MX Linux
作者:解琛
时间:2020 年 8 月 1 日
- 一、Ubuntu 学习
- 二、镜像烧录
- 三、NFS
- 四、GCC(GNU Compiler Collection)
- 五、Linux 系统下的 Hello World
- 六、Makefile
- 七、文件操作和系统调用
- 八、Linux 系统编程
- 九、Linux 驱动开发
- 十、Linux 内核调试
一、Ubuntu 学习
先掌握全局,然后再深挖其中重要的细节。
1.1 常用指令
1.1.1 which
使用 which 命令可以查看指定命令的路径。
which ls
1.1.2 cd
“-” :减号,不是目录,但作为 cd 命令的参数时可以返回上一次 cd 切换前的目录。
cd -
1.1.3 mkdir
“-p” 选项可以不输入,若使用了 “-p” 选项, 当创建的目录名包含的上级目录不存在时,它会自动创建所有不存在的目录。
mkdir [-p] 目录名
1.1.4 touch
touch命令可以创建不存在的文件;
touch通过参数修改目录或文件的日期时间,就是摸一下,更新它的时间。
1.1.5 ls
- -a: 显示所有文件及目录 (ls内定将文件名或目录名称开头为“.”的视为隐藏档,不会列出)
- -l :注意这是字母L的小写,除文件名称外,将文件型态、权限、拥有者、文件大小等信息详细列出
- -t :将文件依建立时间之先后次序列出
- -A: 同 -a ,但不列出 “.”(当前目录) 及 “…”(父目录)
- -R :若目录下有文件,则该目录下的文件也会列出,即递归显示
1.1.6 输出重定向
- “>” 会直接用输出覆盖原文件;
- “>>” 把输出追加到原文件的末尾。
1.1.7 rmdir
rmdir [-p] 目录名
它只能用来删除空的目录,-p可以用来递归删除目录,如果子目录删除后其父目录为空时,也一同被删除。
1.1.8 sudo
!! 代表上一条指令。
sudo !!
# sudo加两个感叹号,重新使用sudo权限执行上一条命令
1.1.9 poweroff
使用 poweroff 可以关机。
1.1.10 man
通过 -s (可省略)指定搜索章节的内容,man 手册的章节 3 是“库调用”相关的函数说明。
man -s 3 printf
1.1.11 apt-cache
| 命令 | 作用 |
|---|---|
| apt-cache showsrc 软件包名 | 显示软件包的相关信息,如版本信息,依赖关系等 |
| apt-cache search 软件包名 | 按关键字查找软件包 |
| apt-cache depends软件包名 | 显示该软件包的依赖关系信息 |
| apt-cache rdepends软件包名 | 显示所有依赖于该软件包的软件包名字 |
| apt-cache show 软件包名 | 显示指定软件包的信息,如版本号,依赖关系等. |
| apt-cache pkgnames | 显示所有软件包的名字 |
| apt-cache policy 软件包名 | 显示软件包的安装状态 |
1.1.12 apt
| 命令 | 作用 |
|---|---|
| apt install 软件包名 | 安装指定的软件包 |
| apt remove 软件包名 | 卸载指定的软件包 |
| apt update | 更新软件源列表 |
| apt search 软件包名 | 根据关键字搜索对应的软件包 |
| apt show 软件包名 | 显示软件包的相关信息 |
| apt list | 根据名称列出所有的软件包 |
1.1.13 账号信息修改
usermod 修改用户名;
passwd 修改密码;
hostname 修改主机名。
1.1.14 查看内核版本
uname -r
1.1.15 查看 cpu 主频
cat /sys/devices/system/cpu/cpu0/cpufreq/cpuinfo_cur_freq
1.1.16 evtest
可以使用 evtest 工具更方便地查看硬件当前接入的输入设备, 并且对其进行实时检测。
sudo apt install evtest
xiechen@xiechen-Ubuntu:/dev/input$ sudo evtest
No device specified, trying to scan all of /dev/input/event*
Available devices:
/dev/input/event0: Power Button
/dev/input/event1: Sleep Button
/dev/input/event2: AT Translated Set 2 keyboard
/dev/input/event3: Video Bus
/dev/input/event4: ImExPS/2 Generic Explorer Mouse
/dev/input/event5: VirtualBox USB Tablet
/dev/input/event6: VirtualBox mouse integration
Select the device event number [0-6]:
执行命令后,它会扫描 /dev/input 目录下的 event 设备输入事件文件,并列出到终端, 它提示我们可以通过数字选择对应的设备进行测试。
1.2 国内镜像
- 清华大学可以使用evtest工具更方便地查看硬件当前接入的输入设备, 并且对其进行实时检测。镜像源: https://mirrors.tuna.tsinghua.edu.cn
- 中国科技大学镜像源: https://mirrors.ustc.edu.cn
- 阿里云镜像源: https://opsx.alibaba.com/mirror
1.3 proc
Linux 没有提供类似 Windows 的任务管理器,但是它将系统运行的信息都记录在 /proc 目录下的文件中, 用户可以通过访问该目录下的文件获取对应的系统信息。
xiechen@xiechen-Ubuntu:/proc$ ls
1 12 141 153 174 19845 21046 29 352 372 39 40 4118 5719 6140 6201 6329 7864 942 dma kmsg partitions timer_list
10 1216 14117 154 178 1995 21337 294 355 3728 3904 4041 4121 6 6142 6202 6354 7875 950 driver kpagecgroup pressure tty
1018 12633 14138 155 17842 2 21436 3 357 373 3909 4044 4125 6005 6147 6207 6356 7883 957 execdomains kpagecount sched_debug uptime
10303 12681 142 156 17845 20 22 30 358 3748 391 4048 4129 6008 6149 6266 6376 7892 acpi fb kpageflags schedstat version
10888 13 143 1560 18 20306 23 3028 3595 3786 3911 4051 4131 6009 6152 6267 6381 7911 asound filesystems loadavg scsi version_signature
10940 13172 144 157 18280 20340 24 308 3596 3788 3914 4052 42 6026 6154 6272 6383 862 buddyinfo fs locks self vmallocinfo
10961 1325 145 159 18885 20379 251 32 36 3791 3916 4053 515 6028 6158 6273 7074 867 bus interrupts mdstat slabinfo vmstat
11 136 14723 16 1898 2039 252 320 362 38 392 4054 551 6041 6159 6276 755 8837 cgroups iomem meminfo softirqs zoneinfo
11063 137 14733 161 19127 20469 256 33 3649 3800 394 4059 5690 6044 6173 6279 758 885 cmdline ioports misc stat
11064 138 14745 164 194 20479 26 34 365 382 395 4080 5691 6068 6182 6280 7810 9 consoles irq modules swaps
1123 1395 148 16504 19419 2078 27 347 3665 3850 396 4095 5692 607 6194 6281 7818 905 cpuinfo kallsyms mounts sys
1125 1398 149 16991 19437 20826 277 3497 3674 386 3977 41 5693 608 6195 6284 7852 911 crypto kcore mtrr sysrq-trigger
1131 14 15 17 19454 2088 278 35 368 387 3995 4111 5694 6105 6196 6302 7857 926 devices keys net sysvipc
1133 140 152 17110 19465 21 28 350 37 3893 4 4116 5718 6114 6197 6307 7861 929 diskstats key-users pagetypeinfo thread-self
1.4 sys
/sys 目录下的文件 / 文件夹向用户提供了一些关于设备、内核模块、文件系统以及其他内核组件的信息。
xiechen@xiechen-Ubuntu:/sys$ ls
block bus class dev devices firmware fs hypervisor kernel module power
xiechen@xiechen-Ubuntu:/sys$ ls class
ata_device block devfreq-event extcon hwmon leds nd powercap printer remoteproc scsi_generic thermal vfio
ata_link bsg dma firmware i2c-adapter mdio_bus net power_supply ptp rfkill scsi_host tpm virtio-ports
ata_port dax dmi gpio i2c-dev mem pci_bus ppdev pwm rtc sound tpmrm vtconsole
backlight devcoredump drm graphics input misc pci_epc ppp rapidio_port scsi_device spi_master tty wakeup
bdi devfreq drm_dp_aux_dev hidraw iommu mmc_host phy pps regulator scsi_disk spi_slave vc watchdog
1.5 dev
/dev 目录包含了非常丰富的设备信息,该目录下包含了 Linux 系统中使用的所有外部设备, 如 /dev/tty 为串口设备、/dev/ram 为内存、通过这些设备文件,我们也可以访问到对应的硬件设备。
二、镜像烧录
使用软件 etcher 可以轻松完成镜像的刻录。
三、NFS
3.1 安装
sudo apt install nfs-kernel-server
在配置 NFS 时需要使用到用户 uid 和组 gid,可使用 id 命令查看。
xiechen@xiechen-Ubuntu:~$ id
uid=1000(xiechen) gid=1000(xiechen) 组=1000(xiechen),4(adm),24(cdrom),27(sudo),30(dip),46(plugdev),116(lpadmin),126(sambashare),127(docker)
