ ⋯ α M ( 1 ) ⋮ α M ( p ) ⋮ α M ( P ) ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ P × M ⎠ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎞ = ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ a 1 ( 1 ) ⋮ a 1 ( p ) ⋮ a 1 ( P ) ⋯ ⋯ ⋯ a j ( 1 ) ⋮ a j ( p ) ⋮ a j ( P ) ⋯ ⋯ ⋯ a M ( 1 ) ⋮ a M ( p ) ⋮ a M ( P ) ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ P × M ⟵ 第 p 个 输 入 x ( p ) 所 对 应 的 隐 层 节 点 数 据
\qquad
h
i
d
d
e
n
P
×
(
M
+
1
)
hidden_{P \times (M+1)}
h i d d e n P × ( M + 1 )
(
P
×
M
(P \times M
( P × M
)
)
) 最后一列 加上值为
−
1
-1
− 1
\newline
h
i
d
d
e
n
:
[
a
1
(
1
)
⋯
a
j
(
1
)
⋯
a
M
(
1
)
−
1
⋮
⋮
⋮
⋮
a
1
(
p
)
⋯
a
j
(
p
)
⋯
a
M
(
p
)
−
1
⋮
⋮
⋮
⋮
a
1
(
P
)
⋯
a
j
(
P
)
⋯
a
M
(
P
)
−
1
]
⟵
第
p
个
输
入
x
(
p
)
所
对
应
的
隐
层
节
点
数
据
a
(
p
)
\qquad \qquad hidden:\left[ \begin{matrix} a_{1}^{(1)} & \cdots & a_{j}^{(1)} & \cdots & a_{M}^{(1)} & -1 \\ \vdots & & \vdots & & \vdots & \vdots \\ a_{1}^{(p)} & \cdots & a_{j}^{(p)} & \cdots & a_{M}^{(p)} & -1 \\ \vdots & & \vdots& & \vdots & \vdots \\ a_{1}^{(P)} & \cdots & a_{j}^{(P)} & \cdots & a_{M}^{(P)} & -1 \end{matrix} \right] \begin{matrix} \\ \\ \longleftarrow\\ \\ \\ \end{matrix} \ 第p个输入\boldsymbol{x}^{(p)}所对应的隐层节点数据\boldsymbol{a}^{(p)}\newline
h i d d e n : ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ a 1 ( 1 ) ⋮ a 1 ( p ) ⋮ a 1 ( P ) ⋯ ⋯ ⋯ a j ( 1 ) ⋮ a j ( p ) ⋮ a j ( P ) ⋯ ⋯ ⋯ a M ( 1 ) ⋮ a M ( p ) ⋮ a M ( P ) − 1 ⋮ − 1 ⋮ − 1 ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ ⟵ 第 p 个 输 入 x ( p ) 所 对 应 的 隐 层 节 点 数 据 a ( p )
\qquad
β
(
p
)
\boldsymbol{\beta}^{(p)}
β ( p )
h
i
d
d
e
n
∗
w
e
i
g
h
t
s
2
hidden *weights2
h i d d e n ∗ w e i g h t s 2
(
P
×
N
(P \times N
( P × N
)
)
)
p
p
p
\newline
\qquad
h
i
d
d
e
n
P
×
(
M
+
1
)
∗
w
e
i
g
h
t
s
2
(
M
+
1
)
×
N
=
[
a
1
(
1
)
⋯
a
j
(
1
)
⋯
a
M
(
1
)
−
1
⋮
⋮
⋮
⋮
a
1
(
p
)
⋯
a
j
(
p
)
⋯
a
M
(
p
)
−
1
⋮
⋮
⋮
⋮
a
1
(
P
)
⋯
a
j
(
P
)
⋯
a
M
(
P
)
−
1
]
[
w
11
⋯
w
1
k
⋯
w
1
N
⋮
⋮
⋮
w
j
1
⋯
w
j
k
⋯
w
j
N
⋮
⋮
⋮
w
M
1
⋯
w
M
k
⋯
w
M
N
w
01
⋯
w
0
k
⋯
w
0
N
]
=
[
∑
j
=
0
M
a
j
(
1
)
w
j
1
⋯
∑
j
=
0
M
a
j
(
1
)
w
j
k
⋯
∑
j
=
0
M
a
j
(
1
)
w
j
N
⋮
⋮
⋮
∑
j
=
0
M
a
j
(
p
)
w
j
1
⋯
∑
j
=
0
M
a
j
(
p
)
w
j
k
⋯
∑
j
=
0
M
a
j
(
p
)
w
j
N
⋮
⋮
⋮
∑
j
=
0
M
a
j
(
P
)
w
j
1
⋯
∑
j
=
0
M
a
j
(
P
)
w
j
k
⋯
∑
j
=
0
M
a
j
(
P
)
w
j
N
]
P
×
N
=
[
β
1
(
1
)
⋯
β
k
(
1
)
⋯
β
N
(
1
)
⋮
⋮
⋮
β
1
(
p
)
⋯
β
k
(
p
)
⋯
β
N
(
p
)
⋮
⋮
⋮
β
1
(
P
)
⋯
β
k
(
P
)
⋯
β
N
(
P
)
]
P
×
N
⟵
第
p
个
输
入
x
(
p
)
所
对
应
输
出
节
点
的
输
入
\begin{aligned} \qquad& hidden_{P\times (M+1)}*weights2_{(M+1) \times N} \\ &= \left[ \begin{matrix} a_{1}^{(1)} & \cdots & a_{j}^{(1)} & \cdots & a_{M}^{(1)} & -1 \\ \vdots & & \vdots & & \vdots & \vdots \\ a_{1}^{(p)} & \cdots & a_{j}^{(p)} & \cdots & a_{M}^{(p)} & -1 \\ \vdots & & \vdots& & \vdots & \vdots \\ a_{1}^{(P)} & \cdots & a_{j}^{(P)} & \cdots & a_{M}^{(P)} & -1 \end{matrix} \right] \left[ \begin{matrix} w_{11} & \cdots & w_{1k} & \cdots & w_{1N} \\ \vdots & & \vdots & & \vdots \\ w_{j1} & \cdots & w_{jk} & \cdots & w_{jN} \\ \vdots & & \vdots& & \vdots \\ w_{M1} & \cdots & w_{Mk} & \cdots & w_{MN} \\ w_{01} & \cdots & w_{0k} & \cdots & w_{0N} \end{matrix} \right] \\ &= \left[ \begin{matrix} \sum\limits_{j=0}^{M} a_{j}^{(1)}w_{j1} & \cdots & \sum\limits_{j=0}^{M} a_{j}^{(1)}w_{jk} & \cdots & \sum\limits_{j=0}^{M} a_{j}^{(1)}w_{jN} \\ \vdots & & \vdots & & \vdots \\ \sum\limits_{j=0}^{M} a_{j}^{(p)}w_{j1} & \cdots & \sum\limits_{j=0}^{M} a_{j}^{(p)}w_{jk} & \cdots & \sum\limits_{j=0}^{M} a_{j}^{(p)}w_{jN} \\ \vdots & & \vdots& & \vdots \\ \sum\limits_{j=0}^{M} a_{j}^{(P)}w_{j1} & \cdots & \sum\limits_{j=0}^{M} a_{j}^{(P)}w_{jk} & \cdots & \sum\limits_{j=0}^{M} a_{j}^{(P)}w_{jN} \end{matrix} \right] _{P\times N} \\ &= \left[ \begin{matrix} \beta_{1}^{(1)} & \cdots & \beta_{k}^{(1)} & \cdots & \beta_{N}^{(1)} \\ \vdots & & \vdots & & \vdots \\ \beta_{1}^{(p)} & \cdots & \beta_{k}^{(p)} & \cdots & \beta_{N}^{(p)} \\ \vdots & & \vdots& & \vdots \\ \beta_{1}^{(P)} & \cdots & \beta_{k}^{(P)} & \cdots & \beta_{N}^{(P)} \end{matrix} \right] _{P\times N} \begin{matrix} \\ \\ \longleftarrow\\ \\ \\ \end{matrix} \ 第p个输入\boldsymbol{x}^{(p)}所对应输出节点的输入 \end{aligned} \newline
h i d d e n P × ( M + 1 ) ∗ w e i g h t s 2 ( M + 1 ) × N = ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ a 1 ( 1 ) ⋮ a 1 ( p ) ⋮ a 1 ( P ) ⋯ ⋯ ⋯ a j ( 1 ) ⋮ a j ( p ) ⋮ a j ( P ) ⋯ ⋯ ⋯ a M ( 1 ) ⋮ a M ( p ) ⋮ a M ( P ) − 1 ⋮ − 1 ⋮ − 1 ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ w 1 1 ⋮ w j 1 ⋮ w M 1 w 0 1 ⋯ ⋯ ⋯ ⋯ w 1 k ⋮ w j k ⋮ w M k w 0 k ⋯ ⋯ ⋯ ⋯ w 1 N ⋮ w j N ⋮ w M N w 0 N ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ = ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ j = 0 ∑ M a j ( 1 ) w j 1 ⋮ j = 0 ∑ M a j ( p ) w j 1 ⋮ j = 0 ∑ M a j ( P ) w j 1 ⋯ ⋯ ⋯ j = 0 ∑ M a j ( 1 ) w j k ⋮ j = 0 ∑ M a j ( p ) w j k ⋮ j = 0 ∑ M a j ( P ) w j k ⋯ ⋯ ⋯ j = 0 ∑ M a j ( 1 ) w j N ⋮ j = 0 ∑ M a j ( p ) w j N ⋮ j = 0 ∑ M a j ( P ) w j N ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ P × N = ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ β 1 ( 1 ) ⋮ β 1 ( p ) ⋮ β 1 ( P ) ⋯ ⋯ ⋯ β k ( 1 ) ⋮ β k ( p ) ⋮ β k ( P ) ⋯ ⋯ ⋯ β N ( 1 ) ⋮ β N ( p ) ⋮ β N ( P ) ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ P × N ⟵ 第 p 个 输 入 x ( p ) 所 对 应 输 出 节 点 的 输 入
\qquad
h
(
⋅
)
h(\cdot)
h ( ⋅ )
y
(
p
)
=
h
(
β
(
p
)
)
