在之前的教程 “Kibana:使用 Script fields 来提高数据的可观测性”,我们通过一种 Scripted field 的方法来提高我们数据的可观测性。我们把一个数据可以把它展示在 Y 的负轴上。这样更好地提高数据的可观测性。在今天的教程中,我们将使用 Math aggregation 来达到同样的效果。
准备数据
在今天的教程中,我们将使用 Kibana 自带的索引来进行展示。打开 Kibana 界面:
点击 Add data:
这样我们的样本数据就导入进 Elasticsearch 了。通过上面的操作,我们在 Elasticsearch 中将生成一个叫做 kibana_sample_data_logs 的索引。
创建 TSVB Math aggregation
打开 Kibana Visualization:
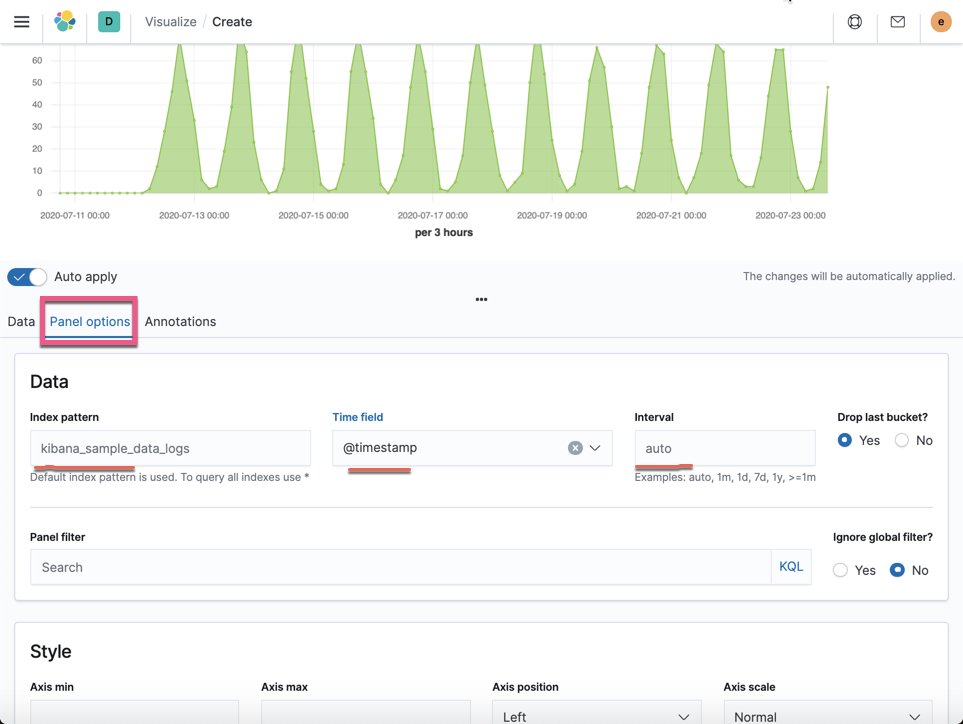
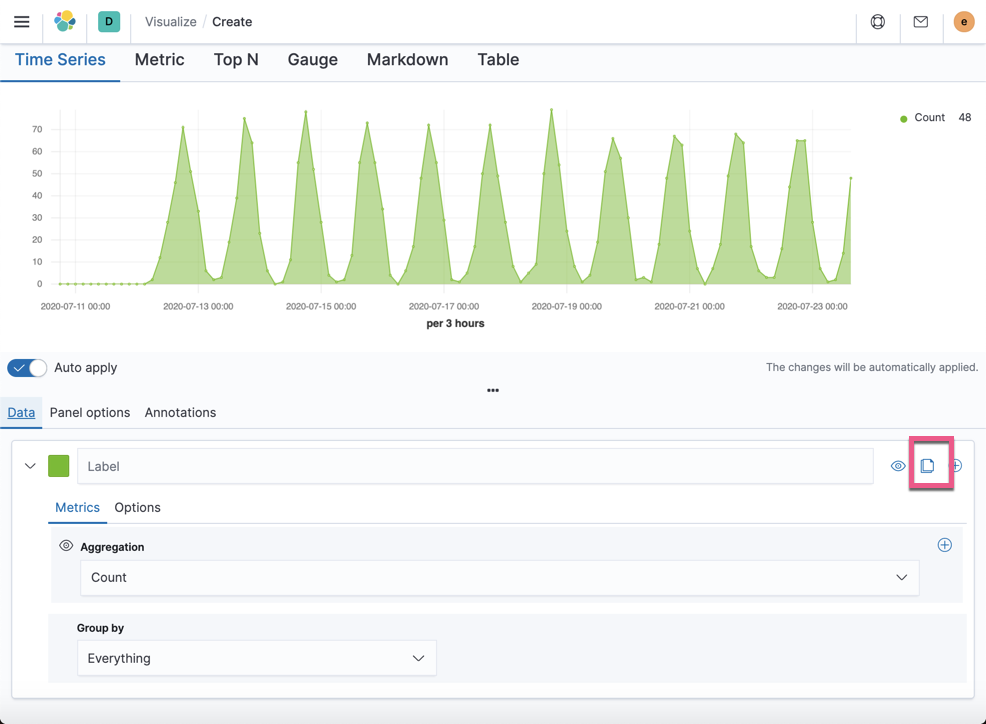
点击 clone 图标:
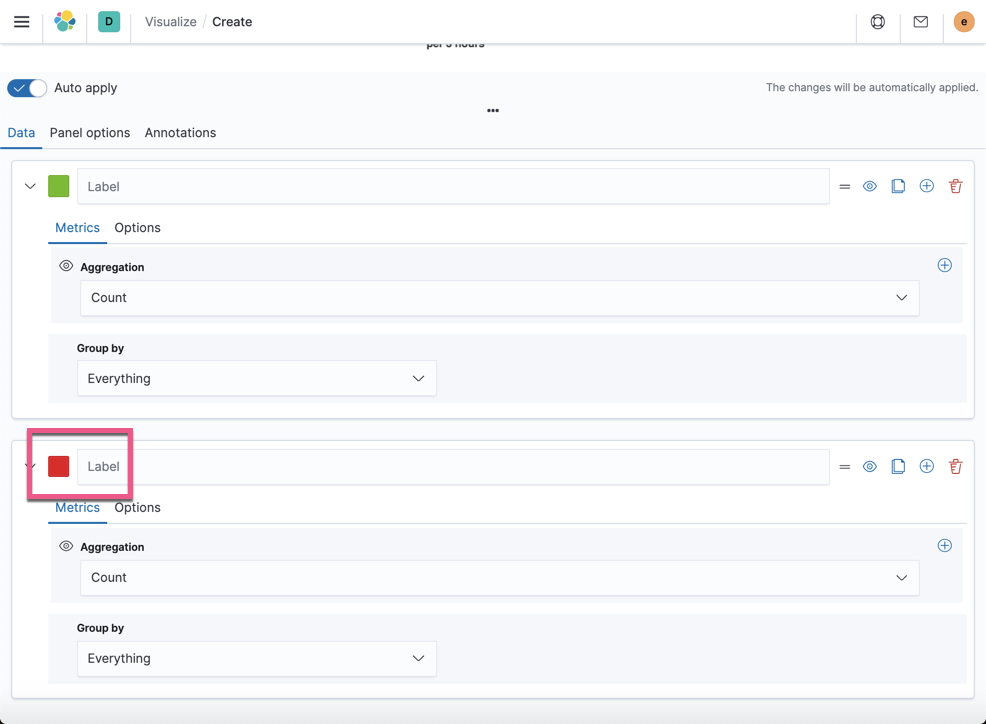
选择不同的颜色。这里我选择红色。