3.2 配置
安装NFS服务后,会新增一个 /etc/exports 文件,NFS 服务根据它的配置来运行,它默认包含了一些配置的范例。
xiechen@xiechen-Ubuntu:~$ cat /etc/exports
# /etc/exports: the access control list for filesystems which may be exported
# to NFS clients. See exports(5).
#
# Example for NFSv2 and NFSv3:
# /srv/homes hostname1(rw,sync,no_subtree_check) hostname2(ro,sync,no_subtree_check)
#
# Example for NFSv4:
# /srv/nfs4 gss/krb5i(rw,sync,fsid=0,crossmnt,no_subtree_check)
# /srv/nfs4/homes gss/krb5i(rw,sync,no_subtree_check)
#
详细的帮助说明可以使用 命令 man nfs 查看。
/home/embedfire/workdir 192.168.0.0/24(rw,sync,all_squash,anonuid=998,anongid=998,no_subtree_check)
- /home/embedfire/workdir:要共享的开发主机目录,注意使用空格与后面的配置隔开。
- 192.168.0.0/24:配置谁可以访问,其中的/24是掩码,此处表示24个1,即11111111.11111111.11111111.00000000, 即掩码是255.255.255.0。结合前面192.168.0.0表示此处配置IP为 192.168.0.*的主机均可以访问该目录,即局域网上的所有主机。
- 若局域网是其它网段,请参考此处的配置,不能直接用星号表示,如欲配 置192.168.1.* 的局域网下所有机器都可以访问,则配置为 192.168.1.0/24。
- 这个配置域也可以直接写可访问的主机名,如把“192.168.0.0/24”替换为开 发板主机名“imx6ull14x14evk”,则仅该开发板能访问共享的目录。
- rw: 表示客户机的权限,rw表示可读写,具体的权限还受文件系统的rwx及用户身份影响。
- sync:资料同步写入到内存与硬盘中。
- anonuid=998:将客户机上的用户映射成指定的本地用户ID的用户,此处998是开 发主机embedfire用户的uid,此处请根据具体的主机用户uid进行配置。
- anongid=998: 将客户机上的用户映射成属于指定的本地用户 组ID,此处998是开发主机embedfire用户组gid,此处请根据具体的主机用户组gid进行配置。
- no_subtree_check:不检查子目录权限,默认配置。
3.3 更新 exports 配置
sudo exportfs -arv
- a:全部 mount 或 umount 文件 /etc/exports 中的内容。
- r:重新 mount 文件 /etc/exports 中的共享内容。
- u:umount 目录。
- v:在 exportfs 的时候,将详细的信息输出到屏幕上。
3.4 查看 NFS 共享情况
showmount -e
3.5 安NFS 客户端
sudo apt install nfs-common -y
3.6 查看NFS服务器共享目录
showmount -e 192.168.0.219
3.7 临时挂载NFS文件系统
sudo mount -t nfs 192.168.0.219:/home/embedfire/workdir /mnt
- -t nfs:指定挂载的文件系统格式为nfs。
- 192.168.0.219:指定NFS服务器的IP地址。
- /home/embedfire/workdir:指定NFS服务器的共享目录。
- /mnt:本地挂载目录,即要把NFS服务器的共享目录映射到开发板的/mnt目录下。
若挂载成功,终端不会有输出,Linux 的哲学思想是 “没有消息便是好消息”。
3.8 取消挂载
sudo umount /mnt
四、GCC(GNU Compiler Collection)
4.1 GCC 编译工具链
4.1.1 GCC编译器
GCC 编译工具链(toolchain)是指以 GCC 编译器为核心的一整套工具,用于把源代码转化成可执行应用程序。它主要包含以下三部分内容:
- gcc-core:即GCC编译器,用于完成预处理和编译过程,例如把C代码转换成汇编代码。
- Binutils :除GCC编译器外的一系列小工具包括了链接器ld,汇编器as、目标文件格式查看器readelf等。
- glibc:包含了主要的 C语言标准函数库,C语言中常常使用的打印函数printf、malloc函数就在glibc 库中。
4.1.2 Binutils工具集
- as:汇编器,把汇编语言代码转换为机器码(目标文件)。
- ld:链接器,把编译生成的多个目标文件组织成最终的可执行程序文件。
- readelf:可用于查看目标文件或可执行程序文件的信息。
- nm : 可用于查看目标文件中出现的符号。
- objcopy: 可用于目标文件格式转换,如.bin 转换成 .elf 、.elf 转换成 .bin等。
- objdump:可用于查看目标文件的信息,最主要的作用是反汇编。
- size:可用于查看目标文件不同部分的尺寸和总尺寸,例如代码段大小、数据段大小、使用的静态内存、总大小等。
系统默认的 Binutils 工具集位于 /usr/bin 目录下,可使用如下命令查看系统中存在的 Binutils 工具集。
xiechen@xiechen-Ubuntu:~/文档/6.全世科技/3.2212协议/c$ ls /usr/bin/ | grep linux-gnu-
i686-linux-gnu-pkg-config
x86_64-linux-gnu-addr2line
x86_64-linux-gnu-ar
x86_64-linux-gnu-as
x86_64-linux-gnu-c++filt
x86_64-linux-gnu-cpp
x86_64-linux-gnu-cpp-7
x86_64-linux-gnu-dwp
x86_64-linux-gnu-elfedit
x86_64-linux-gnu-g++
x86_64-linux-gnu-g++-7
x86_64-linux-gnu-gcc
x86_64-linux-gnu-gcc-7
x86_64-linux-gnu-gcc-ar
x86_64-linux-gnu-gcc-ar-7
x86_64-linux-gnu-gcc-nm
x86_64-linux-gnu-gcc-nm-7
x86_64-linux-gnu-gcc-ranlib
x86_64-linux-gnu-gcc-ranlib-7
x86_64-linux-gnu-gcov
x86_64-linux-gnu-gcov-7
x86_64-linux-gnu-gcov-dump
x86_64-linux-gnu-gcov-dump-7
x86_64-linux-gnu-gcov-tool
x86_64-linux-gnu-gcov-tool-7
x86_64-linux-gnu-gold
x86_64-linux-gnu-gprof
x86_64-linux-gnu-ld
x86_64-linux-gnu-ld.bfd
x86_64-linux-gnu-ld.gold
x86_64-linux-gnu-nm
x86_64-linux-gnu-objcopy
x86_64-linux-gnu-objdump
x86_64-linux-gnu-pkg-config
x86_64-linux-gnu-python2.7-config
x86_64-linux-gnu-python3.6-config
x86_64-linux-gnu-python3.6m-config
x86_64-linux-gnu-python3-config
x86_64-linux-gnu-python3m-config
x86_64-linux-gnu-python-config
x86_64-linux-gnu-ranlib
x86_64-linux-gnu-readelf
x86_64-linux-gnu-size
x86_64-linux-gnu-strings
x86_64-linux-gnu-strip
x86_64-pc-linux-gnu-pkg-config
4.1.3 glibc库
xiechen@xiechen-Ubuntu:~/文档/6.全世科技/3.2212协议/c$ /lib/x86_64-linux-gnu/libc.so.6
GNU C Library (Ubuntu GLIBC 2.27-3ubuntu1.2) stable release version 2.27.
Copyright (C) 2018 Free Software Foundation, Inc.
This is free software; see the source for copying conditions.
There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A
PARTICULAR PURPOSE.
Compiled by GNU CC version 7.5.0.
libc ABIs: UNIQUE IFUNC
For bug reporting instructions, please see:
<https://bugs.launchpad.net/ubuntu/+source/glibc/+bugs>.
本系统中使用的 glibc 是 2.27 版本,是由 GCC 7.5.0 版本的编译器编译出来的。
4.2 基本语法
- -o:小写字母“o”,指定生成的可执行文件的名字,不指定的话生成的可执行文件名为a.out。
- -E:只进行预处理,既不编译,也不汇编。
- -S:只编译,不汇编。
- -c:编译并汇编,但不进行链接。
- -g:生成的可执行文件带调试信息,方便使用gdb进行调试。
- -Ox:大写字母“O”加数字,设置程序的优化等级,如“-O0”“-O1” “-O2” “-O3”, 数字越大代码的优化等级越高,编译出来的程序一般会越小,但有可能会导致程序不正常运行。
4.3 编译过程
#直接编译成可执行文件
gcc hello.c -o hello
#以上命令等价于执行以下全部操作
#预处理,可理解为把头文件的代码汇总成C代码,把*.c转换得到*.i文件
gcc –E hello.c –o hello.i
#编译,可理解为把C代码转换为汇编代码,把*.i转换得到*.s文件
gcc –S hello.i –o hello.s
#汇编,可理解为把汇编代码转换为机器码,把*.s转换得到*.o,即目标文件
gcc –c hello.s –o hello.o
#链接,把不同文件之间的调用关系链接起来,把一个或多个*.o转换成最终的可执行文件
gcc hello.o –o hello
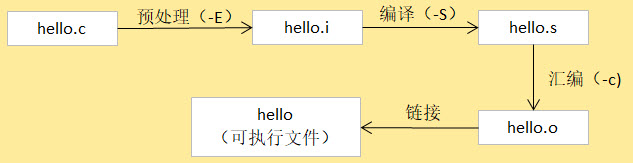
GCC 编译工具链在编译一个 C 源文件时需要经过以下 4 步:
- 预处理,在预处理过程中,对源代码文件中的文件包含(include)、 预编译语句(如宏定义define等)进行展开,生成.i文件。 可理解为把头文件的代码、宏之类的内容转换成更纯粹的C代码,不过生成的文件以.i为后缀。
- 编译,把预处理后的.i文件通过编译成为汇编语言,生成.s文件,即把代码从C语言转换成汇编语言,这是GCC编译器完成的工作。
- 汇编,将汇编语言文件经过汇编,生成目标文件.o文件,每一个源文件都对应一个目标文件。即把汇编语言的代码转换成机器码,这是as汇编器完成的工作。
- 链接,最后将每个源文件对应的.o文件链接起来,就生成一个可执行程序文件,这是链接器ld完成的工作。
xiechen@xiechen-Ubuntu:~/2.测试中心$ ls -l
总用量 872
-rw-r--r-- 1 xiechen xiechen 79 8月 5 16:38 main.c
-rw-r--r-- 1 xiechen xiechen 17935 8月 5 16:40 main.i
-rw-r--r-- 1 xiechen xiechen 1536 8月 5 16:43 main.o
-rw-r--r-- 1 xiechen xiechen 459 8月 5 16:43 main.s
-rwxr-xr-x 1 xiechen xiechen 8296 8月 5 16:47 main_so
-rwxr-xr-x 1 xiechen xiechen 844704 8月 5 16:46 main_static
4.4 链接
链接分为两种:
- 动态链接,GCC编译时的默认选项。动态是指在应用程序运行时才去加载外部的代码库, 例如printf函数的C标准代码库*.so文件存储在Linux系统的某个位置, hello程序执行时调用库文件*.so中的内容,不同的程序可以共用代码库。 所以动态链接生成的程序比较小,占用较少的内存。
- 静态链接,链接时使用选项“–static”,它在编译阶段就会把所有用到的库打包到自己的可执行程序中。 所以静态链接的优点是具有较好的兼容性,不依赖外部环境,但是生成的程序比较大。
xiechen@xiechen-Ubuntu:~/2.测试中心$ gcc main.o -o main_so