\boldsymbol{y}^{(p)}=h(\boldsymbol{\beta}^{(p)})\newline
y ( p ) = h ( β ( p ) )
\qquad
\qquad
:
h
(
h
i
d
d
e
n
∗
w
e
i
g
h
t
s
2
)
:h(hidden*weights2)
: h ( h i d d e n ∗ w e i g h t s 2 )
\qquad
h
(
h
i
d
d
e
n
∗
w
e
i
g
h
t
s
2
)
=
h
(
[
β
1
(
1
)
⋯
β
k
(
1
)
⋯
β
N
(
1
)
⋮
⋮
⋮
β
1
(
p
)
⋯
β
k
(
p
)
⋯
β
N
(
p
)
⋮
⋮
⋮
β
1
(
P
)
⋯
β
k
(
P
)
⋯
β
N
(
P
)
]
P
×
N
)
=
[
y
1
(
1
)
⋯
y
k
(
1
)
⋯
y
N
(
1
)
⋮
⋮
⋮
y
1
(
p
)
⋯
y
k
(
p
)
⋯
y
N
(
p
)
⋮
⋮
⋮
y
1
(
P
)
⋯
y
k
(
P
)
⋯
y
N
(
P
)
]
P
×
N
⟵
第
p
个
输
入
x
(
p
)
所
对
应
的
输
出
节
点
数
据
\begin{aligned} \qquad& h(hidden*weights2) \\ &=h \left( \left[ \begin{matrix} \beta_{1}^{(1)} & \cdots & \beta_{k}^{(1)} & \cdots & \beta_{N}^{(1)} \\ \vdots & & \vdots & & \vdots \\ \beta_{1}^{(p)} & \cdots & \beta_{k}^{(p)} & \cdots & \beta_{N}^{(p)} \\ \vdots & & \vdots& & \vdots \\ \beta_{1}^{(P)} & \cdots & \beta_{k}^{(P)} & \cdots & \beta_{N}^{(P)} \end{matrix} \right] _{P\times N} \right) \\ &= \left[ \begin{matrix} y_{1}^{(1)} & \cdots & y_{k}^{(1)} & \cdots & y_{N}^{(1)} \\ \vdots & & \vdots & & \vdots \\ y_{1}^{(p)} & \cdots & y_{k}^{(p)} & \cdots & y_{N}^{(p)} \\ \vdots & & \vdots& & \vdots \\ y_{1}^{(P)} & \cdots & y_{k}^{(P)} & \cdots & y_{N}^{(P)} \end{matrix} \right] _{P\times N} \begin{matrix} \\ \\ \longleftarrow\\ \\ \\ \end{matrix} \ 第p个输入\boldsymbol{x}^{(p)}所对应的输出节点数据 \end{aligned} \newline
h ( h i d d e n ∗ w e i g h t s 2 ) = h ⎝ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎛ ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ β 1 ( 1 ) ⋮ β 1 ( p ) ⋮ β 1 ( P ) ⋯ ⋯ ⋯ β k ( 1 ) ⋮ β k ( p ) ⋮ β k ( P ) ⋯ ⋯ ⋯ β N ( 1 ) ⋮ β N ( p ) ⋮ β N ( P ) ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ P × N ⎠ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎞ = ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ y 1 ( 1 ) ⋮ y 1 ( p ) ⋮ y 1 ( P ) ⋯ ⋯ ⋯ y k ( 1 ) ⋮ y k ( p ) ⋮ y k ( P ) ⋯ ⋯ ⋯ y N ( 1 ) ⋮ y N ( p ) ⋮ y N ( P ) ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ P × N ⟵ 第 p 个 输 入 x ( p ) 所 对 应 的 输 出 节 点 数 据
\qquad
h
(
⋅
)
h(\cdot)
h ( ⋅ )
inputs = np. concatenate( ( inputs, - np. ones( ( self. ndata, 1 ) ) ) , axis= 1 )
hidden = np. dot( inputs, weights1)
hidden = 1.0 / ( 1.0 + np. exp( - hidden) )
hidden = np. concatenate( ( hidden, - np. ones( ( np. shape( inputs) [ 0 ] , 1 ) ) ) , axis= 1 )
output = np. dot( hidden, weights2)
\qquad
误差修正学习 ,通过误差在多层感知器中的反向传递,通过调整各层的权值来减小训练误差,权重的调整主要使用梯度下降法 (
η
\eta
η
\newline
\qquad
w
j
k
=
w
j
k
+
Δ
w
j
k
=
w
j
k
−
η
∂
E
∂
w
j
k
(
4
)
w_{jk}=w_{jk} + \Delta w_{jk} = w_{jk}-\eta \dfrac{\partial E}{\partial w_{jk}} \qquad\qquad\qquad(4)\newline
w j k = w j k + Δ w j k = w j k − η ∂ w j k ∂ E ( 4 )
\qquad
v
i
j
=
v
i
j
+
Δ
v
i
j
=
v
i
j
−
η
∂
E
∂
v
i
j
(
5
)
v_{ij}=v_{ij} + \Delta v_{ij} =v_{ij}-\eta \dfrac{\partial E}{\partial v_{ij}} \qquad\qquad\qquad\qquad(5)
v i j = v i j + Δ v i j = v i j − η ∂ v i j ∂ E ( 5 )
3.1
s
e
q
u
e
n
t
i
a
l
模
式
\boldsymbol{3.1}\ \ \ sequential\ 模式\newline
3 . 1 s e q u e n t i a l 模 式
\qquad
单个训练数据 ,前向传播得到输出值之后,再通过误差反向传递来训练所有权值
(
v
,
w
)
\left(\boldsymbol{v},\boldsymbol{w}\right)
( v , w )
\qquad
{
x
,
t
}
\{\boldsymbol{x},\boldsymbol{t}\}
{ x , t }
x
=
(
x
1
,
⋅
⋅
⋅
,
x
L
,
−
1
)
\boldsymbol{x}=(x_{1},\cdot\cdot\cdot,x_{L},-1)
x = ( x 1 , ⋅ ⋅ ⋅ , x L , − 1 )
t
=
(
t
1
,
t
2
,
⋅
⋅
⋅
,
t
N
)
\boldsymbol{t}=(t_{1},t_{2},\cdot\cdot\cdot,t_{N})
t = ( t 1 , t 2 , ⋅ ⋅ ⋅ , t N )
y
=
(
y
1
,
y
2
,
⋅
⋅
⋅
,
y
N
)
\boldsymbol{y}=(y_{1},y_{2},\cdot\cdot\cdot,y_{N})
y = ( y 1 , y 2 , ⋅ ⋅ ⋅ , y N )
\qquad
误差 为:
E
=
1
2
∑
k
=
1
N
(
y
k
−
t
k
)
2
(
6
)
\qquad\qquad E=\dfrac{1}{2}\displaystyle\sum_{k=1}^{N}(y_{k}-t_{k})^{2}\qquad\qquad\qquad\qquad\ \ \ \ \ (6)
E = 2 1 k = 1 ∑ N ( y k − t k ) 2 ( 6 )
\newline
(
a
)
训
练
隐
层
权
值
改
变
量
\boldsymbol{(a)}\ 训练隐层权值改变量
( a ) 训 练 隐 层 权 值 改 变 量
\newline
\qquad
\newline
\qquad\qquad
∂
E
∂
w
j
k
=
∂
E
∂
y
k
∂
y
k
∂
β
k
∂
β
k
∂
w
j
k
=
(
y
k
−
t
k
)
∂
y
k
∂
β
k
∂
β
k
∂
w
j
k
由
β
k
=
∑
j
=
0
M
a
j
w
j
k
=
(
y
k
−
t
k
)
∂
y
k
∂
β
k
a
j
\begin{aligned} \dfrac{\partial E}{ \partial w_{jk} } &= \dfrac{\partial E}{\partial y_{k}} \dfrac{\partial y_{k}}{\partial \beta_{k}} \dfrac{\partial \beta_{k}}{\partial w_{jk}} \\ &= (y_{k}-t_{k}) \dfrac{\partial y_{k}}{\partial \beta_{k}} \dfrac{\partial \beta_{k}}{\partial w_{jk}} \qquad\qquad 由\beta_{k}=\displaystyle\sum_{j=0}^{M}a_{j}w_{jk} \\ &= (y_{k}-t_{k}) \dfrac{\partial y_{k}}{\partial \beta_{k}} a_{j} \end{aligned} \newline
∂ w j k ∂ E = ∂ y k ∂ E ∂ β k ∂ y k ∂ w j k ∂ β k = ( y k − t k ) ∂ β k ∂ y k ∂ w j k ∂ β k 由 β k = j = 0 ∑ M a j w j k = ( y k − t k ) ∂ β k ∂ y k a j
\qquad
h
(
⋅
)
h(\cdot)
h ( ⋅ )
s
o
f
t
m
a
x
softmax
s o f t m a x
y
k
=
h
(
β
k
)
=
e
β
k
∑
n
=
1
N
e
β
n
y_{k}=h(\beta_{k})=\dfrac{e^{\beta_{k}}}{\sum_{n=1}^{N}e^{\beta_{n}}}
y k = h ( β k ) = ∑ n = 1 N e β n e β k
\newline
\qquad\qquad
∂
y
k
∂
β
k
=
(
e
β
k
e
β
1
+
⋯
+
e
β
k
+
⋯
+
e
β
N
)
′
=
e
β
k
(
e
β
1
+
⋯
+
e
β
k
+
⋯
+
e
β
N
)
−
e
β
k
e
β
k
(
e
β
1
+
⋯
+
e
β
k
+
⋯
+
e
β
N
)
2
=
e
β
k
e
β
1
+
⋯
+
e
β
k
+
⋯
+
e
β
N
⋅
(
e
β
1
+
⋯
+
e
β
k
+
⋯
+
e
β
N
)
−
e
β
k
e
β
1
+
⋯
+
e
β
k
+
⋯
+
e
β
N
=
y
k
(
1
−
y
k
)