选择 Lucene 查询,并在 Filters 里输入:
response:[200 TO 299]这样就完成了上面的一个 TSVB 的绘画。
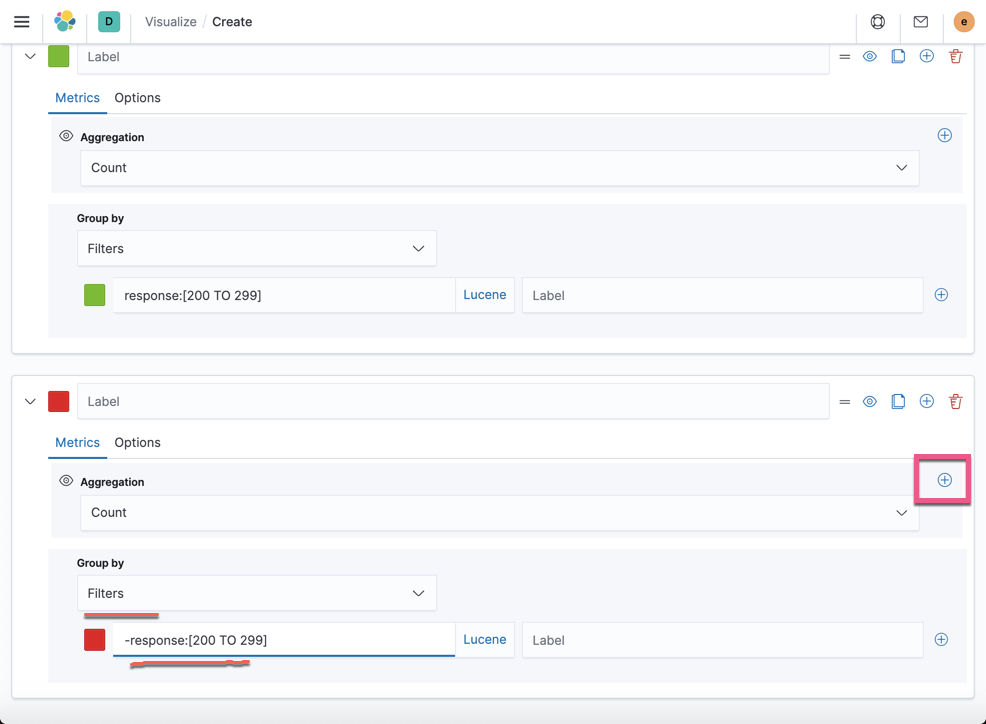
在下面的 TSVB 里查找不是 200 - 299 里的所有的文档数。点击右边的 + 号添加另外一个 aggregation:
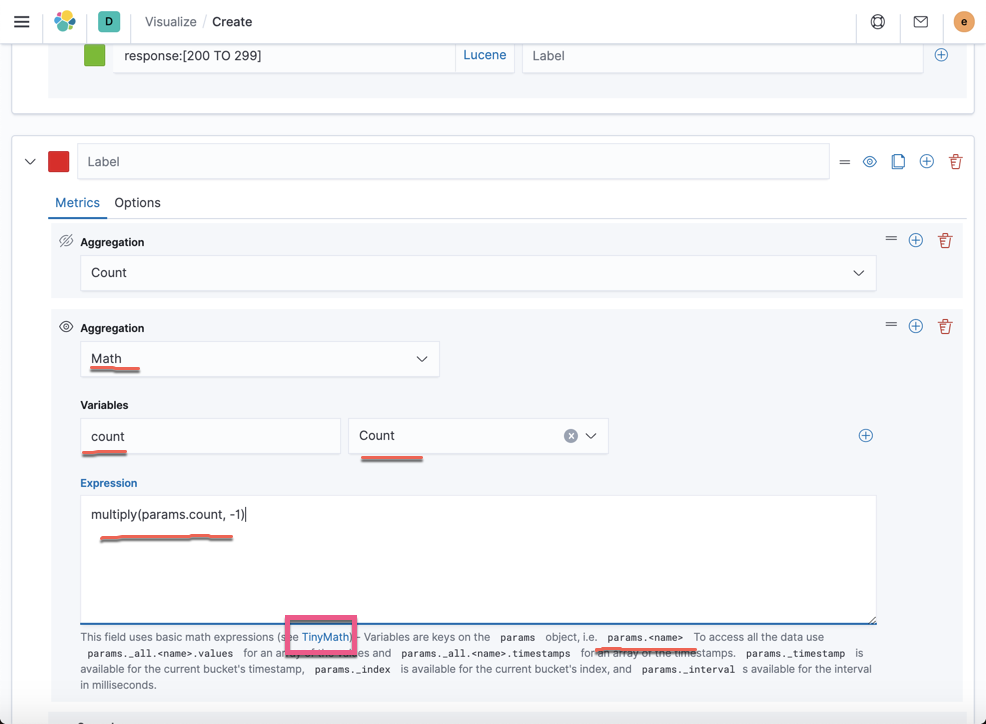
在上面,我们选择了 Math aggregation。同时,我们在 expression 中输入:
multiply(params.count, -1)我们可以点击 TinyMath 找到更多的帮助信息。另外按照上面的提示,我们需要输入 params.<name> 才可以起作用。
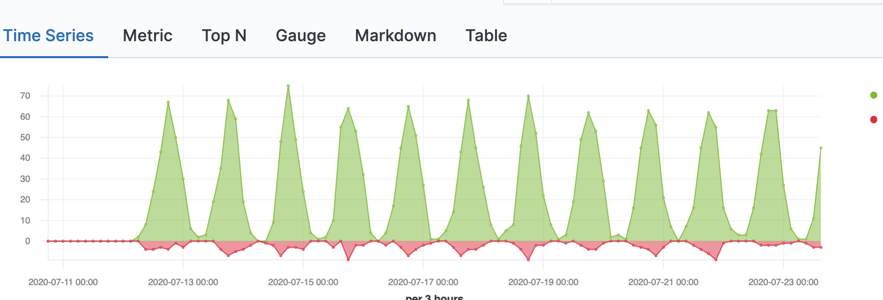
我们滚动上屏幕的上方看我们最终的可视化图:
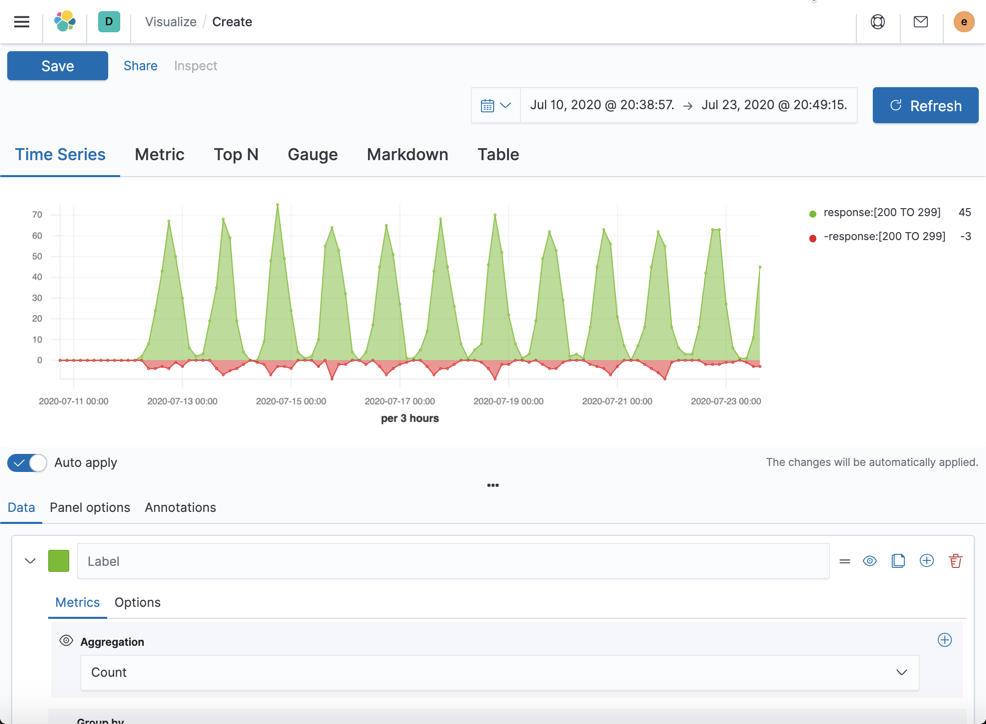
在这里,我们显示了在 [200-299] 范围里的所有文档,用绿色表示的。同时我们可以看到在红色的部分显示了除去 [200-299] 之外的所有文档。