xiechen@xiechen-Ubuntu:~/2.测试中心$ gcc main.o -o main_static --static
xiechen@xiechen-Ubuntu:~/2.测试中心$ ls -l
总用量 872
-rw-r--r-- 1 xiechen xiechen 79 8月 5 16:38 main.c
-rw-r--r-- 1 xiechen xiechen 17935 8月 5 16:40 main.i
-rw-r--r-- 1 xiechen xiechen 1536 8月 5 16:43 main.o
-rw-r--r-- 1 xiechen xiechen 459 8月 5 16:43 main.s
-rwxr-xr-x 1 xiechen xiechen 8296 8月 5 16:49 main_so
-rwxr-xr-x 1 xiechen xiechen 844704 8月 5 16:50 main_static
使用动态链接生成的 main.so 程序才 8.2KB, 而使用静态链接生成的 main_static 程序则高达 825KB。
使用 ldd 工具查看动态文件的库依赖
xiechen@xiechen-Ubuntu:~/2.测试中心$ ldd main_so
linux-vdso.so.1 (0x00007ffd953e7000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f75b81b5000)
/lib64/ld-linux-x86-64.so.2 (0x00007f75b87a8000)
xiechen@xiechen-Ubuntu:~/2.测试中心$ ldd main_static
不是动态可执行文件
4.5 工具链安装
sudo apt install gcc-arm-linux-gnueabihf
- arm-linux-gnueabihf-gcc:名称中的Linux表示目标应用程序是运行在Linux操作系统之上的,例如前面的hello.c程序。
- arm-none-eabi-gcc,名称中的none表示无操作系统,目标应用程序的运行环境是不带操作系统的,例如裸机代码、uboot、内核代码本身。
xiechen@xiechen-Ubuntu:~/2.测试中心$ arm-linux-gnueabihf-gcc -v
使用内建 specs。
COLLECT_GCC=arm-linux-gnueabihf-gcc
目标:arm-linux-gnueabihf
配置为:'/home/tcwg-buildslave/workspace/tcwg-make-release/builder_arch/amd64/label/tcwg-x86_64-build/target/arm-linux-gnueabihf/snapshots/gcc.git~linaro-6.3-2017.05/configure' SHELL=/bin/bash --with-mpc=/home/tcwg-buildslave/workspace/tcwg-make-release/builder_arch/amd64/label/tcwg-x86_64-build/target/arm-linux-gnueabihf/_build/builds/destdir/x86_64-unknown-linux-gnu --with-mpfr=/home/tcwg-buildslave/workspace/tcwg-make-release/builder_arch/amd64/label/tcwg-x86_64-build/target/arm-linux-gnueabihf/_build/builds/destdir/x86_64-unknown-linux-gnu --with-gmp=/home/tcwg-buildslave/workspace/tcwg-make-release/builder_arch/amd64/label/tcwg-x86_64-build/target/arm-linux-gnueabihf/_build/builds/destdir/x86_64-unknown-linux-gnu --with-gnu-as --with-gnu-ld --disable-libmudflap --enable-lto --enable-shared --without-included-gettext --enable-nls --disable-sjlj-exceptions --enable-gnu-unique-object --enable-linker-build-id --disable-libstdcxx-pch --enable-c99 --enable-clocale=gnu --enable-libstdcxx-debug --enable-long-long --with-cloog=no --with-ppl=no --with-isl=no --disable-multilib --with-float=hard --with-fpu=vfpv3-d16 --with-mode=thumb --with-tune=cortex-a9 --with-arch=armv7-a --enable-threads=posix --enable-multiarch --enable-libstdcxx-time=yes --enable-gnu-indirect-function --with-build-sysroot=/home/tcwg-buildslave/workspace/tcwg-make-release/builder_arch/amd64/label/tcwg-x86_64-build/target/arm-linux-gnueabihf/_build/sysroots/arm-linux-gnueabihf --with-sysroot=/home/tcwg-buildslave/workspace/tcwg-make-release/builder_arch/amd64/label/tcwg-x86_64-build/target/arm-linux-gnueabihf/_build/builds/destdir/x86_64-unknown-linux-gnu/arm-linux-gnueabihf/libc --enable-checking=release --disable-bootstrap --enable-languages=c,c++,fortran,lto --build=x86_64-unknown-linux-gnu --host=x86_64-unknown-linux-gnu --target=arm-linux-gnueabihf --prefix=/home/tcwg-buildslave/workspace/tcwg-make-release/builder_arch/amd64/label/tcwg-x86_64-build/target/arm-linux-gnueabihf/_build/builds/destdir/x86_64-unknown-linux-gnu
线程模型:posix
gcc 版本 6.3.1 20170404 (Linaro GCC 6.3-2017.05)
目前大部分 ARM 开发者使用的都是由 Linaro 组织提供的交叉编译器,包括前面使用 APT 安装的 ARM-GCC 工具链,它的来源也是 Linaro。Linaro 是由 ARM 发起,与其它 ARM SOC 公司共同投资的非盈利组织。
arch [-os] [-(gnu)eabi(hf)] -gcc
| 字段 | 含义 |
|---|---|
| arch | 目标芯片架构 |
| os | 操作系统 |
| gnu | C标准库类型 |
| eabi | 应用二进制接口 |
| hf | 浮点模式 |
以安装的 arm-linux-gnueabihf-gcc 编译器为例。
- 表示它的目标芯片架构为 ARM;
- 目标操作系统为 Linux;
- 使用GNU的C标准库即 glibc;
- 使用嵌入式应用二进制接口(eabi);
- 编译器的浮点模式为硬浮点 hard-float。
而另一种名为 arm-linux-gnueabi- gcc 的编译器与它的差别就在于是否带 “hf”,不带 “hf” 表示它使用 soft-float 模式。
五、Linux 系统下的 Hello World
5.1 总体分析
总体上整个程序的编译执行过程,可以按图片从上到下的顺序,分为四大部分的内容:
- 第一部分,上面浅绿色外框部分为程序的编译。
- 第二部分,浅黄色外框部分为Linux内核提供的服务。
- 第三部分,橘色外框部分为glibc库提供的服务。
- 第四部分,浅灰色外框部分,为用户程序。
5.2 程序的编译
- 预处理hello.c,主要是处理程序里面的文件包含、处理宏定义、条件编译。
- 把c文件编译成为汇编文件(.s),其中进行了词法分析,语法分析,语义分析、生成中间代码、对代码进行优化等工作。
- 把汇编文件(.s)编译成可重定位文件(.o)。
- 把可重定位文件(.o)链接成为可执行文件,其中链接可分为静态链接和动态链接
- 静态链接:在编译阶段就会把所有用到的库打包到自己的可执行程序中,其优点是具有较好的兼容性,不依赖外部环境,但是生成的程序比较大。
- 动态链接:在应用程序运行时,链接器去加载外部的共享库,并完成共享库和动态编译程序之间的链接。不同的程序可以共用代码库,节省内存空间。
5.3 Linux 内核提供服务
- 控制台输入./hello命令后,Shell会创建一个新的进程来执行该程序。fork()函数就是用于创建一个新的进程的。这里的进程可以先简单理解为程序的容器。
- exeve()函数可以理解为向上一步新建的进程,填充一个可执行程序(hello)。
- sys_execve()函数为linux系统调用,被exeve()函数调用,这里的系统调用可以理解为是操作系统系统开放给用户的最底层接口。
- do_exeve()函数是sys_execve()函数的核心。
- load_elf_binary()函数会去文件系统中读取hello程序到内存,然后判断它是否是动态链接的可执行程序,如果不是,则进一步判断是否是静态链接的文件。
5.4 glibc 库提供服务
- ld-linux-xx.so是glibc库中的动态连接器。如果hello程序是动态链接程序,该动态链接器会去加载共享库,并完成共享库和程序的链接工作, 然后准备真正开始执行hell程序。
- 相反,如果hello程序是静态编译的程序,则无需再加载链接共享库,直接开始准备执行hello程序。
- 第10和11步分别执行之后.都会开始执行hello程序,_start是程序的真正入口,而该符号在glibc中。也就是说程序的真正入口在glibc。
- __libc_start_main()也是glibc中的函数,用于在执行用户程序前进行一些初始化工作。
5.5 执行用户程序
- 调用用户程序中的mian()函数,开始执行printf打印函数。
- 程序执行完了之后,调用glibc库中的_exit()函数,来结束当前进程。
六、Makefile
6.1 Hello world !
#Makefile格式
#目标:依赖的文件或其它目标
#Tab 命令1
#Tab 命令2
#第一个目标,是最终目标及make的默认目标
#目标a,依赖于目标targetc和targetb
#目标要执行的shell命令 ls -lh,列出目录下的内容
targeta: targetc targetb
ls -lh
echo "Hello World!"
#目标b,无依赖
#目标要执行的shell命令,使用touch创建test.txt文件
targetb:
touch test.txt
#目标c,无依赖
#目标要执行的shell命令,pwd显示当前路径
targetc:
pwd
#目标d,无依赖
#由于abc目标都不依赖于目标d,所以直接make时目标d不会被执行
#可以使用make targetd命令执行
targetd:
rm -f test.txt
这个Makefile文件主要是定义了四个目标 操作,先大致了解它们的关系:
- targeta:这是Makefile中的第一个目标代号,在符号“:”后 面的内容表示它依赖于targetc和targetb目标,它自身的命令为“ls -lh”,列出当前目录下的内容。
- targetb:这个目标没有依赖其它内容,它要执行的命令为“touch test.txt”,即创建一个test.txt文件。
- targetc:这个目标同样也没有依赖其它内容,它要执行的命令为“pwd”,就是简单地显示当前的路径。
- targetd:这个目标无依赖其它内容,它要执行的命令为“rm -f test.txt”,删除 目录下的test.txt文件。与targetb、c不同的是,没有任何其它目标依赖于targetd,而且 它不是默认目标。
xiechen@xiechen-Ubuntu:~/2.测试中心/1.makefile$ make
pwd
/home/xiechen/2.测试中心/1.makefile
touch test.txt
ls -lh
总用量 4.0K
-rw-r--r-- 1 xiechen xiechen 673 8月 5 17:49 makefile
-rw-r--r-- 1 xiechen xiechen 0 8月 5 17:50 test.txt
echo "Hello World!"