\begin{aligned} \dfrac{\partial y_{k}}{\partial \beta_{k}} &= \left( \dfrac{e^{\beta_{k}}}{ e^{\beta_{1}}+\cdots+e^{\beta_{k}}+\cdots+e^{\beta_{N}}} \right)^{'} \\ &= \dfrac{e^{\beta_{k}}\left( e^{\beta_{1}}+\cdots+e^{\beta_{k}}+\cdots+e^{\beta_{N}} \right)-e^{\beta_{k}}e^{\beta_{k}}}{\left( e^{\beta_{1}}+\cdots+e^{\beta_{k}}+\cdots+e^{\beta_{N}} \right)^{2}} \\ &=\dfrac{e^{\beta_{k}}}{ e^{\beta_{1}}+\cdots+e^{\beta_{k}}+\cdots+e^{\beta_{N}} } \cdot \dfrac{\left(e^{\beta_{1}}+\cdots+e^{\beta_{k}}+\cdots+e^{\beta_{N}} \right)-e^{\beta_{k}}}{ e^{\beta_{1}}+\cdots+e^{\beta_{k}}+\cdots+e^{\beta_{N}} } \\ &=y_{k}(1-y_{k}) \end{aligned} \newline
∂ β k ∂ y k = ( e β 1 + ⋯ + e β k + ⋯ + e β N e β k ) ′ = ( e β 1 + ⋯ + e β k + ⋯ + e β N ) 2 e β k ( e β 1 + ⋯ + e β k + ⋯ + e β N ) − e β k e β k = e β 1 + ⋯ + e β k + ⋯ + e β N e β k ⋅ e β 1 + ⋯ + e β k + ⋯ + e β N ( e β 1 + ⋯ + e β k + ⋯ + e β N ) − e β k = y k ( 1 − y k )
\qquad
\newline
\qquad\qquad
∂
E
∂
w
j
k
=
(
y
k
−
t
k
)
∂
y
k
∂
β
k
a
j
=
(
y
k
−
t
k
)
y
k
(
1
−
y
k
)
a
j
(
7
)
\begin{aligned} \dfrac{\partial E}{\partial w_{jk} }=(y_{k}-t_{k}) \dfrac{\partial y_{k}}{\partial \beta_{k}} a_{j} =(y_{k}-t_{k})y_{k}(1-y_{k})a_{j} \qquad\qquad\qquad(7) \end{aligned} \newline
∂ w j k ∂ E = ( y k − t k ) ∂ β k ∂ y k a j = ( y k − t k ) y k ( 1 − y k ) a j ( 7 )
(
b
)
训
练
输
入
层
权
值
改
变
量
\boldsymbol{(b)}\ 训练输入层权值改变量
( b ) 训 练 输 入 层 权 值 改 变 量
\newline
\qquad
\newline
\qquad\qquad
E
=
1
2
∑
k
=
1
N
(
y
k
−
t
k
)
2
=
1
2
(
y
1
−
t
1
)
2
+
⋯
+
1
2
(
y
k
−
t
k
)
2
+
⋯
+
1
2
(
y
N
−
t
N
)
2
\begin{aligned} E &=\dfrac{1}{2}\displaystyle\sum_{k=1}^{N}(y_{k}-t_{k})^{2} \\ &=\dfrac{1}{2}(y_{1}-t_{1})^{2}+\cdots+\dfrac{1}{2}(y_{k}-t_{k})^{2}+\cdots+\dfrac{1}{2}(y_{N}-t_{N})^{2} \end{aligned} \newline
E = 2 1 k = 1 ∑ N ( y k − t k ) 2 = 2 1 ( y 1 − t 1 ) 2 + ⋯ + 2 1 ( y k − t k ) 2 + ⋯ + 2 1 ( y N − t N ) 2
\qquad
y
k
=
h
(
β
k
)
=
h
(
∑
j
=
0
M
a
j
w
j
k
)
,
k
=
1
,
2
,
⋯
 
,
N
y_{k}=h(\beta_{k})=h\left( \displaystyle\sum_{j=0}^{M}a_{j}w_{jk} \right)\ ,\ k=1,2,\cdots,N
y k = h ( β k ) = h ( j = 0 ∑ M a j w j k ) , k = 1 , 2 , ⋯ , N
a
j
a_{j}
a j
\qquad
∂
y
k
∂
a
j
=
∂
y
k
∂
β
k
∂
β
k
∂
a
j
=
y
k
(
1
−
y
k
)
w
j
k
\ \ \ \dfrac{\partial y_{k}}{\partial a_{j}} = \dfrac{\partial y_{k}}{\partial \beta_{k}}\dfrac{\partial \beta_{k}} {\partial a_{j}} = y_{k}(1-y_{k})w_{jk} \newline
∂ a j ∂ y k = ∂ β k ∂ y k ∂ a j ∂ β k = y k ( 1 − y k ) w j k
\qquad
\qquad\qquad
∂
E
∂
v
i
j
=
∂
E
∂
y
1
∂
y
1
∂
a
j
∂
a
j
∂
α
j
∂
α
j
∂
v
j
k
+
⋯
+
∂
E
∂
y
k
∂
y
k
∂
a
j
∂
a
j
∂
α
j
∂
α
j
∂
v
j
k
+
⋯
+
∂
E
∂
y
N
∂
y
N
∂
a
j
∂
a
j
∂
α
j
∂
α
j
∂
v
j
k
=
∑
k
=
1
N
∂
E
∂
y
k
∂
y
k
∂
a
j
∂
a
j
∂
α
j
∂
α
j
∂
v
j
k
=
∑
k
=
1
N
(
y
k
−
t
k
)
y
k
(
1
−
y
k
)
w
j
k
∂
a
j
∂
α
j
∂
α
j
∂
v
j
k
由
α
j
=
∑
i
=
0
L
x
i
v
i
j
=
∑
k
=
1
N
(
y
k
−
t
k
)
y
k
(
1
−
y
k
)
w
j
k
∂
a
j
∂
α
j
x
i
\begin{aligned} \dfrac{\partial E}{ \partial v_{ij} } &= \dfrac{\partial E}{\partial y_{1}} \dfrac{\partial y_{1}}{\partial a_{j}} \dfrac{\partial a_{j}}{\partial \alpha_{j}} \dfrac{\partial \alpha_{j}}{\partial v_{jk}} + \cdots + \dfrac{\partial E}{\partial y_{k}} \dfrac{\partial y_{k}}{\partial a_{j}} \dfrac{\partial a_{j}}{\partial \alpha_{j}} \dfrac{\partial \alpha_{j}}{\partial v_{jk}} + \cdots + \dfrac{\partial E}{\partial y_{N}} \dfrac{\partial y_{N}}{\partial a_{j}} \dfrac{\partial a_{j}}{\partial \alpha_{j}} \dfrac{\partial \alpha_{j}}{\partial v_{jk}}\\ &= \sum\limits_{k=1}^{N} \dfrac{\partial E}{\partial y_{k}} \dfrac{\partial y_{k}}{\partial a_{j}} \dfrac{\partial a_{j}}{\partial \alpha_{j}} \dfrac{\partial \alpha_{j}}{\partial v_{jk}} \\ &= \sum\limits_{k=1}^{N}(y_{k}-t_{k}) y_{k}(1-y_{k})w_{jk} \dfrac{\partial a_{j}}{\partial \alpha_{j}} \dfrac{\partial \alpha_{j}}{\partial v_{jk}} \qquad\qquad 由\alpha_{j}=\displaystyle\sum_{i=0}^{L} x_{i} v_{ij} \\ &= \sum\limits_{k=1}^{N}(y_{k}-t_{k}) y_{k}(1-y_{k})w_{jk}\dfrac{\partial a_{j}}{\partial \alpha_{j}} x_{i} \end{aligned} \newline
∂ v i j ∂ E = ∂ y 1 ∂ E ∂ a j ∂ y 1 ∂ α j ∂ a j ∂ v j k ∂ α j + ⋯ + ∂ y k ∂ E ∂ a j ∂ y k ∂ α j ∂ a j ∂ v j k ∂ α j + ⋯ + ∂ y N ∂ E ∂ a j ∂ y N ∂ α j ∂ a j ∂ v j k ∂ α j = k = 1 ∑ N ∂ y k ∂ E ∂ a j ∂ y k ∂ α j ∂ a j ∂ v j k ∂ α j = k = 1 ∑ N ( y k − t k ) y k ( 1 − y k ) w j k ∂ α j ∂ a j ∂ v j k ∂ α j 由 α j = i = 0 ∑ L x i v i j = k = 1 ∑ N ( y k − t k ) y k ( 1 − y k ) w j k ∂ α j ∂ a j x i
\qquad
g
(
⋅
)
g(\cdot)
g ( ⋅ )
s
i
g
m
o
i
d
sigmoid
s i g m o i d
a
j
=
g
(
α
j
)
=
1
1
+
e
−
α
j
a_{j}=g(\alpha_{j})=\dfrac{1}{1+e^{-\alpha_{j}}}
a j = g ( α j ) = 1 + e − α j 1
\newline
\qquad\qquad
∂
a
j
∂
α
j
=
(
1
1
+
e
−
α
j
)
′
=
−
e
−
α
j
(
−
1
)
(
1
+
e
−
α
j
)
2
=
e
−
α
j
(
1
+
e
−
α
j
)
2
=
1
1
+
e
−
α
j
⋅
e
−
α
j
1
+
e
−
α
j
=
a
j
(
1
−
a
j
)
\begin{aligned} \dfrac{\partial a_{j}}{\partial \alpha_{j}} &= \left(\dfrac{1}{1+e^{-\alpha_{j}}} \right)^{'} \\ &= \dfrac{-e^{-\alpha_{j}}(-1)}{\left(1+e^{-\alpha_{j}} \right)^{2}} \\ &= \dfrac{e^{-\alpha_{j}}}{\left(1+e^{-\alpha_{j}} \right)^{2}} \\ &=\dfrac{1}{1+e^{-\alpha_{j}}} \cdot \dfrac{e^{-\alpha_{j}}}{1+e^{-\alpha_{j}}} \\ &=a_{j}(1-a_{j}) \end{aligned} \newline
∂ α j ∂ a j = ( 1 + e − α j 1 ) ′ = ( 1 + e − α j ) 2 − e − α j ( − 1 ) = ( 1 + e − α j ) 2 e − α j = 1 + e − α j 1 ⋅ 1 + e − α j e − α j = a j ( 1 − a j )
\qquad
\qquad\qquad
∂
E
∂
v
i
j
=
∑
k
=
1
N
∂
E
∂
y
k
∂
y
k
∂
a
j
∂
a
j
∂
α
j
∂
α
j
∂
v
j
k
=
∑
k
=
1
N
(
y
k
−
t
k
)
y
k
(
1
−
y
k
)
w
j
k
∂
a
j
∂
α
j
x
i
=
∑
k
=
1
N
(
y
k
−
t
k
)
y
k
(
1
−
y
k
)
w
j
k
a
j
(
1
−
a
j
)
x
i
(
8
)
\begin{aligned} \dfrac{\partial E}{ \partial v_{ij} } &= \sum\limits_{k=1}^{N} \dfrac{\partial E}{\partial y_{k}} \dfrac{\partial y_{k}}{\partial a_{j}} \dfrac{\partial a_{j}}{\partial \alpha_{j}} \dfrac{\partial \alpha_{j}}{\partial v_{jk}} \\ &= \sum\limits_{k=1}^{N}(y_{k}-t_{k}) y_{k}(1-y_{k})w_{jk}\dfrac{\partial a_{j}}{\partial \alpha_{j}} x_{i} \\ &= \sum\limits_{k=1}^{N}(y_{k}-t_{k}) y_{k}(1-y_{k})w_{jk} a_{j}(1-a_{j}) x_{i} \qquad\qquad\qquad(8) \end{aligned} \newline
∂ v i j ∂ E = k = 1 ∑ N ∂ y k ∂ E ∂ a j ∂ y k ∂ α j ∂ a j ∂ v j k ∂ α j = k = 1 ∑ N ( y k − t k ) y k ( 1 − y k ) w j k ∂ α j ∂ a j x i = k = 1 ∑ N ( y k − t k ) y k ( 1 − y k ) w j k a j ( 1 − a j ) x i ( 8 )
\qquad
\newline
\qquad\qquad
δ
o
(
k
)
=
(
y
k
−
t
k
)
y
k
(
1
−
y
k
)
(
9
)
\delta_{o}(k) = (y_{k}-t_{k})y_{k}(1-y_{k})\qquad\qquad\qquad\qquad\qquad\qquad\qquad\ \ (9)\newline
δ o ( k ) = ( y k − t k ) y k ( 1 − y k ) ( 9 )
\qquad\qquad
δ
h
(
j
)
=
a
j
(
1
−
a
j
)
∑
k
=
1
N
δ
o
(
k
)
w
j
k
(
10
)
\delta_{h}(j) = a_{j}(1-a_{j})\sum\limits_{k=1}^{N} \delta_{o}(k)w_{jk}\qquad\qquad\qquad\qquad\qquad\qquad\ \ \ (10) \newline
δ h ( j ) = a j ( 1 − a j ) k = 1 ∑ N δ o ( k ) w j k ( 1 0 )
\qquad
(
7
)
、
(
8
)
(7)、(8)
( 7 ) 、 ( 8 )
\newline
\qquad\qquad
∂
E
∂
w
j
k
=
(
y
k
−
t
k
)
y
k
(
1
−
y
k
)
a
j
=
δ
o
(
k
)
a
j
\dfrac{\partial E}{\partial w_{jk} }=(y_{k}-t_{k})y_{k}(1-y_{k})a_{j}=\delta_{o}(k)a_{j} \newline
∂ w j k ∂ E = ( y k − t k ) y k ( 1 − y k ) a j = δ o ( k ) a j
\qquad\qquad
∂
E
∂
v
i
j
=
∑
k
=
1
N
(
y
k
−
t
k
)
y
k
(
1
−
y
k
)
w
j
k
a
j
(
1
−
a
j
)
x
i
=
δ
h
(
j
)
x
i
(
11
)
\begin{aligned} \dfrac{\partial E}{ \partial v_{ij} } &= \sum\limits_{k=1}^{N}(y_{k}-t_{k}) y_{k}(1-y_{k})w_{jk} a_{j}(1-a_{j}) x_{i} \\ &=\delta_{h}(j) x_{i} \qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\ \ \ \ \ \ (11) \end{aligned} \newline
∂ v i j ∂ E = k = 1 ∑ N ( y k − t k ) y k ( 1 − y k ) w j k a j ( 1 − a j ) x i = δ h ( j ) x i ( 1 1 )
\qquad
(
4
)
(4)
( 4 )
(
5
)
(5)
( 5 )
\newline
\qquad\qquad
w
j
k
=
w
j
k
−
η
∂
E
∂
w
j
k
=
w
j
k
−
η
δ
o
(
k
)
a
j
(
12
)
w_{jk}=w_{jk}-\eta \dfrac{\partial E}{\partial w_{jk}}=w_{jk}-\eta\delta_{o}(k)a_{j}\qquad\qquad\qquad\qquad\qquad(12) \newline
w j k = w j k − η ∂ w j k ∂ E = w j k − η δ o ( k ) a j ( 1 2 )
\qquad\qquad
v
i
j
=
v
i
j
−
η
∂
E
∂
v
i
j
=
v
i
j
−
η
δ
h
(
j
)
x
i
(
13
)
v_{ij}=v_{ij}-\eta \dfrac{\partial E}{\partial v_{ij}}=v_{ij}-\eta\delta_{h}(j) x_{i} \qquad\qquad\qquad\qquad\qquad\ \ \ \ \ \ (13) \newline
v i j = v i j − η ∂ v i j ∂ E = v i j − η δ h ( j ) x i ( 1 3 )
\qquad
总结 :在
s
e
q
u
e
n
t
i
a
l
sequential
s e q u e n t i a l
{
x
(
p
)
,
t
(
p
)
}
p
=
1
P
\{\boldsymbol{x}^{(p)},\boldsymbol{t}^{(p)}\}_{p=1}^{P}
{ x ( p ) , t ( p ) } p = 1 P
{
x
,
t
}
=
{
x
(
p
)
,
t
(
p
)
}
\{\boldsymbol{x},\boldsymbol{t}\}=\{\boldsymbol{x}^{(p)},\boldsymbol{t}^{(p)}\}
{ x , t } = { x ( p ) , t ( p ) }
\newline
\qquad
\newline
1
)
\qquad1)
1 )
{
x
,
t
}
=
{
x
(
p
)
,
t
(
p
)
}
,
p
=
1
\{\boldsymbol{x},\boldsymbol{t}\}=\{\boldsymbol{x}^{(p)},\boldsymbol{t}^{(p)}\},p=1
{ x , t } = { x ( p ) , t ( p ) } , p = 1
2.4
2.4
2 . 4
(
3
)
(3)
( 3 )
y
=
y
(
p
)
(
对
应
2.3
矩
阵
的
第
p
行
)
\boldsymbol{y}=\boldsymbol{y}^{(p)}\left(对应2.3矩阵的第\ p\ 行\right)
y = y ( p ) ( 对 应 2 . 3 矩 阵 的 第 p 行 )
(
6
)
(6)
( 6 )
\newline
2
)
\qquad2)
2 )
(
9
)
(9)
( 9 )
δ
o
(
1
)
,
δ
o
(
2
)
,
⋯
 
,
δ
o
(
N
)
\delta_{o}(1),\delta_{o}(2),\cdots,\delta_{o}(N)
δ o ( 1 ) , δ o ( 2 ) , ⋯ , δ o ( N )
\newline
3
)
\qquad3)
3 )
(
12
)
(12)
( 1 2 )
w
j
k
w_{jk}
w j k
\newline
4
)
\qquad4)
4 )
(
10
)
(10)
( 1 0 )
δ
h
(
1
)
,
δ
h
(
2
)
,
⋯
 
,
δ
h
(
M
)
\delta_{h}(1),\delta_{h}(2),\cdots,\delta_{h}(M)
δ h ( 1 ) , δ h ( 2 ) , ⋯ , δ h ( M )
\newline
5
)
\qquad5)
5 )
(
13
)
(13)
( 1 3 )
v
i
j
v_{ij}
v i j
\newline
6
)
\qquad6)
6 )
p
=
p
+
1
p=p+1
p = p + 1
p
=
P
p=P
p = P
\newline
3.2
b
a
t
c
h
\boldsymbol{3.2}\ \ \ batch
3 . 2 b a t c h
\newline
\qquad
一批训练数据 (假设为
P
P
P
(
v
,
w
)
\left(\boldsymbol{v},\boldsymbol{w}\right)
( v , w )
\qquad
P
P
P
{
x
(
p
)
,
t
(
p
)
}
p
=
1
P
\{\boldsymbol{x}^{(p)},\boldsymbol{t}^{(p)}\}_{p=1}^{P}
{ x ( p ) , t ( p ) } p = 1 P
p
p
p
x
(
p
)
=
(
x
1
(
p
)
,
⋅
⋅
⋅
,
x
L
(
p
)
,
−
1
)
\boldsymbol{x}^{(p)}=(x_{1}^{(p)},\cdot\cdot\cdot,x_{L}^{(p)},-1)
x ( p ) = ( x 1 ( p ) , ⋅ ⋅ ⋅ , x L ( p ) , − 1 )
t
(
p
)
=
(
t
1
(
p
)
,
t
2
(
p
)
,
⋅
⋅
⋅
,
t
N
(
p
)
)
\boldsymbol{t}^{(p)}=(t_{1}^{(p)},t_{2}^{(p)},\cdot\cdot\cdot,t_{N}^{(p)})
t ( p ) = ( t 1 ( p ) , t 2 ( p ) , ⋅ ⋅ ⋅ , t N ( p ) )
y
(
p
)
=
(
y
1
(
p
)
,
y
2
(
p
)
,
⋅
⋅
⋅
,
y
N
(
p
)
)
\boldsymbol{y}^{(p)}=(y_{1}^{(p)},y_{2}^{(p)},\cdot\cdot\cdot,y_{N}^{(p)})
y ( p ) = ( y 1 ( p ) , y 2 ( p ) , ⋅ ⋅ ⋅ , y N ( p ) )
\qquad
平均误差 为:
E
=
1
2
P
∑
p
=
1
P
(
∑
k
=
1
N
(
y
k
(
p
)
−
t
k
(
p
)
)
2
)
(
14
)
\qquad\qquad E=\dfrac{1}{2P}\displaystyle\sum_{p=1}^{P}\left( \displaystyle\sum_{k=1}^{N}(y_{k}^{(p)}-t_{k}^{(p)})^{2}\right) \qquad\qquad\qquad\qquad(14)
E = 2 P 1 p = 1 ∑ P ( k = 1 ∑ N ( y k ( p ) − t k ( p ) ) 2 ) ( 1 4 )
\newline
(
a
)
训
练
隐
层
权
值
改
变
量
\boldsymbol{(a)}\ 训练隐层权值改变量
( a ) 训 练 隐 层 权 值 改 变 量
\newline
\qquad
\newline
\qquad\qquad
E
=
1
2
P
∑
p
=
1
P
(
∑
k
=
1
N
(
y
k
(
p
)
−
t
k
(
p
)
)
2
)
=
1
2
P
∑
k
=
1
N
(
y
k
(
1
)
−
t
k
(
1
)
)
2
+
⋯
+
1
2
P
∑
k
=
1
N
(
y
k
(
p
)
−
t
k
(
p
)
)
2
+
⋯
+
1
2
P
∑
k
=
1
N
(
y
k
(
P
)
−
t
k
(
P
)
)
2