Hello World!
xiechen@xiechen-Ubuntu:~/2.测试中心/1.makefile$ make targetd
rm -f test.txt
由于 targetd 不是默认目标,且不被其它任何目标依赖,所以直接 make 的时候 targetd 并没有被执行,想要单独执行 Makefile 中的某个目标,可以使用 ”make 目标名“ 的语法。
6.2 目标与依赖
[目标1]:[依赖]
[命令1]
[命令2]
[目标2]:[依赖]
[命令1]
[命令2]
- 目标:指make要做的事情,可以是一个简单的代号,也可以是目标文件,需要顶格 书写,前面不能有空格或Tab。一个Makefile可以有多个目标,写在最前面的第一 个目标,会被Make程序确立为 “默认目标”,例如前面的targeta、hello_main。
- 依赖:要达成目标需要依赖的某些文件或其它目标。例如前面的targeta依赖 于targetb和targetc,又如在编译的例子中,hello_main依赖于hello_main.c、hello_func.c源文 件,若这些文件更新了会重新进行编译。
- 命令1,命令2…命令n:make达成目标所需要的命令。只有当目标不存在或依赖 文件的修改时间比目标文件还要新时,才会执行命令。要特别注意命令的开头要用“Tab”键,不能 使用空格代替,有的编辑器会把Tab键自动转换成空格导致出错,若出现这种情况请检查自己的编辑器配置。
6.3 伪目标
前面我们在Makefile中编写的目标,在make看来其实都是目标文件,例如make在执行 的时候由于在目录找不到targeta文件,所以每次make targeta的时候,它都会去执行targeta的命令,期待执行后能得到名为targeta的 同名文件。如果目录下真的有targeta、targetb、targetc的文件,即假如目标文件和依 赖文件都存在且是最新的,那么make targeta就不会被正常执行了,这会引起误会。
为了避免这种情况,Makefile使用“.PHONY”前缀来区分目标代号和目标文件,并且这种目 标代号被称为“伪目标”,phony单词翻译过来本身就是假的意思。
#默认目标
#hello_main依赖于hello_main.c和hello_func.c文件
hello_main: hello_main.c hello_func.c
gcc -o hello_main hello_main.c hello_func.c -I .
#clean伪目标,用来删除编译生成的文件
.PHONY:clean
clean:
rm -f *.o hello_main
如果以上代码中不写“.PHONY:clean”语句,并且在目录下创建一个名为clean的文件,那么当 执行“make clean”时,clean的命令并不会被执行。
6.4 默认规则
hello_main 目标文件本质上并不是依赖 hello_main.c 和 hello_func.c 文件,而是依赖于 hello_main.o 和 hello_func.o,把这两个文件链接起来就能得到我们最终想要的 hello_main 目标文件。另外,由于 make 有一条默认规则,当找不到 xxx.o 文件时,会查找目录下的同名 xxx.c 文件进行编译。
从 make 的输出可看到,它先执行了两条额外的 “cc” 编译命令,这是由 make 默认规则执行的,它们把 C 代码编译生成了同名的 .o 文件,然后 make 根据 Makefile 的命令链接这两个文件得到最终目标文件 hello_main。
使用 C 自动编译成 *.o 的默认规则有个缺陷,由于没有显式地表示 *.o 依赖于 .h 头文件,假如我们修改了头文件的内容,那么 *.o 并不会更新,这是不可接受的。并且默认规则使用固定的 “cc” 进行编译,假如我们想使用 ARM-GCC 进行交叉编译,那么系统默 认的 “cc” 会导致编译错误。
6.5 变量的使用
- “=” :延时赋值,该变量只有在调用的时候,才会被赋值
- “:=” :直接赋值,与延时赋值相反,使用直接赋值的话,变量的值定义时就已经确定了。
- “?=” :若变量的值为空,则进行赋值,通常用于设置默认值。
- “+=” :追加赋值,可以往变量后面增加新的内容。
#定义变量
CC=gcc
CFLAGS=-I.
DEPS = hello_func.h
#目标文件
hello_main: hello_main.o hello_func.o
$(CC) -o hello_main hello_main.o hello_func.o
#*.o文件的生成规则
%.o: %.c $(DEPS)
$(CC) -c -o $@ $< $(CFLAGS)
#伪目标
.PHONY: clean
clean:
rm -f *.o hello_main
- 代码的1~4行:分别定义了CC、CFLAGS、DEPS变量,变量的值就是等号右 侧的内容,定义好的变量可通过” (CC)”、” (DEPS)”等价于定义时赋予的变量值”gcc”、”-I.”和”hello_func.h”。
- 代码的第8行:使用$(CC)替代了gcc,这样编写的Makefile非常容易更换 不同的编译器,如要进行交叉编译,只要把开头的编译器名字修改掉即可。
- 代码的第11行:”%”是一个通配符,功能类似”*”,如”%.o”表示所 有以”.o”结尾的文件。所以”%.o:%.c”在本例子中等价 于”hello_main.o: hello_main.c”、”hello_func.o: hello_func.c”,即等价于o文件依赖于c文件的默认规则。不过这行代码后面的” (DEPS)”表示的头文件,所以当头文件修改的话,o文件也会被重新编译。
- 代码的第12行:这行代码出现了特殊的变量” <”,可理解为Makefile文件保 留的关键字,是系统保留的自动化变量,” <”代表了第一个依赖 文件。即” <”表示”%.c”,所以,当第11行的”%”匹配的字符为”hello_func”的话,第1 2行代码等价于:
6.6 自动化变量
| 符号 | 意义 |
|---|---|
| $@ | 匹配目标文件 |
| $% | 与 %仅匹配“库”类型的目标文件 |
| $< | 依赖中的第一个目标文件 |
| $^ | 所有的依赖目标,如果依赖中有重复的,只保留一份 |
| $+ | 所有的依赖目标,即使依赖中有重复的也原样保留 |
| $? | 所有比目标要新的依赖目标 |
6.7 使用分支控制编译平台
#定义变量
#ARCH默认为x86,使用gcc编译器,
#否则使用arm编译器
ARCH ?= x86
TARGET = hello_main
CFLAGS = -I.
DEPS = hello_func.h
OBJS = hello_main.o hello_func.o
#根据输入的ARCH变量来选择编译器
#ARCH=x86,使用gcc
#ARCH=arm,使用arm-gcc
ifeq ($(ARCH),x86)
CC = gcc
else
CC = arm-linux-gnueabihf-gcc
endif
#目标文件
$(TARGET): $(OBJS)
$(CC) -o $@ $^ $(CFLAGS)
#*.o文件的生成规则
%.o: %.c $(DEPS)
$(CC) -c -o $@ $< $(CFLAGS)
#伪目标
.PHONY: clean
clean:
rm -f *.o hello_main
make ARCH=arm
6.8 多级结构工程
#定义变量
#ARCH默认为x86,使用gcc编译器,
#否则使用arm编译器
ARCH ?= x86
TARGET = hello_main
#存放中间文件的路径
BUILD_DIR = build_$(ARCH)
#存放源文件的文件夹
SRC_DIR = sources
#存放头文件的文件夹
INC_DIR = includes .
#源文件
SRCS = $(wildcard $(SRC_DIR)/*.c)
#目标文件(*.o)
OBJS = $(patsubst %.c, $(BUILD_DIR)/%.o, $(notdir $(SRCS)))
#头文件
DEPS = $(wildcard $(INC_DIR)/*.h)
#指定头文件的路径
CFLAGS = $(patsubst %, -I%, $(INC_DIR))
#根据输入的ARCH变量来选择编译器
#ARCH=x86,使用gcc
#ARCH=arm,使用arm-gcc
ifeq ($(ARCH),x86)
CC = gcc
else
CC = arm-linux-gnueabihf-gcc
endif
#目标文件
$(BUILD_DIR)/$(TARGET): $(OBJS)
$(CC) -o $@ $^ $(CFLAGS)
#*.o文件的生成规则
$(BUILD_DIR)/%.o: $(SRC_DIR)/%.c $(DEPS)
#创建一个编译目录,用于存放过程文件
#命令前带“@”,表示不在终端上输出
@mkdir -p $(BUILD_DIR)
$(CC) -c -o $@ $< $(CFLAGS)
#伪目标
.PHONY: clean cleanall
#按架构删除
clean:
rm -rf $(BUILD_DIR)
#全部删除
cleanall:
rm -rf build_x86 build_arm
七、文件操作和系统调用
7.1 存储设备文件系统
- FAT32格式:兼容性好, STM32等MCU也可以通过Fatfs支持FAT32文件系统,大部分SD卡或U盘出厂 默认使用的就是FAT32文件系统。它的主要缺点是技术老旧,单个文件不能超过4GB,非日志型文件系统。
- NTFS格式:单个文件最大支持256TB、支持长文件名、服务器文件管理权限等,而且NTFS是日志型 文件系统。但由于是日志型文件系统,会记录详细的读写操作,相对来说会加快FLASH存储器的损 耗。文件系统的日志功能是指,它会把文件系统的操作记录在磁盘的某个分区,当系统发生故障时,能够 尽最大的努力保证数据的完整性。
- exFAT格式:基于FAT32改进而来,专为FLASH介质的存储器 设计(如SD卡、U盘),空间浪费少。单个文件最大支持16EB,非日志文件系统。
- ext2格式:简单,文件少时性能较好,单个文件不能超过2TB。非日志文件系统。
- ext3格式:相对于ext2主要增加了支持日志功能。
- ext4格式:从ext3改进而来,ext3实际是ext4的子集。它支持1EB的分区,单个文件最大支 持16TB,支持无限的子目录数量,使用延迟分配策略优化了文件的数据块分配,允许自主控制是否使用日志的功能。
- jffs2和yaffs2格式: jffs2和yaffs2是专为FLASH类型存储器设计的文件 系统,它们针对FLASH存储器的特性加入了擦写平衡和掉电保护等特性。由于Nor、NAND FLASH类 型存储器的存储块的擦写次数是有限的(通常为10万次),使用这些类型的文件系统可以减少对存储器的损耗。
Linux内核本身也支持FAT32文件系统,而使用NTFS格式则需要安装额外的工具如ntfs-3g。所以使用开发板出厂的 默认Linux系统时,把FAT32格式的U盘直接插入到开发板是可以自动挂载的,而NTFS格式的则不支持。主机上 的Ubuntu对于NTFS或FAT32的U盘都能自动识别并挂载,因为U buntu发行版安装了相应的支持。目前微软已公开exFAT文件系统的标准,且已把它开源至Linux,未来Linux可能 也默认支持exFAT。
对于非常在意FLASH存储器损耗的场合,则可以考虑使用jffs2或yaffs2等文件系统。
xiechen@xiechen-Ubuntu:~/2.测试中心/1.makefile$ df -T
文件系统 类型 1K-块 已用 可用 已用% 挂载点
udev devtmpfs 5573684 0 5573684 0% /dev
tmpfs tmpfs 1119520 1396 1118124 1% /run
/dev/sda1 ext4 102685624 23871424 73555040 25% /
tmpfs tmpfs 5597584 97436 5500148 2% /dev/shm
tmpfs tmpfs 5120 4 5116 1% /run/lock
tmpfs tmpfs 5597584 0 5597584 0% /sys/fs/cgroup
/dev/loop1 squashfs 261760 261760 0 100% /snap/gnome-3-34-1804/36
/dev/loop3 squashfs 384 384 0 100% /snap/gnome-characters/539
/dev/loop0 squashfs 98944 98944 0 100% /snap/core/9436
/dev/loop6 squashfs 1024 1024 0 100% /snap/gnome-logs/100
/dev/loop4 squashfs 2304 2304 0 100% /snap/gnome-system-monitor/148
/dev/loop2 squashfs 99328 99328 0 100% /snap/core/9665
/dev/loop11 squashfs 384 384 0 100% /snap/gnome-characters/550
/dev/loop8 squashfs 56320 56320 0 100% /snap/core18/1754
/dev/loop13 squashfs 2304 2304 0 100% /snap/gnome-calculator/260
/dev/loop9 squashfs 144128 144128 0 100% /snap/gnome-3-26-1604/100
/dev/loop15 squashfs 261760 261760 0 100% /snap/gnome-3-34-1804/33
/dev/loop5 squashfs 63616 63616 0 100% /snap/gtk-common-themes/1506
/dev/loop12 squashfs 2560 2560 0 100% /snap/gnome-calculator/748
/dev/loop16 squashfs 2304 2304 0 100% /snap/gnome-system-monitor/145
/dev/loop14 squashfs 144128 144128 0 100% /snap/gnome-3-26-1604/98
/dev/loop10 squashfs 35456 35456 0 100% /snap/gtk-common-themes/818
/dev/loop7 squashfs 56320 56320 0 100% /snap/core18/1880
/dev/loop17 squashfs 14976 14976 0 100% /snap/gnome-logs/45
Desktop vboxsf 249427964 60868888 188559076 25% /media/sf_Desktop
tmpfs tmpfs 1119516 28 1119488 1% /run/user/121
tmpfs tmpfs 1119516 12 1119504 1% /run/user/1000
7.2 伪文件系统
Linux内核提供了procfs、sysfs和devfs等伪文件系统。
也被称为进程文件系统,procfs通常会自动挂载在根 目录下的/proc文件夹。procfs为用户提供内核状态和进程信息的接口,功能相 当于Windows的任务管理器。
伪文件系统存在于内存中,通常不占用硬盘空间,它以文 件的形式,向用户提供了访问系统内核数据的接口。用户和应用程序 可以通过访问这些数据接口,得到系统的信息,而且内核允许用户修改内核的某些参数。
7.2.1 procfs 文件系统(process filesystem)
cat /proc/cpuinfo # 查看CPU信息
ls /proc # 查看proc目录
也被称为进程文件系统,procfs通常会自动挂载在根目录下的/proc文件夹。procfs为用户提供内核状态和进程信息的接口,功能相当于Windows的任务管理器。
| 文件名 | 作用 |
|---|---|
| pid* | “pid*”通常就是一个数字,该数字表示的是进程的 PID 号,系统中当前运行的每一个进程都有对应的一个目录,用于记录进程所有相关信息。对于操作系统来说,一个应用程序就是一个进程 |
| self | 该文件是一个软链接,指向了当前进程的目录,通过访问/proc/self/目录来获取当前进程的信息,就不用每次都获取pid |
| thread-self | 该文件也是一个软链接,指向了当前线程,访问该文件,等价于访问“当前进程pid/task/当前线程tid”的内容。一个进程,可以包含多个线程,但至少需要一个进程,这些线程共同支撑进程的运行。 |
| version | 记录了当前运行的内核版本,通常可以使用“uname –r”命令查看 |
| cpuinfo | 记录系统中CPU的提供商和相关配置信息 |
| modules | 记录了目前系统加载的模块信息 |
| meminfo | 记录系统中内存的使用情况,free命令会访问该文件,来获取系统内存的空闲和已使用的数量 |
| filesystems | 记录内核支持的文件系统类型,通常mount一个设备时,如果没有指定文件系统并且它无法确定文件系统类型时,mount会尝试包含在该文件中的文件系统,除了那些标有“nodev”的文件系统。 |
ps # 查看当前进程的 PID 号;
xiechen@xiechen-Ubuntu:~/2.测试中心/1.makefile$ ps
PID TTY TIME CMD
28830 pts/2 00:00:00 bash
28843 pts/2 00:00:00 ra
28880 pts/2 00:00:00 bash
32410 pts/2 00:00:00 ps
xiechen@xiechen-Ubuntu:~/2.测试中心/1.makefile$ ls /proc/28830
arch_status cpuset loginuid numa_maps sched status
attr cwd map_files oom_adj schedstat syscall
autogroup environ maps oom_score sessionid task
auxv exe mem oom_score_adj setgroups timers
cgroup fd mountinfo pagemap smaps timerslack_ns
clear_refs fdinfo mounts patch_state smaps_rollup uid_map
cmdline gid_map mountstats personality stack wchan
comm io net projid_map stat
coredump_filter limits ns root statm
| 文件名 | 文件内容 |
|---|---|
| cmdline | 只读文件,记录了该进程的命令行信息,如命令以及命令参数 |
| comm | 记录了进程的名字 |
| environ | 进程使用的环境变量 |
| exe | 软连接文件,记录命令存放的绝对路径 |
| fd | 记录进程打开文件的情况,以文件描述符作为目录名 |
| fdinfo | 记录进程打开文件的相关信息,包含访问权限以及挂载点,由其文件描述符命名。 |
| io | 记录进程读取和写入情况 |
| map_files | 记录了内存中文件的映射情况,以对应内存区域起始和结束地址命名 |
| maps | 记录当前映射的内存区域,其访问权限以及文件路径。 |
| stack | 记录当前进程的内核调用栈信息 |
| status | 记录进程的状态信息 |
| syscall | 显示当前进程正在执行的系统调用。第一列记录了系统调用号 |
| task | 记录了该进程的线程信息 |
| wchan | 记录当前进程处于睡眠状态,内核调用的相关函数 |
7.2.2 sysfs 文件系统
Linux内核在2.6版本中引入了sysfs文件系统,sysfs通常会自动挂载在根目录下的sys文件夹。sys目录下的文 件/文件夹向用户提供了一些关于设备、内核模块、文件系统以及其他内核组件的信息,如子目录block中存放了所 有的块设备,而bus中存放了系统中所有的总线类型,有i2c,usb,sdi o,pci等。下图中的虚线表示软连接,可以看到所有跟设备 有关的文件或文件夹都链接到了device目录下,类似于将一个大类,根 据某个特征分为了无数个种类,这样使得/sys文件夹的结构层次清晰明了。
| 文件名 | 作用 |
|---|---|
| block | 记录所有在系统中注册的块设备,这些文件都是符号链接,都指向了/sys/devices目录。 |
| bus | 该目录包含了系统中所有的总线类型,每个文件夹都是以每个总线的类型来进行命名。 |
| class | 包含了所有在系统中注册的设备类型,如块设备,声卡,网卡等。文件夹下的文件同样也是一些链接文件,指向了/sys/devices目录。 |
| devices | 包含了系统中所有的设备,到跟设备有关的文件/文件夹,最终都会指向该文件夹。 |
| module | 该目录记录了系统加载的所有内核模块,每个文件夹名以模块命名 |
| fs | 包含了系统中注册文件系统 |
概括来说,sysfs文件系统是内核加载驱动时,根据系统上的设备和总 线构成导出的分级目录,它是系统上设备的直观反应,每个设备在sysfs下都有 唯一的对应目录,用户可以通过具体设备目录下的文件访问设备。
7.2.3 devfs 文件系统
在Linux 2.6内核之前一直使用的是devfs文件系统管理设备,它通 常挂载于/dev目录下。devfs中的每个文件都对应一个设备,用户也可以通过/dev目录下的文件访问硬件。在sysfs出现之前,devfs是在制作根文件系统的时候就已经固定的,这不太方便使用,而当代的devfs通常会在系统运行时使用名为udev的工具根据sysfs目录生成devfs目录。
八、Linux 系统编程
8.1 进程
8.1.1 程序与进程
8.1.1.1 程序
程序(program)是一个普通文件,是为了完成特定任务而准备好的指令序列与数据的集合,这些指令和数据以”可执行映像”的格式保存在磁盘中。正如我们所写的一些代码,经过编译器编译后,就会生成对应的可执行文件,那么这个就是程序,或者称之为可执行程序。
8.1.1.2 进程
进程(process)则是程序执行的具体实例,比如一个可执行文件,在执行的时候,它就是一个进程,直到该程序执 行完毕。那么在程序执行的过程中,它享有系统的资源,至少包括进程的运行环境、CPU、外设、内存、进程ID等资源与 信息,同样的一个程序,可以实例化为多个进程,在Linux系统下使用 ps命令可以查看到当前正在执行的进程,当这个可执行程序运行完毕后,进程也会随之被销毁(可能不是立即销毁,但是总 会被销毁)。
程序并不能单独执行,只有将程序加载到内存中,系统为他分配资源后才能够执行,这种执行的程序称之为进程,也就是说进程 是系统进行资源分配和调度的一个独立单位,每个进程都有自己单独的地址空间。
8.1.1.3 关系
在Linux系统中,程序只是个静态的文件,而进程是一个动态的实体。
其实正如我们运行一个程序(可执行文件),通常在 Shell中输入命令运行就可以了,在这运行的过程中包含了程序到进 程转换的过程,整个转换过程主要包含以下 3 个步骤:
-
查找命令对应程序文件的位置。
-
使用 fork()函数为启动一个新进程。
-
在新进程中调用 exec 族函数装载程序文件,并执行程序文件中的main()函数。
-
程序只是一系列指令序列与数据的集合,它本身没有任何运行的含义,它只是一个静态 的实体。而进程则不同,它是程序在某个数据集上的执行过程,它是一个动态运行的实体,有自己的生命周期,它因启动而产生,因调度而运行,因等待资源或事件而被处于等待状态,因完成任务而被销毁。
-