\begin{aligned} E&=\dfrac{1}{2P}\displaystyle\sum_{p=1}^{P}\left( \displaystyle\sum_{k=1}^{N}(y_{k}^{(p)}-t_{k}^{(p)})^{2}\right) \\ &= \dfrac{1}{2P} \displaystyle\sum_{k=1}^{N}(y_{k}^{(1)}-t_{k}^{(1)})^{2}+\cdots+\dfrac{1}{2P} \displaystyle\sum_{k=1}^{N}(y_{k}^{(p)}-t_{k}^{(p)})^{2}+\cdots+\dfrac{1}{2P} \displaystyle\sum_{k=1}^{N}(y_{k}^{(P)}-t_{k}^{(P)})^{2} \\ \end{aligned} \newline
E = 2 P 1 p = 1 ∑ P ( k = 1 ∑ N ( y k ( p ) − t k ( p ) ) 2 ) = 2 P 1 k = 1 ∑ N ( y k ( 1 ) − t k ( 1 ) ) 2 + ⋯ + 2 P 1 k = 1 ∑ N ( y k ( p ) − t k ( p ) ) 2 + ⋯ + 2 P 1 k = 1 ∑ N ( y k ( P ) − t k ( P ) ) 2
\qquad
x
(
p
)
\boldsymbol{x}^{(p)}
x ( p )
y
(
p
)
\boldsymbol{y}^{(p)}
y ( p )
∂
E
∂
w
j
k
\frac{\partial E}{ \partial w_{jk} }
∂ w j k ∂ E
\newline
\qquad
\newline
\qquad\qquad
∂
E
∂
w
j
k
=
∂
E
∂
y
k
(
1
)
∂
y
k
(
1
)
∂
β
k
(
1
)
∂
β
k
(
1
)
∂
w
j
k
+
⋯
+
∂
E
∂
y
k
(
p
)
∂
y
k
(
p
)
∂
β
k
(
p
)
∂
β
k
(
p
)
∂
w
j
k
+
⋯
+
∂
E
∂
y
k
(
P
)
∂
y
k
(
P
)
∂
β
k
(
P
)
∂
β
k
(
P
)
∂
w
j
k
=
∑
p
=
1
P
[
∂
E
∂
y
k
(
p
)
∂
y
k
(
p
)
∂
β
k
(
p
)
∂
β
k
(
p
)
∂
w
j
k
]
由
y
(
p
)
=
h
(
β
k
(
p
)
)
=
h
(
∑
j
=
0
M
a
j
(
p
)
w
j
k
)
=
1
P
∑
p
=
1
P
[
(
y
k
(
p
)
−
t
k
(
p
)
)
∂
y
k
(
p
)
∂
β
k
(
p
)
∂
β
k
(
p
)
∂
w
j
k
]
由
β
k
(
p
)
=
∑
j
=
0
M
a
j
(
p
)
w
j
k
=
1
P
∑
p
=
1
P
[
(
y
k
(
p
)
−
t
k
(
p
)
)
∂
y
k
(
p
)
∂
β
k
(
p
)
a
j
(
p
)
]
\begin{aligned} \dfrac{\partial E}{ \partial w_{jk} } &= \dfrac{\partial E}{\partial y_{k}^{(1)}} \dfrac{\partial y_{k}^{(1)}}{\partial \beta_{k}^{(1)}} \dfrac{\partial \beta_{k}^{(1)}}{\partial w_{jk}} +\cdots+ \dfrac{\partial E}{\partial y_{k}^{(p)}} \dfrac{\partial y_{k}^{(p)}}{\partial \beta_{k}^{(p)}} \dfrac{\partial \beta_{k}^{(p)}}{\partial w_{jk}} + \cdots + \dfrac{\partial E}{\partial y_{k}^{(P)}} \dfrac{\partial y_{k}^{(P)}}{\partial \beta_{k}^{(P)}} \dfrac{\partial \beta_{k}^{(P)}}{\partial w_{jk}} \\ &= \displaystyle\sum_{p=1}^{P} \left[ \dfrac{\partial E}{\partial y_{k}^{(p)}} \dfrac{\partial y_{k}^{(p)}}{\partial \beta_{k}^{(p)}} \dfrac{\partial \beta_{k}^{(p)}}{\partial w_{jk}} \right] \qquad\qquad\qquad\ \ 由y^{(p)}=h(\beta_{k}^{(p)})=h\left(\displaystyle\sum_{j=0}^{M}a_{j}^{(p)}w_{jk} \right) \\ &=\dfrac{1}{P} \displaystyle\sum_{p=1}^{P} \left[ (y_{k}^{(p)} -t_{k}^{(p)}) \dfrac{\partial y_{k}^{(p)}}{\partial \beta_{k}^{(p)}} \dfrac{\partial \beta_{k}^{(p)}}{\partial w_{jk}} \right] \qquad\ \ \ 由\beta_{k}^{(p)}=\displaystyle\sum_{j=0}^{M}a_{j}^{(p)}w_{jk} \\ &=\dfrac{1}{P} \displaystyle\sum_{p=1}^{P} \left[ (y_{k}^{(p)} -t_{k}^{(p)}) \dfrac{\partial y_{k}^{(p)}}{\partial \beta_{k}^{(p)}} a_{j}^{(p)} \right] \end{aligned} \newline
∂ w j k ∂ E = ∂ y k ( 1 ) ∂ E ∂ β k ( 1 ) ∂ y k ( 1 ) ∂ w j k ∂ β k ( 1 ) + ⋯ + ∂ y k ( p ) ∂ E ∂ β k ( p ) ∂ y k ( p ) ∂ w j k ∂ β k ( p ) + ⋯ + ∂ y k ( P ) ∂ E ∂ β k ( P ) ∂ y k ( P ) ∂ w j k ∂ β k ( P ) = p = 1 ∑ P [ ∂ y k ( p ) ∂ E ∂ β k ( p ) ∂ y k ( p ) ∂ w j k ∂ β k ( p ) ] 由 y ( p ) = h ( β k ( p ) ) = h ( j = 0 ∑ M a j ( p ) w j k ) = P 1 p = 1 ∑ P [ ( y k ( p ) − t k ( p ) ) ∂ β k ( p ) ∂ y k ( p ) ∂ w j k ∂ β k ( p ) ] 由 β k ( p ) = j = 0 ∑ M a j ( p ) w j k = P 1 p = 1 ∑ P [ ( y k ( p ) − t k ( p ) ) ∂ β k ( p ) ∂ y k ( p ) a j ( p ) ]
\qquad
h
(
⋅
)
h(\cdot)
h ( ⋅ )
s
o
f
t
m
a
x
softmax
s o f t m a x
y
k
(
p
)
=
h
(
β
k
(
p
)
)
=
e
β
k
(
p
)
∑
n
=
1
N
e
β
n
(
p
)
y_{k}^{(p)}=h(\beta_{k}^{(p)})=\dfrac{e^{\beta_{k}^{(p)}}}{\sum_{n=1}^{N}e^{\beta_{n}^{(p)}}}
y k ( p ) = h ( β k ( p ) ) = ∑ n = 1 N e β n ( p ) e β k ( p )
s
e
q
u
e
n
t
i
a
l
sequential
s e q u e n t i a l
\newline
\qquad\qquad
∂
y
k
(
p
)
∂
β
k
(
p
)
=
y
k
(
p
)
(
1
−
y
k
(
p
)
)
\begin{aligned} \dfrac{\partial y_{k}^{(p)}}{\partial \beta_{k}^{(p)}} &=y_{k}^{(p)}(1-y_{k}^{(p)}) \end{aligned} \newline
∂ β k ( p ) ∂ y k ( p ) = y k ( p ) ( 1 − y k ( p ) )
\qquad
\newline
\qquad\qquad
∂
E
∂
w
j
k
=
1
P
∑
p
=
1
P
[
(
y
k
(
p
)
−
t
k
(
p
)
)
∂
y
k
(
p
)
∂
β
k
(
p
)
a
j
(
p
)
]
=
1
P
∑
p
=
1
P
[
(
y
k
(
p
)
−
t
k
(
p
)
)
y
k
(
p
)
(
1
−
y
k
(
p
)
)
a
j
(
p
)
]
(
15
)
\begin{aligned} \dfrac{\partial E}{\partial w_{jk} }=\dfrac{1}{P}\displaystyle\sum_{p=1}^{P} \left[ (y_{k}^{(p)} -t_{k}^{(p)}) \dfrac{\partial y_{k}^{(p)}}{\partial \beta_{k}^{(p)}} a_{j}^{(p)} \right] = \dfrac{1}{P}\displaystyle\sum_{p=1}^{P} \left[ (y_{k}^{(p)} -t_{k}^{(p)}) y_{k}^{(p)}(1-y_{k}^{(p)}) a_{j}^{(p)} \right] \qquad(15) \end{aligned} \newline
∂ w j k ∂ E = P 1 p = 1 ∑ P [ ( y k ( p ) − t k ( p ) ) ∂ β k ( p ) ∂ y k ( p ) a j ( p ) ] = P 1 p = 1 ∑ P [ ( y k ( p ) − t k ( p ) ) y k ( p ) ( 1 − y k ( p ) ) a j ( p ) ] ( 1 5 )
(
b
)
训
练
输
入
层
权
值
改
变
量
\boldsymbol{(b)}\ 训练输入层权值改变量
( b ) 训 练 输 入 层 权 值 改 变 量
\newline
\qquad
\newline
\qquad\qquad
E
=
1
2
P
∑
p
=
1
P
(
∑
k
=
1
N
(
y
k
(
p
)
−
t
k
(
p
)
)
2
)
=
1
2
P
∑
k
=
1
N
(
y
k
(
1
)
−
t
k
(
1
)
)
2
+
⋯
+
1
2
P
∑
k
=
1
N
(
y
k
(
p
)
−
t
k
(
p
)
)
2
+
⋯
+
1
2
P
∑
k
=
1
N
(
y
k
(
P
)
−
t
k
(
P
)
)
2
\begin{aligned} E&=\dfrac{1}{2P}\displaystyle\sum_{p=1}^{P}\left( \displaystyle\sum_{k=1}^{N}(y_{k}^{(p)}-t_{k}^{(p)})^{2}\right) \\ &= \dfrac{1}{2P} \displaystyle\sum_{k=1}^{N}(y_{k}^{(1)}-t_{k}^{(1)})^{2}+\cdots+\dfrac{1}{2P} \displaystyle\sum_{k=1}^{N}(y_{k}^{(p)}-t_{k}^{(p)})^{2}+\cdots+\dfrac{1}{2P} \displaystyle\sum_{k=1}^{N}(y_{k}^{(P)}-t_{k}^{(P)})^{2} \\ \end{aligned} \newline
E = 2 P 1 p = 1 ∑ P ( k = 1 ∑ N ( y k ( p ) − t k ( p ) ) 2 ) = 2 P 1 k = 1 ∑ N ( y k ( 1 ) − t k ( 1 ) ) 2 + ⋯ + 2 P 1 k = 1 ∑ N ( y k ( p ) − t k ( p ) ) 2 + ⋯ + 2 P 1 k = 1 ∑ N ( y k ( P ) − t k ( P ) ) 2
\qquad
{
x
(
p
)
,
t
(
p
)
}
\{\boldsymbol{x}^{(p)},\boldsymbol{t}^{(p)}\}