进程和程序并不是一一对应的,一个程序执行在不同的数据集上运行就会成为不同的进程,可以用进程控制块来唯一地标识系统中的每个进程。而这一点正是程序无法做到的,由于程序没有和数据产生直接的联系,既使是执行不同的数据的程序,他们的指令的集合依然是一样的,所以无法唯一地标识出这些运行于不同数据集上的程序。一般来说,一个进程肯定有一个与之对应的程序,而且有且只有一个。而一个程序有可能没有与之对应的进程(因为这个程序没有被运行),也有可能有多个进程与之对应(这个程序可能运行在多个不同的数据集上)。
-
进程具有并发性而程序没有。
-
进程是竞争计算机资源的基本单位,而程序不是。
8.1.2 进程状态
xiechen@xiechen-Ubuntu:/sys/class/leds/input2::scrolllock$ ps -ux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
xiechen 2711 0.0 0.0 77056 8140 ? Ss 09:13 0:00 /lib/systemd/systemd --user
xiechen 2712 0.0 0.0 261596 2716 ? S 09:13 0:00 (sd-pam)
xiechen 2729 0.0 0.0 206892 5960 tty2 Ssl+ 09:13 0:00 /usr/lib/gdm3/gdm-x-session --run-script i3
xiechen 2731 0.7 0.9 999072 105148 tty2 Sl+ 09:13 0:33 /usr/lib/xorg/Xorg vt2 -displayfd 3 -auth /run/user/1000/gdm/Xauthority -background none -noreset -keeptty -verbose 3
xiechen 2744 0.0 0.0 50048 4360 ? Ss 09:13 0:00 /usr/bin/dbus-daemon --session --address=systemd: --nofork --nopidfile --systemd-activation --syslog-only
xiechen 2747 0.0 0.1 139656 15124 tty2 S+ 09:13 0:00 i3
xiechen 2773 0.0 0.7 432676 80544 ? Sl 09:13 0:01 /usr/bin/fcitx
xiechen 2820 0.0 0.0 49936 3660 ? Ss 09:13 0:00 /usr/bin/dbus-daemon --syslog --fork --print-pid 5 --print-address 7 --config-file /usr/share/fcitx/dbus/daemon.conf
xiechen 2827 0.0 0.0 27592 208 ? SN 09:13 0:00 /usr/bin/fcitx-dbus-watcher unix:abstract=/tmp/dbus-0rFOEgsRrC,guid=39d552ae67d9a5d9511fc9415f2b592c 2820
xiechen 2843 0.0 0.0 54372 372 ? S 09:13 0:00 /usr/bin/VBoxClient --clipboard
xiechen 2845 0.0 0.0 188804 4464 ? Sl 09:13 0:00 /usr/bin/VBoxClient --clipboard
xiechen 2851 0.0 0.0 54372 372 ? S 09:13 0:00 /usr/bin/VBoxClient --display
xiechen 2852 0.0 0.0 54504 2908 ? S 09:13 0:00 /usr/bin/VBoxClient --display
xiechen 2855 0.0 0.0 54372 372 ? S 09:13 0:00 /usr/bin/VBoxClient --seamless
xiechen 2857 0.0 0.0 186608 2784 ? Sl 09:13 0:00 /usr/bin/VBoxClient --seamless
xiechen 2860 0.0 0.0 54372 372 ? S 09:13 0:00 /usr/bin/VBoxClient --draganddrop
xiechen 2862 0.0 0.0 187124 2824 ? Sl 09:13 0:03 /usr/bin/VBoxClient --draganddrop
xiechen 2876 0.0 0.0 11300 320 ? Ss 09:13 0:00 /usr/bin/ssh-agent /usr/bin/sogou-session /usr/bin/im-launch i3
xiechen 2885 0.0 0.0 405572 9148 ? Ssl 09:13 0:00 /usr/bin/dunst
xiechen 2894 0.0 0.0 4624 772 ? S 09:13 0:00 /bin/sh -c i3bar --bar_id=bar-0 --socket="/run/user/1000/i3/ipc-socket.2747"
xiechen 2895 0.0 0.0 96648 9940 ? S 09:13 0:00 i3bar --bar_id=bar-0 --socket=/run/user/1000/i3/ipc-socket.2747
xiechen 2896 0.0 0.0 4624 808 ? S 09:13 0:00 /bin/sh -c /home/xiechen/contrib/net-speed.sh
xiechen 2897 0.0 0.0 4624 860 ? S 09:13 0:00 /bin/sh /home/xiechen/contrib/net-speed.sh
xiechen 2901 0.0 0.0 79468 5168 ? S 09:13 0:00 i3status
xiechen 2902 0.0 0.0 4624 1176 ? S 09:13 0:00 /bin/sh /home/xiechen/contrib/net-speed.sh
xiechen 2910 0.0 0.1 153660 18016 ? S 09:13 0:00 sogou-qimpanel-watchdog
xiechen 2943 0.0 0.0 0 0 ? Z 09:13 0:00 [sh] <defunct>
xiechen 3011 0.0 0.0 349300 6460 ? Ssl 09:13 0:00 /usr/lib/at-spi2-core/at-spi-bus-launcher
xiechen 3016 0.0 0.0 49792 3832 ? S 09:13 0:00 /usr/bin/dbus-daemon --config-file=/usr/share/defaults/at-spi2/accessibility.conf --nofork --print-address 3
xiechen 3020 0.0 0.0 220780 6800 ? Sl 09:13 0:00 /usr/lib/at-spi2-core/at-spi2-registryd --use-gnome-session
xiechen 3023 0.0 0.5 690624 57172 ? Dsl 09:13 0:02 /usr/lib/gnome-terminal/gnome-terminal-server
xiechen 3027 0.0 0.0 286752 7076 ? Ssl 09:13 0:00 /usr/lib/gvfs/gvfsd
xiechen 3032 0.0 0.0 350576 5408 ? Sl 09:13 0:00 /usr/lib/gvfs/gvfsd-fuse /run/user/1000/gvfs -f -o big_writes
xiechen 3041 0.0 0.0 610188 10128 ? Ssl 09:13 0:00 /usr/libexec/xdg-desktop-portal
xiechen 3046 0.0 0.0 424736 6012 ? Ssl 09:13 0:00 /usr/libexec/xdg-document-portal
xiechen 3049 0.0 0.0 266280 4968 ? Ssl 09:13 0:00 /usr/libexec/xdg-permission-store
xiechen 3060 0.0 0.1 534500 15752 ? Ssl 09:13 0:00 /usr/libexec/xdg-desktop-portal-gtk
xiechen 3068 0.0 0.0 24608 5212 pts/0 Ss 09:13 0:00 bash
xiechen 3252 0.0 0.2 74708 22632 pts/0 S+ 09:14 0:00 /usr/bin/python -O /usr/bin/ra
xiechen 3406 0.0 0.0 4624 808 pts/0 S+ 09:14 0:00 /bin/sh -c set -- '/home/xiechen/0.xcCore/1.hobbies/10.深入学习野火开发板.md'; $EDITOR -- "$@"
xiechen 3407 0.0 0.4 1745704 46996 pts/0 Sl+ 09:14 0:02 vim -- /home/xiechen/0.xcCore/1.hobbies/10.深入学习野火开发板.md
xiechen 3413 0.0 0.4 2476596 51208 ? Ssl 09:14 0:00 /usr/bin/python3 /home/xiechen/.vim/plugged/YouCompleteMe/python/ycm/../../third_party/ycmd/ycmd --port=43933 --options_file=/
xiechen 3490 0.0 0.0 4624 804 ? S 09:14 0:00 /bin/sh -c google-chrome
xiechen 3491 1.1 1.6 919120 188348 ? Sl 09:14 0:51 /opt/google/chrome/chrome
xiechen 3496 0.0 0.0 9356 840 ? S 09:14 0:00 cat
xiechen 3497 0.0 0.0 9356 740 ? S 09:14 0:00 cat
xiechen 3500 0.0 0.5 461304 60820 ? S 09:14 0:00 /opt/google/chrome/chrome --type=zygote --no-zygote-sandbox
xiechen 3503 0.0 0.5 461336 60592 ? S 09:14 0:00 /opt/google/chrome/chrome --type=zygote
xiechen 3504 0.0 0.0 27348 3052 ? S 09:14 0:00 /opt/google/chrome/nacl_helper
xiechen 3505 0.0 0.0 27348 4132 ? S 09:14 0:00 /opt/google/chrome/nacl_helper
xiechen 3508 0.0 0.1 461336 15684 ? S 09:14 0:00 /opt/google/chrome/chrome --type=zygote
xiechen 3526 0.0 0.9 3355576 107068 ? Sl 09:14 0:01 sogou-qimpanel