{ x ( p ) , t ( p ) }
s
e
q
u
e
n
t
i
a
l
sequential
s e q u e n t i a l
\newline
\qquad\qquad
E
(
p
)
=
1
2
P
∑
k
=
1
N
(
y
k
(
p
)
−
t
k
(
p
)
)
2
=
1
2
P
(
y
1
(
p
)
−
t
1
(
p
)
)
2
+
⋯
+
1
2
P
(
y
k
(
p
)
−
t
k
(
p
)
)
2
+
⋯
+
1
2
P
(
y
N
(
p
)
−
t
N
(
p
)
)
2
\begin{aligned} E^{(p)} &=\dfrac{1}{2P}\displaystyle\sum_{k=1}^{N}(y_{k}^{(p)} -t_{k}^{(p)})^{2} \\ &=\dfrac{1}{2P}(y_{1}^{(p)}-t_{1}^{(p)})^{2}+\cdots+\dfrac{1}{2P}(y_{k}^{(p)}-t_{k}^{(p)})^{2}+\cdots+\dfrac{1}{2P}(y_{N}^{(p)}-t_{N}^{(p)})^{2} \end{aligned} \newline
E ( p ) = 2 P 1 k = 1 ∑ N ( y k ( p ) − t k ( p ) ) 2 = 2 P 1 ( y 1 ( p ) − t 1 ( p ) ) 2 + ⋯ + 2 P 1 ( y k ( p ) − t k ( p ) ) 2 + ⋯ + 2 P 1 ( y N ( p ) − t N ( p ) ) 2
\qquad
y
k
(
p
)
=
h
(
β
k
(
p
)
)
=
h
(
∑
j
=
0
M
a
j
(
p
)
w
j
k
)
,
k
=
1
,
2
,
⋯
 
,
N
y_{k}^{(p)}=h(\beta_{k}^{(p)})=h\left( \displaystyle\sum_{j=0}^{M}a_{j}^{(p)} w_{jk} \right)\ ,\ k=1,2,\cdots,N
y k ( p ) = h ( β k ( p ) ) = h ( j = 0 ∑ M a j ( p ) w j k ) , k = 1 , 2 , ⋯ , N
a
j
(
p
)
a_{j}^{(p)}
a j ( p )
\qquad
∂
y
k
(
p
)
∂
a
j
(
p
)
=
∂
y
k
(
p
)
∂
β
k
(
p
)
∂
β
k
(
p
)
∂
a
j
(
p
)
=
y
k
(
p
)
(
1
−
y
k
(
p
)
)
w
j
k
\ \ \ \dfrac{\partial y_{k}^{(p)}}{\partial a_{j}^{(p)}} = \dfrac{\partial y_{k}^{(p)}}{\partial \beta_{k}^{(p)}}\dfrac{\partial \beta_{k}^{(p)}} {\partial a_{j}^{(p)}} = y_{k}^{(p)}(1-y_{k}^{(p)})w_{jk} \newline
∂ a j ( p ) ∂ y k ( p ) = ∂ β k ( p ) ∂ y k ( p ) ∂ a j ( p ) ∂ β k ( p ) = y k ( p ) ( 1 − y k ( p ) ) w j k
\qquad
\newline
\qquad\qquad
∂
E
(
p
)
∂
v
i
j
=
∂
E
(
p
)
∂
y
1
(
p
)
∂
y
1
(
p
)
∂
a
j
(
p
)
∂
a
j
(
p
)
∂
α
j
(
p
)
∂
α
j
(
p
)
∂
v
j
k
+
⋯
+
∂
E
(
p
)
∂
y
k
(
p
)
∂
y
k
(
p
)
∂
a
j
(
p
)
∂
a
j
(
p
)
∂
α
j
(
p
)
∂
α
j
(
p
)
∂
v
j
k
+
⋯
+
∂
E
(
p
)
∂
y
N
(
p
)
∂
y
N
(
p
)
∂
a
j
(
p
)
∂
a
j
(
p
)
∂
α
j
(
p
)
∂
α
j
(
p
)
∂
v
j
k
=
∑
k
=
1
N
∂
E
(
p
)
∂
y
k
(
p
)
∂
y
k
(
p
)
∂
a
j
(
p
)
∂
a
j
(
p
)
∂
α
j
(
p
)
∂
α
j
(
p
)
∂
v
j
k
由
a
j
(
p
)
=
g
(
α
j
(
p
)
)
=
g
(
∑
i
=
0
L
x
i
(
p
)
v
i
j
)
=
1
P
∑
k
=
1
N
(
y
k
(
p
)
−
t
k
(
p
)
)
y
k
(
p
)
(
1
−
y
k
(
p
)
)
w
j
k
∂
a
j
∂
α
j
∂
α
j
∂
v
j
k
=
1
P
∑
k
=
1
N
(
y
k
(
p
)
−
t
k
(
p
)
)
y
k
(
p
)
(
1
−
y
k
(
p
)
)
w
j
k
∂
a
j
(
p
)
∂
α
j
(
p
)
x
i
(
p
)
\begin{aligned} \dfrac{\partial E^{(p)}}{ \partial v_{ij} } &= \dfrac{\partial E^{(p)}}{\partial y_{1}^{(p)}} \dfrac{\partial y_{1}^{(p)}}{\partial a_{j}^{(p)}} \dfrac{\partial a_{j}^{(p)}}{\partial \alpha_{j}^{(p)}} \dfrac{\partial \alpha_{j}^{(p)}}{\partial v_{jk}} + \cdots + \dfrac{\partial E^{(p)}}{\partial y_{k}^{(p)}} \dfrac{\partial y_{k}^{(p)}}{\partial a_{j}^{(p)}} \dfrac{\partial a_{j}^{(p)}}{\partial \alpha_{j}^{(p)}} \dfrac{\partial \alpha_{j}^{(p)}}{\partial v_{jk}} + \cdots \\ &\qquad + \dfrac{\partial E^{(p)}}{\partial y_{N}^{(p)}} \dfrac{\partial y_{N}^{(p)}}{\partial a_{j}^{(p)}} \dfrac{\partial a_{j}^{(p)}}{\partial \alpha_{j}^{(p)}} \dfrac{\partial \alpha_{j}^{(p)}}{\partial v_{jk}}\\ &= \sum\limits_{k=1}^{N} \dfrac{\partial E^{(p)}}{\partial y_{k}^{(p)}} \dfrac{\partial y_{k}^{(p)}}{\partial a_{j}^{(p)}} \dfrac{\partial a_{j}^{(p)}}{\partial \alpha_{j}^{(p)}} \dfrac{\partial \alpha_{j}^{(p)}}{\partial v_{jk}} \qquad\ \ \ \ \ \ \ \ 由a_{j}^{(p)}=g(\alpha_{j}^{(p)})=g\left(\displaystyle\sum_{i=0}^{L} x_{i}^{(p)} v_{ij}\right) \\ &= \dfrac{1}{P}\sum\limits_{k=1}^{N}(y_{k}^{(p)}-t_{k}^{(p)}) y_{k}^{(p)}(1-y_{k}^{(p)})w_{jk} \dfrac{\partial a_{j}}{\partial \alpha_{j}} \dfrac{\partial \alpha_{j}}{\partial v_{jk}} \\ &= \dfrac{1}{P}\sum\limits_{k=1}^{N}(y_{k}^{(p)}-t_{k}^{(p)}) y_{k}^{(p)}(1-y_{k}^{(p)})w_{jk}\dfrac{\partial a_{j}^{(p)}}{\partial \alpha_{j}^{(p)}} x_{i}^{(p)} \end{aligned} \newline
∂ v i j ∂ E ( p ) = ∂ y 1 ( p ) ∂ E ( p ) ∂ a j ( p ) ∂ y 1 ( p ) ∂ α j ( p ) ∂ a j ( p ) ∂ v j k ∂ α j ( p ) + ⋯ + ∂ y k ( p ) ∂ E ( p ) ∂ a j ( p ) ∂ y k ( p ) ∂ α j ( p ) ∂ a j ( p ) ∂ v j k ∂ α j ( p ) + ⋯ + ∂ y N ( p ) ∂ E ( p ) ∂ a j ( p ) ∂ y N ( p ) ∂ α j ( p ) ∂ a j ( p ) ∂ v j k ∂ α j ( p ) = k = 1 ∑ N ∂ y k ( p ) ∂ E ( p ) ∂ a j ( p ) ∂ y k ( p ) ∂ α j ( p ) ∂ a j ( p ) ∂ v j k ∂ α j ( p ) 由 a j ( p ) = g ( α j ( p ) ) = g ( i = 0 ∑ L x i ( p ) v i j ) = P 1 k = 1 ∑ N ( y k ( p ) − t k ( p ) ) y k ( p ) ( 1 − y k ( p ) ) w j k ∂ α j ∂ a j ∂ v j k ∂ α j = P 1 k = 1 ∑ N ( y k ( p ) − t k ( p ) ) y k ( p ) ( 1 − y k ( p ) ) w j k ∂ α j ( p ) ∂ a j ( p ) x i ( p )
\qquad
g
(
⋅
)
g(\cdot)
g ( ⋅ )
s
i
g
m
o
i
d
sigmoid
s i g m o i d
a
j
(
p
)
=
g
(
α
j
(
p
)
)
=
1
1
+
e
−
α
j
(
p
)
a_{j}^{(p)}=g(\alpha_{j}^{(p)})=\dfrac{1}{1+e^{-\alpha_{j}^{(p)}}}
a j ( p ) = g ( α j ( p ) ) = 1 + e − α j ( p ) 1
\newline
\qquad\qquad
∂
a
j
(
p
)
∂
α
j
(
p
)
=
a
j
(
p
)
(
1
−
a
j
(
p
)
)
\begin{aligned} \dfrac{\partial a_{j}^{(p)}}{\partial \alpha_{j}^{(p)}} =a_{j}^{(p)}(1-a_{j}^{(p)}) \end{aligned} \newline
∂ α j ( p ) ∂ a j ( p ) = a j ( p ) ( 1 − a j ( p ) )
\qquad
\qquad\qquad
∂
E
(
p
)
∂
v
i
j
=
∑
k
=
1
N
∂
E
(
p
)
∂
y
k
(
p
)
∂
y
k
(
p
)
∂
a
j
(
p
)
∂
a
j
(
p
)
∂
α
j
(
p
)
∂
α
j
(
p
)
∂
v
j
k
=
1
P
∑
k
=
1
N
(
y
k
(
p
)
−
t
k
(
p
)
)
y
k
(
p
)
(
1
−
y
k
(
p
)
)
w
j
k
∂
a
j
(
p
)
∂
α
j
(
p
)
x
i
(
p
)
=
1
P
∑
k
=
1
N
(
y
k
(
p
)
−
t
k
(
p
)
)
y
k
(
p
)
(
1
−
y
k
(
p
)
)
w
j
k
a
j
(
p
)
(
1
−
a
j
(
p
)
)
x
i
(
p
)
(
16
)
\begin{aligned} \dfrac{\partial E^{(p)}}{ \partial v_{ij} } &= \sum\limits_{k=1}^{N} \dfrac{\partial E^{(p)}}{\partial y_{k}^{(p)}} \dfrac{\partial y_{k}^{(p)}}{\partial a_{j}^{(p)}} \dfrac{\partial a_{j}^{(p)}}{\partial \alpha_{j}^{(p)}} \dfrac{\partial \alpha_{j}^{(p)}}{\partial v_{jk}} \\ &= \dfrac{1}{P}\sum\limits_{k=1}^{N}(y_{k}^{(p)}-t_{k}^{(p)}) y_{k}^{(p)}(1-y_{k}^{(p)})w_{jk}\dfrac{\partial a_{j}^{(p)}}{\partial \alpha_{j}^{(p)}} x_{i}^{(p)} \\ &= \dfrac{1}{P}\sum\limits_{k=1}^{N}(y_{k}^{(p)}-t_{k}^{(p)}) y_{k}^{(p)}(1-y_{k}^{(p)})w_{jk} a_{j}^{(p)}(1-a_{j}^{(p)}) x_{i}^{(p)} \qquad\ \ \ (16) \end{aligned} \newline
∂ v i j ∂ E ( p ) = k = 1 ∑ N ∂ y k ( p ) ∂ E ( p ) ∂ a j ( p ) ∂ y k ( p ) ∂ α j ( p ) ∂ a j ( p ) ∂ v j k ∂ α j ( p ) = P 1 k = 1 ∑ N ( y k ( p ) − t k ( p ) ) y k ( p ) ( 1 − y k ( p ) ) w j k ∂ α j ( p ) ∂ a j ( p ) x i ( p ) = P 1 k = 1 ∑ N ( y k ( p ) − t k ( p ) ) y k ( p ) ( 1 − y k ( p ) ) w j k a j ( p ) ( 1 − a j ( p ) ) x i ( p ) ( 1 6 )
\qquad
\newline
\qquad\qquad
δ
o
(
p
)
(
k
)
=
1
P
(
y
k
(
p
)
−
t
k
(
p
)
)
y
k
(
p
)
(
1
−
y
k
(
p
)
)
(
17
)
\delta_{o}^{(p)}(k) = \dfrac{1}{P}(y_{k}^{(p)}-t_{k}^{(p)})y_{k}^{(p)}(1-y_{k}^{(p)})\qquad\qquad\qquad\qquad\qquad\qquad\ \ \ \ (17)\newline
δ o ( p ) ( k ) = P 1 ( y k ( p ) − t k ( p ) ) y k ( p ) ( 1 − y k ( p ) ) ( 1 7 )
\qquad\qquad
δ
h
(
p
)
(
j
)
=
a
j
(
p
)
(
1
−
a
j
(
p
)
)
∑
k
=
1
N
δ
o
(
p
)
(
k
)
w
j
k
(
18
)
\begin{aligned} \delta_{h}^{(p)}(j) &= a_{j}^{(p)}(1-a_{j}^{(p)}) \sum\limits_{k=1}^{N} \delta_{o}^{(p)}(k)w_{jk} \qquad\qquad\qquad\qquad\qquad\ \ \ \ \ \ \ \ \ \ \ (18) \end{aligned} \newline
δ h ( p ) ( j ) = a j ( p ) ( 1 − a j ( p ) ) k = 1 ∑ N δ o ( p ) ( k ) w j k ( 1 8 )
\qquad
(
15
)
(15)
( 1 5 )
\newline
\qquad\qquad
∂
E
∂
w
j
k
=
∑
p
=
1
P
∂
E
(
p
)
∂
w
j
k
=
1
P
∑
p
=
1
P
(
y
k
(
p
)
−
t
k
(
p
)
)
y
k
(
p
)
(
1
−
y
k
(
p
)
)
a
j
(
p
)
=
∑
p
=
1
P
δ
o
(
p
)
(
k
)
a
j
(
p
)
(
19
)
\begin{aligned} \dfrac{\partial E}{\partial w_{jk} }&= \sum\limits_{p=1}^{P} \dfrac{\partial E^{(p)}}{\partial w_{jk} } \\ &=\dfrac{1}{P}\sum\limits_{p=1}^{P}(y_{k}^{(p)}-t_{k}^{(p)})y_{k}^{(p)}(1-y_{k}^{(p)})a_{j}^{(p)} \\ &=\sum\limits_{p=1}^{P}\delta_{o}^{(p)}(k)a_{j}^{(p)} \qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\ \ \ \ \ \ \ \ \ \ \ (19) \end{aligned} \newline
∂ w j k ∂ E = p = 1 ∑ P ∂ w j k ∂ E ( p ) = P 1 p = 1 ∑ P ( y k ( p ) − t k ( p ) ) y k ( p ) ( 1 − y k ( p ) ) a j ( p ) = p = 1 ∑ P δ o ( p ) ( k ) a j ( p ) ( 1 9 )
\qquad
(
16
)
(16)
( 1 6 )
\newline
\qquad\qquad
∂
E
(
p
)
∂
v
i
j
=
1
P
∑
k
=
1
N
(
y
k
(
p
)
−
t
k
(
p
)
)
y
k
(
p
)
(
1
−
y
k
(
p
)
)
w
j
k
a
j
(
p
)
(
1
−
a
j
(
p
)
)
x
i
(
p
)
=
a
j
(
p
)
(
1
−
a
j
(
p
)
)
∑
k
=
1
N
δ
o
(
p
)
(
k
)
w
j
k
x
i
(
p
)
=
δ
h
(
p
)
(
j
)
x
i
(
p
)
\begin{aligned} \dfrac{\partial E^{(p)}}{ \partial v_{ij} } &= \dfrac{1}{P}\sum\limits_{k=1}^{N}(y_{k}^{(p)}-t_{k}^{(p)}) y_{k}^{(p)}(1-y_{k}^{(p)})w_{jk} a_{j}^{(p)}(1-a_{j}^{(p)}) x_{i}^{(p)} \\ &= a_{j}^{(p)}(1-a_{j}^{(p)}) \sum\limits_{k=1}^{N} \delta_{o}^{(p)}(k) w_{jk} x_{i}^{(p)} \\ &=\delta_{h}^{(p)}(j) x_{i}^{(p)} \end{aligned} \newline
∂ v i j ∂ E ( p ) = P 1 k = 1 ∑ N ( y k ( p ) − t k ( p ) ) y k ( p ) ( 1 − y k ( p ) ) w j k a j ( p ) ( 1 − a j ( p ) ) x i ( p ) = a j ( p ) ( 1 − a j ( p ) ) k = 1 ∑ N δ o ( p ) ( k ) w j k x i ( p ) = δ h ( p ) ( j ) x i ( p )
\qquad\qquad
∂
E
∂
v
i
j
=
∑
p
=
1
P
∂
E
(
p
)
∂
v
i
j
=
∑
p
=
1
P
δ
h
(
p
)
(
j
)
x
i
(
p
)
(
20
)
\begin{aligned} \dfrac{\partial E}{ \partial v_{ij} } = \sum\limits_{p=1}^{P}\dfrac{\partial E^{(p)}}{\partial v_{ij} } = \sum\limits_{p=1}^{P}\delta_{h}^{(p)}(j) x_{i}^{(p)} \qquad\qquad\qquad\qquad\qquad\qquad\ \ \ \ \ (20) \end{aligned} \newline
∂ v i j ∂ E = p = 1 ∑ P ∂ v i j ∂ E ( p ) = p = 1 ∑ P δ h ( p ) ( j ) x i ( p ) ( 2 0 )
\qquad
(
4
)
(4)
( 4 )
(
5
)
(5)
( 5 )
\newline
\qquad\qquad
w
j
k
=
w
j
k
−
η
∂
E
∂
w
j
k
=
w
j
k
−
η
∑
p
=
1
P
δ
o
(
p
)
(
k
)
a
j
(
p
)
(
21
)
w_{jk}=w_{jk}-\eta \dfrac{\partial E}{\partial w_{jk}}=w_{jk}-\eta \displaystyle\sum_{p=1}^{P}\delta_{o}^{(p)}(k)a_{j}^{(p)}\qquad\qquad\qquad\qquad\ \ \ \ (21) \newline
w j k = w j k − η ∂ w j k ∂ E = w j k − η p = 1 ∑ P δ o ( p ) ( k ) a j ( p ) ( 2 1 )
\qquad\qquad
v
i
j
=
v
i
j
−
η
∂
E
∂
v
i
j
=
v
i
j
−
η
∑
p
=
1
P
δ
h
(
p
)
(
j
)
x
i
(
p
)
(
22
)
v_{ij}=v_{ij}-\eta \dfrac{\partial E}{\partial v_{ij}}=v_{ij}-\eta \displaystyle\sum_{p=1}^{P}\delta_{h}^{(p)}(j) x_{i}^{(p)} \qquad\qquad\qquad\qquad\qquad\ \ (22) \newline
v i j = v i j − η ∂ v i j ∂ E = v i j − η p = 1 ∑ P δ h ( p ) ( j ) x i ( p ) ( 2 2 )
\qquad
总结 :在
b
a
t
c
h
batch
b a t c h
(
(
(
2.3
2.3
2 . 3
)
)
)
\newline
1
)
\qquad1)
1 )
{
x
(
p
)
,
t
(
p
)
}
p
=
1
P
\{\boldsymbol{x}^{(p)},\boldsymbol{t}^{(p)}\}_{p=1}^{P}
{ x ( p ) , t ( p ) } p = 1 P
2.4
2.4
2 . 4
(
3
)
(3)
( 3 )
{
y
(
p
)
}
p
=
1
P
\{\boldsymbol{y}^{(p)}\}_{p=1}^{P}
{ y ( p ) } p = 1 P
P
P
P
(
14
)
(14)
( 1 4 )
\newline
2
)
\qquad2)
2 )
(
17
)
(17)
( 1 7 )
{
δ
o
(
p
)
(
k
)
,
k
=
1
,
2
,
⋯
 
,
N
}
p
=
1
P
\{\delta_{o}^{(p)}(k),k=1,2,\cdots,N \}_{p=1}^{P}
{ δ o ( p ) ( k ) , k = 1 , 2 , ⋯ , N } p = 1 P
\newline
3
)
\qquad3)
3 )
(
19
)
,
(
21
)
(19),(21)
( 1 9 ) , ( 2 1 )
w
j
k
w_{jk}
w j k
\newline
4
)
\qquad4)
4 )
(
18
)
(18)
( 1 8 )
{
δ
h
(
p
)
(
j
)
,
j
=
1
,
2
,
⋯
 
,
M
}
p
=
1
P
\{\delta_{h}^{(p)}(j),j=1,2,\cdots,M \}_{p=1}^{P}
{ δ h ( p ) ( j ) , j = 1 , 2 , ⋯ , M } p = 1 P
\newline
5
)
\qquad5)
5 )
(
20
)
,
(
22
)
(20),(22)
( 2 0 ) , ( 2 2 )
v
i
j
v_{ij}
v i j
\newline
6
)
\qquad6)
6 )
1
)
∼
5
)
1)\sim5)