xiechen 3577 0.0 0.7 519392 79040 ? Sl 09:14 0:01 /opt/google/chrome/chrome --type=utility --utility-sub-type=network.mojom.NetworkService --field-trial-handle=7644249088015697
xiechen 3598 1.0 0.8 577000 93492 ? Sl 09:14 0:46 /opt/google/chrome/chrome --type=gpu-process --field-trial-handle=7644249088015697058,16091983410253672671,131072 --gpu-prefer
xiechen 3601 0.0 0.1 477696 16136 ? S 09:14 0:00 /opt/google/chrome/chrome --type=broker
xiechen 3625 2.0 2.0 4961204 235028 ? Sl 09:14 1:33 /opt/google/chrome/chrome --type=renderer --field-trial-handle=7644249088015697058,16091983410253672671,131072 --disable-gpu-c
xiechen 5268 0.1 1.5 4909464 172900 ? Sl 09:35 0:03 /opt/google/chrome/chrome --type=renderer --field-trial-handle=7644249088015697058,16091983410253672671,131072 --disable-gpu-c
xiechen 5283 0.0 0.4 4750016 54704 ? Sl 09:35 0:00 /opt/google/chrome/chrome --type=renderer --field-trial-handle=7644249088015697058,16091983410253672671,131072 --disable-gpu-c
xiechen 6253 0.0 0.0 24872 5840 pts/1 Ss 09:57 0:00 bash
xiechen 8025 0.0 0.0 41420 3556 pts/1 R+ 10:29 0:00 ps -ux
| 状态 | 说明 |
|---|---|
| R | 运行状态。严格来说,应该是”可运行状态”,即表示进程在运行队列中,处于正在执行或即将运行状态,只有在该状态的进程才可能在 CPU 上运行,而同一时刻可能有多个进程处于可运行状态。 |
| S | 可中断的睡眠状态。处于这个状态的进程因为等待某种事件的发生而被挂起,比如进程在等待信号。 |
| D | 不可中断的睡眠状态。通常是在等待输入或输出(I/O)完成,处于这种状态的进程不能响应异步信号。 |
| T | 停止状态。通常是被shell的工作信号控制,或因为它被追踪,进程正处于调试器的控制之下。 |
| Z | 退出状态。进程成为僵尸进程。 |
| X | 退出状态。进程即将被回收。 |
| s | 进程是会话其首进程。 |
| l | 进程是多线程的。 |
| 进程属于前台进程组。 | 进程属于前台进程组。 |
| < | 高优先级任务。 |
8.1.3 启动新进程
8.1.3.1 system()
这个system ()函数是C标准库中提供的,它主要是提供了一种调用其它程序的简单方法。读者可以利用system()函数调用一些应用程序,它产生的结果与从 shell中执行这个程序基本相似。事实上,system()启动了一个运行着/bin/sh的子进程,然后将命令交由它执行。
8.1.3.2 fork()
fork()函数用于从一个已存在的进程中启动一个新进程,新进程称为子进程,而原进程称为父进程。
因为子进程几乎是父进程的完全复制,所以父子两个进程会运行同一个程序,但是这种复制有一个很大的问题,那就是资源与时间都会消耗很大,当发出fork()系统调用时,内核原样复制父进程的整个地址空间并把复制的那一份分配给子进程。
创建一个地址空间的这种方法涉及许多内存访问,消耗许多CPU周期,并且完全破坏了高速缓存中的内容,因此直接复制物理内存对系统的开销会产生很大的影响,更重要的是在大多数情况下,这样直接拷贝通常是毫无意义的,因为许多子进程通过装入一个新的程序开始它们的执行,这样就完全丢弃了所继承的地址空间。因此在Linux中引入一种写时复制技术(Copy On Write,简称COW),我们知道,Linux系统中的进程都是使用虚拟内存地址,虚拟地址与真实物理地址之间是有一个对应关系的,每个进程都有自己的虚拟地址空间,而操作虚拟地址明显比直接操作物理内存更加简便快捷,那么显而易见的,写时复制是一种可以推迟甚至避免复制数据的技术。内核此时并不复制整个进程的地址空间,而是让父子进程共享同一个地址空间(页面)。
那么写时复制的思想就是在于:父进程和子进程共享页面而不是复制页面。而共享页面就不能被修改,无论父进程和子进程何时试图向一个共享的页面写入内容时,都会产生一个错误,这时内核就把这个页复制到一个新的页面中并标记为可写。原来的页面仍然是写保护的,当还有进程试图写入时,内核检查写进程是否是这个页面的唯一属主,如果是则把这个页面标记为对这个进程是可写的。
总的来说,写时复制只会用在需要写入的时候才会复制地址空间,从而使各个进行拥有各自的地址空间,资源的复制是在需要写入的时候才会进行,在此之前,父进程与子进程都是以只读方式共享页面,这种技术使地址空间上的页的拷贝被推迟到实际发生写入的时候。而在绝大多数的时候共享的页面根本不会被写入,例如,在调用fork()函数后立即执行exec(),地址空间就无需被复制了,这样一来fork()的实际开销就是复制父进程的页表以及给子进程创建一个进程描述符。
在fork()启动新的进程后,子进程与父进程开始并发执行,谁先执行由内核调度算法来决定。fork()函数如果成功启动了进程,会对父子进程各返回一次,其中对父进程返回子进程的 PID,对子进程返回0;如果fork()函数启动子进程失败,它将返回-1。失败通常是因为父进程所拥有的子进程数目超过了规定的限制(CHILD_MAX),此时errno将被设为EAGAIN。如果是因为进程表里没有足够的空间用于创建新的表单或虚拟内存不足,errno变量将被设为ENOMEM。
8.1.3.3 exce 系列函数
这个系列函数主要是用于替换进程的执行程序,它可以根据指定的文件名或目录名找到可执行文件,并用它来取代原调用进程的数据段、代码段和堆栈段,在执行完之后,原调用进程的内容除了进程号外,其他全部被新程序的内容替换。另外,这里的可执行文件既可以是二进制文件,也可以是Linux下任何可执行脚本文件。简单来说就是覆盖进程。
- 这些函数可以分为两大类, execl、 execlp和execle的参数个数是可变的。execv、execvp和execve的第2个参数是一个字符串数组,参数以一个空指针NULL结束,无论何种函数,在调用的时候都会通过参数将这些内容传递进去,传入的参数一般都是要运行的程序(可执行文件)、脚本等。
- 名称包含 l 字母的函数(execl、 execlp 和execle)接收参数列表”list”作为调用程序的参数。
- 名称包含 p 字母的函数(execvp 和execlp)接受一个程序名作为参数,然后在当前的执行路径中搜索并执行这个程序;名字不包含p字母的函数在调用时必须指定程序的完整路径,其实就是在系统环境变量”PATH”搜索可执行文件。
- 名称包含 v 字母的函数(execv、execvp 和 execve)的命令参数通过一个数组”vector”传入。
- 名称包含 e 字母的函数(execve 和 execle)比其它函数多接收一个指明环境变量列表的参数,并且可以通过参数envp传递字符串数组作为新程序的环境变量,这个envp参数的格式应为一个以 NULL 指针作为结束标记的字符串数组,每个字符串应该表示为”environment = virables”的形式。
8.1.4 终止进程
8.1.4.1 正常终止
- 从main函数返回。
- 调用exit()函数终止。
- 调用_exit()函数终止。
_exit()函数的作用最为简单:直接通过系统调用使进程终止运行,当然,在终止进程的时候会清除这个进程使用的内存空间,并销毁它在内核中的各种数据结构;而exit()函数则在这些基础上做了一些包装,在执行退出之前加了若干道工序:比如exit()函数在调用exit系统调用之前要检查文件的打开情况,把文件缓冲区中的内容写回文件,这就是”清除I/O缓冲”。
由于在 Linux 的标准函数库中,有一种被称作”缓冲 I/O(buffered I/O)”操作,其特征就是对应每一个打开的文件,在内存中都有一片缓冲区。每次读文件时,会连续读出若干条记录,这样在下次读文件时就可以直接从内存的缓冲区中读取;同样,每次写文件的时候,也仅仅是写入内存中的缓冲区,等满足了一定的条件(如达到一定数量或遇到特定字符等),再将缓冲区中的内容一次性写入文件。这种技术大大增加了文件读写的速度,但也为编程带来了一些麻烦。比如有些数据,认为已经被写入文件中,实际上因为没有满足特定的条件,它们还只是被保存在缓冲区内,这时用_exit()函数直接将进程关闭,缓冲区中的数据就会丢失。因此,若想保证数据的完整性,就一定要使用 exit()函数。
8.1.4.2 异常终止
- 调用abort()函数异常终止。
- 由系统信号终止。
8.1.5 等待进程
通过在父进程中调用wait()或者waitpid()函数让父进程等待子进程的结束。
当一个进程调用了exit()之后,该进程并不会立刻完全消失,而是变成了一个僵尸进程。僵尸进程是一种非常特殊的进程,它已经放弃了几乎所有的内存空间,没有任何可执行代码,也不能被调度,仅仅在进程列表中保留一个位置,记载该进程的退出状态等信息供其他进程收集,除此之外,僵尸进程不再占有任何内存空间。那么无论如何,父进程都要回收这个僵尸进程,因此调用wait()或者waitpid()函数其实就是将这些僵尸进程回收,释放僵尸进程占有的内存空间,并且了解一下进程终止的状态信息。
8.1.5.1 wait()
wait()函数在被调用的时候,系统将暂停父进程的执行,直到有信号来到或子进程结束,如果在调用wait()函数时子进程已经结束,则会立即返回子进程结束状态值。子进程的结束状态信息会由参数wstatus返回,与此同时该函数会返子进程的PID,它通常是已经结束运行的子进程的PID。状态信息允许父进程了解子进程的退出状态,如果不在意子进程的结束状态信息,则参数wstatus可以设成NULL。
wait()函数有几点需要注意的地方:
- wait()要与fork()配套出现,如果在使用fork()之前调用wait(),wait()的返回值则为-1,正常情况下wait()的返回值为子进程的PID。
- 参数wstatus用来保存被收集进程退出时的一些状态,它是一个指向int类型的指针,但如果我们对这个子进程是如何死掉毫不在意,只想把这个僵尸进程消灭掉,(事实上绝大多数情况下,我们都会这样做),我们就可以设定这个参数为NULL。
当然,除此之外,Linux系统中还提供关于等待子进程退出的一些宏定义,我们可以使用这些宏定义来直接判断子进程退出的状态:
- WIFEXITED(status) :如果子进程正常结束,返回一个非零值
- WEXITSTATUS(status): 如果WIFEXITED非零,返回子进程退出码
- WIFSIGNALED(status) :子进程因为捕获信号而终止,返回非零值
- WTERMSIG(status) :如果WIFSIGNALED非零,返回信号代码
- WIFSTOPPED(status): 如果子进程被暂停,返回一个非零值
- WSTOPSIG(status): 如果WIFSTOPPED非零,返回一个信号代码
8.1.5.2 waitpid()
waitpid()函数 的作用和wait()函数一样,但它并不一定要等待第一个终止的子进程,它还有其他选项,比如指定等待某个pid的子进程、提供一个非阻塞版本的wait()功能等。实际上 wait()函数只是 waitpid() 函数的一个特例,在 Linux内部实现 wait 函数时直接调用的就是 waitpid 函数。