1 ) ∼ 5 )
e
a
r
l
y
s
t
o
p
p
i
n
g
early\ stopping
e a r l y s t o p p i n g
\newline
\qquad
Machine Learning - An Algorithmic Perspective(2nd Edition) 一书的第4章,通过MNIST数据集进行了测试。
def mlpfwd ( self, inputs) :
""" Run the network forward """
self. hidden = np. dot( inputs, self. weights1) ;
self. hidden = 1.0 / ( 1.0 + np. exp( - self. beta* self. hidden) )
self. hidden = np. concatenate( ( self. hidden, - np. ones( ( np. shape( inputs) [ 0 ] , 1 ) ) ) , axis= 1 )
outputs = np. dot( self. hidden, self. weights2) ;
if self. outtype == 'linear' :
return outputs
elif self. outtype == 'logistic' :
return 1.0 / ( 1.0 + np. exp( - self. beta* outputs) )
elif self. outtype == 'softmax' :
normalisers = np. sum ( np. exp( outputs) , axis= 1 ) * np. ones( ( 1 , np. shape( outputs) [ 0 ] ) )
return np. transpose( np. transpose( np. exp( outputs) ) / normalisers)
else :
print "error"
2)batch模式下的误差反向传播训练所有权值(权值的更新采用了动量法),weights1表示输入层权值,weights2表示隐层权值,分别对应了
2.3
2.3
2 . 3
def mlptrain ( self, inputs, targets, eta, niterations) :
""" Train the thing """
inputs = np. concatenate( ( inputs, - np. ones( ( self. ndata, 1 ) ) ) , axis= 1 )
change = range ( self. ndata)
updatew1 = np. zeros( ( np. shape( self. weights1) ) )
updatew2 = np. zeros( ( np. shape( self. weights2) ) )
for n in range ( niterations) :
self. outputs = self. mlpfwd( inputs)
error = 0.5 * np. sum ( ( self. outputs- targets) ** 2 )
if ( np. mod( n, 100 ) == 0 ) :
print "Iteration: " , n, " Error: " , error
if self. outtype == 'linear' :
deltao = ( self. outputs- targets) / self. ndata
elif self. outtype == 'softmax' :
deltao = ( self. outputs- targets) * ( self. outputs* ( - self. outputs) + self. outputs) / self. ndata
else :
print "error"
deltah = self. hidden* self. beta* ( 1.0 - self. hidden) * ( np. dot( deltao, np. transpose( self. weights2) ) )
updatew1 = eta* ( np. dot( np. transpose( inputs) , deltah[ : , : - 1 ] ) ) + self. momentum* updatew1
updatew2 = eta* ( np. dot( np. transpose( self. hidden) , deltao) ) + self. momentum* updatew2
self. weights1 -= updatew1
self. weights2 -= updatew2
3)early stopping方式确定batch模式的重复训练次数(默认重复训练100次为一个基本步骤)
def earlystopping ( self, inputs, targets, valid, validtargets, eta, niterations= 100 ) :
valid = np. concatenate( ( valid, - np. ones( ( np. shape( valid) [ 0 ] , 1 ) ) ) , axis= 1 )
old_val_error1 = 100002
old_val_error2 = 100001
new_val_error = 100000
count = 0
while ( ( ( old_val_error1 - new_val_error) > 0.001 ) or ( ( old_val_error2 - old_val_error1) > 0.001 ) ) :
count+= 1
print count
self. mlptrain( inputs, targets, eta, niterations)
old_val_error2 = old_val_error1
old_val_error1 = new_val_error
validout = self. mlpfwd( valid)
new_val_error = 0.5 * np. sum ( ( validtargets- validout) ** 2 )
print "Stopped" , new_val_error, old_val_error1, old_val_error2
return new_val_error
初始化过程:
def __init__ ( self, inputs, targets, nhidden, beta= 1 , momentum= 0.9 , outtype= 'logistic' ) :
""" Constructor """
self. nin = np. shape( inputs) [ 1 ]
self. nout = np. shape( targets) [ 1 ]
self. ndata = np. shape( inputs) [ 0 ]
self. nhidden = nhidden
self. beta = beta
self. momentum = momentum
self. outtype = outtype
self. weights1 = ( np. random. rand( self. nin+ 1 , self. nhidden) - 0.5 ) * 2 / np. sqrt( self. nin)
self. weights2 = ( np. random. rand( self. nhidden+ 1 , self. nout) - 0.5 ) * 2 / np. sqrt( self. nhidden)
主程序1——batch模式:
import pylab as pl
import numpy as np
import mlp
from dataset. mnist import load_mnist
( x_train, t_train) , ( x_test, t_test) = load_mnist( flatten= True , normalize= False )
nread = 10000
train_in = x_train[ : nread, : ]
train_tgt = np. zeros( ( nread, 10 ) )
for i in range ( nread) :
train_tgt[ i, t_train[ i] ] = 1
test_in = x_test[ : 10000 , : ]
test_tgt = np. zeros( ( 10000 , 10 ) )
for i in range ( nread) :
test_tgt[ i, t_test[ i] ] = 1
valid_in = x_train[ nread: nread* 2 , : ]
valid_tgt = np. zeros( ( nread, 10 ) )
for i in range ( nread) :
valid_tgt[ i, t_train[ nread+ i] ] = 1
for i in [ 20 , 50 ] :
print "----- " + str ( i)
net = mlp. mlp( train_in, train_tgt, i, outtype= 'softmax' )
net. earlystopping( train_in, train_tgt, valid_in, valid_tgt, 0.1 )
net. confmat( test_in, test_tgt)
测试结果: Percentage Correct: 88.97 (识别率) Percentage Correct: 91.36(识别率)
主程序2 —— mini batch模式(训练集和验证集的选取可以随意选择):
import pylab as pl
import numpy as np
import mlp
from dataset. mnist import load_mnist
( x_train, t_train) , ( x_test, t_test) = load_mnist( flatten= True , normalize= False )
nread = 5000
test_in = x_test[ : , : ]
test_tgt = np. zeros( ( 10000 , 10 ) )
for i in range ( 10000 ) :
test_tgt[ i, t_test[ i] ] = 1
ntimes = 60000 / nread
for n in range ( ntimes) :
print n
train_in = x_train[ nread* n: nread* ( n+ 1 ) , : ]
train_tgt = np. zeros( ( nread, 10 ) )
for i in range ( nread) :
train_tgt[ i, t_train[ nread* n+ i] ] = 1
valid_tgt = np. zeros( ( nread, 10 ) )
if n < ntimes- 1 :
valid_in = x_train[ nread* ( n+ 1 ) : nread* ( n+ 2 ) , : ]
for i in range ( nread) :
valid_tgt[ i, t_train[ nread* ( n+ 1 ) + i] ] = 1
else :
valid_in = x_train[ 0 : nread, : ]
for i in range ( nread) :
valid_tgt[ i, t_train[ i] ] = 1
if n== 0 :
net = mlp. mlp( train_in, train_tgt, 40 , outtype= 'softmax' )
net. earlystopping( train_in, train_tgt, valid_in, valid_tgt, 0.1 )
net. confmat( test_in, test_tgt)
测试结果:(识别率逐步提高)
(有待检查)