8.2 管道
8.2.1 基本概念
一个进程产生数据,通过管道发送给另一个进程,另一个进程读取到数据,这样一来就实现了进程间的通信了。
xiechen@xiechen-Ubuntu:/sys/class/leds/input2::scrolllock$ ps -aux | grep root
root 1 0.0 0.0 225524 9212 ? Ss 09:12 0:03 /sbin/init splash
root 2 0.0 0.0 0 0 ? S 09:12 0:00 [kthreadd]
root 3 0.0 0.0 0 0 ? I< 09:12 0:00 [rcu_gp]
root 4 0.0 0.0 0 0 ? I< 09:12 0:00 [rcu_par_gp]
root 6 0.0 0.0 0 0 ? I< 09:12 0:00 [kworker/0:0H-kb]
ps 列出当前的进程,grep 是一种强大的文本搜索工具,| 是一个管道。将ps命令输出的数据通过管道流向grep,其实在这里就打开了两个进程,ps命令本应该在终端输出信息的,但是它通过管道将输出的信息作为grep命令的输入信息,然后通过搜索之后将合适的信息显示出来,这样子就形成了我们在终端看到的信息。
xiechen@xiechen-Ubuntu:/sys/class/leds/input2::scrolllock$ ps -ux | grep $USER
xiechen 10578 0.0 0.0 41420 3708 pts/1 R+ 11:19 0:00 ps -ux
xiechen 10579 0.0 0.0 16176 1088 pts/1 S+ 11:19 0:00 grep --color=auto xiechen
管道本质上是一个文件,可以看做是ps进程将输出的内容写入管道中,grep进程从管道中读取数据,这样子就是一个可读可写的文件,这其实也遵循了Linux中”一切皆文件”的设计思想,因此Linux系统直接把管道实现成了一种文件系统,借助VFS给应用程序提供操作接口。不过还是要注意的是:虽然管道的实现形态上是文件,但是管道本身并不占用磁盘或者其他外部存储的空间,它占用的是内存空间,因此Linux上的管道就是一个操作方式为文件的内存缓冲区。
8.2.2 管道的分类
Linux系统上的管道分两种类型:
- 匿名管道
- 命名管道
匿名管道最常见的形态就是我们在shell操作中最常用的”|”。它的特点是只能在父子进程中使用,父进程在产生子进程前必须打开一个管道文件,然后fork产生子进程,这样子进程通过拷贝父进程的进程地址空间获得同一个管道文件的描述符,以达到使用同一个管道通信的目的。此时除了父子进程外,没人知道这个管道文件的描述符,所以通过这个管道中的信息无法传递给其他进程。这保证了传输数据的安全性,当然也降低了管道了通用性。
系统还提供了命名管道,它本质是一个文件,位于文件系统中,命名管道可以让多个无相关的进程进行通讯。
8.2.2.1 匿名管道 PIPE
匿名管道(PIPE)是一种特殊的文件,但虽然它是一种文件,却没有名字,因此一般进程无法使用open()来获取他的描述符,它只能在一个进程中被创建出来,然后通过继承的方式将他的文件描述符传递给子进程,这就是为什么匿名管道只能用于亲缘关系进程间通信的原因。
匿名管道不同于一般文件的显著之处是:它有两个文件描述符,而不是一个,一个只能用来读,另一个只能用来写,这就是所谓的”半双工”通信方式。而且它对写操作不做任何保护,即:假如有多个进程或线程同时对匿名管道进行写操作,那么这些数据很有可能会相互践踏,因此一个简单的结论是:匿名管道只能用于一对一的亲缘进程通信。
匿名管道不能使用lseek()来进行所谓的定位,因为他们的数据不像普通文件那样按块的方式存放在诸如硬盘、flash 等块设备上。
总结来说,匿名管道有以下的特征:
- 没有名字,因此不能使用open()函数打开,但可以使用close()函数关闭。
- 只提供单向通信(半双工),也就是说,两个进程都能访问这个文件,假设进程1往文件内写东西,那么进程2 就只能读取文件的内容。
- 只能用于具有血缘关系的进程间通信,通常用于父子进程建通信 。
- 管道是基于字节流来通信的 。
- 依赖于文件系统,它的生命周期随进程的结束而结束。
- 写入操作不具有原子性,因此只能用于一对一的简单通信情形。
- 管道也可以看成是一种特殊的文件,对于它的读写也可以使用普通的read()和write()等函数。但是它又不是普通的文件,并不属于其他任何文件系统,并且只存在于内核的内存空间中,因此不能使用lseek()来定位。
8.2.2.2 命名管道 FIFO
命名管道(FIFO)与匿名管道(PIPE)是不同的,命名管道可以在多个无关的进程中交换数据(通信)。
命名管道不同于无名管道之处在于它提供了一个路径名与之关联,以一个文件形式存在于文件系统中。
通过文件的形式,那么就可以调用系统中对文件的操作,如打开(open)、读(read)、写(write)、关闭(close)等函数。
虽然命名管道文件存储在文件系统中,但数据却是存在于内存中的,这点要区分开。
总结来说,命名管道有以下的特征:
- 有名字,存储于普通文件系统之中。
- 任何具有相应权限的进程都可以使用 open()来获取命名管道的文件描述符。
- 跟普通文件一样:使用统一的 read()/write()来读写。
- 跟普通文件不同:不能使用 lseek()来定位,原因是数据存储于内存中。
- 具有写入原子性,支持多写者同时进行写操作而数据不会互相践踏。
- 遵循先进先出(First In First Out)原则,最先被写入 FIFO 的数据,最先被读出来。
8.2.2.3 pipe()
pipe()函数用于创建一个匿名管道,一个可用于进程间通信的单向数据通道。
8.2.2.3 fifo()
想在不相关的进程之间交换数据,这还不是很方便,我们可以用FIFO文件来完成这项工作,或者称之为命名管道。
一个进程对管道进行读操作时:
- 若该管道是阻塞打开,且当前 FIFO 内没有数据,则对读进程而言将一直阻塞到有数据写入。
- 若该管道是非阻塞打开,则不论 FIFO 内是否有数据,读进程都会立即执行读操作。即如果 FIFO内没有数据,则读函数将立刻返回 0。
一个进程对管道进行写操作时:
- 若该管道是阻塞打开,则写操作将一直阻塞到数据可以被写入。
- 若该管道是非阻塞打开而不能写入全部数据,则读操作进行部分写入或者调用失败。
8.3 信号
8.3.1 概念
信号(signal),又称为软中断信号,用于通知进程发生了异步事件,它是Linux系统响应某些条件而产生的一个事件,它是在软件层次上对中断机制的一种模拟,是一种异步通信方式。
在原理上,一个进程收到一个信号与处理器收到一个中断请求可以说是一样的。
信号是进程间通信机制中唯一的异步通信机制,一个进程不必通过任何操作来等待信号的到达,事实上,进程也不知道信号到底什么时候到达。正如我们所了解的中断服务函数一样,在中断发生的时候,就会进入中断服务函数中去处理,同样的,当进程接收到一个信号的时候,也会相应地采取一些行动。
使用术语“生成(raise)”表示一个信号的产生,使用术语“捕获(catch)”表示进程接收到一个信号。
在Linux系统中,信号可能是由于系统中某些错误而产生,也可以是某个进程主动生成的一个信号。
由于某些错误条件而生成的信号:如内存段冲突、浮点处理器错误或非法指令等,它们由shell和终端处理器生成并且引起中断。
使用kill 命令来查看系统中支持的信号种类。
xiechen@xiechen-Ubuntu:~/2.测试中心/2.linux系统编程$ kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR
31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3
38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8
43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13
48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12
53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7
58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2
63) SIGRTMAX-1 64) SIGRTMAX
Linux系统支持信号62种信号,每种信号名称都以SIG三个字符开头,注意,没有信号值为32和33的信号。
可以将这62中信号分为2大类:
- 信号值为1~31的信号属性非实时信号(也称为不可靠信号),它们是从UNIX 系统中继承下来的信号。
- 信号值为34~64的信号为实时信号(也被称为可靠信号)。
| 信号值 | 名称 | 描述 | 默认处理 |
|---|---|---|---|
| 1 | SIGHUP | 控制终端被关闭时产生。 | 终止 |
| 2 | SIGINT | 程序终止(interrupt)信号,在用户键入INTR字符(通常是Ctrl + C)时发出,用于通知前台进程组终止进程。 | 终止 |
| 3 | SIGQUIT | SIGQUIT 和SIGINT类似,但由QUIT字符(通常是Ctrl + )来控制,进程在因收到SIGQUIT退出时会产生core文件,在这个意义上类似于一个程序错误信号。 | 终止并产生转储文件(core文件) |
| 4 | SIGILL | CPU检测到某进程执行了非法指令时产生,通常是因为可执行文件本身出现错误, 或者试图执行数据段、堆栈溢出时也有可能产生这个信号。 | 终止并产生转储文件(core文件) |
| 5 | SIGTRAP | 由断点指令或其它trap指令产生,由debugger使用。 | 终止并产生转储文件(core文件) |
| 6 | SIGABRT | 调用系统函数 abort()时产生。 | 终止并产生转储文件(core文件) |
| 7 | SIGBUS | 总线错误时产生。一般是非法地址,包括内存地址对齐(alignment)出错。比如访问一个四个字长的整数,但其地址不是4的倍数。它与SIGSEGV的区别在于后者是由于对合法存储地址的非法访问触发的(如访问不属于自己存储空间或只读存储空间)。 | 终止并产生转储文件(core文件) |
| 8 | SIGFPE | 处理器出现致命的算术运算错误时产生,不仅包括浮点运算错误,还包括溢出及除数为0等其它所有的算术的错误。 | 终止并产生转储文件(core文件) |
| 9 | SIGKILL | 系统杀戮信号。用来立即结束程序的运行,本信号不能被阻塞、处理和忽略。如果管理员发现某个进程终止不了,可尝试发送这个信号将进程杀死。 | 终止 |
| 10 | SIGUSR1 | 用户自定义信号。 | 终止 |
| 11 | SIGSEGV | 访问非法内存时产生,进程试图访问未分配给自己的内存,或试图往没有写权限的内存地址写数据。 | 终止 |
| 12 | SIGUSR2 | 用户自定义信号。 | 终止 |
| 13 | SIGPIPE | 这个信号通常在进程间通信产生,比如采用FIFO(管道)通信的两个进程,读管道没打开或者意外终止就往管道写,写进程会收到SIGPIPE信号。此外用Socket通信的两个进程,写进程在写Socket的时候,读进程已经终止,也会产生这个信号。 | 终止 |
| 14 | SIGALRM | 定时器到期信号,计算的是实际的时间或时钟时间,alarm函数使用该信号。 | 终止 |
| 15 | SIGTERM | 程序结束(terminate)信号,与SIGKILL不同的是该信号可以被阻塞和处理。通常用来要求程序自己正常退出,shell命令kill缺省产生这个信号,如果进程终止不了,才会尝试SIGKILL。 | 终止 |
| 16 | SIGSTKFLT | 已废弃。 | 终止 |
| 17 | SIGCHLD | 子进程暂停或终止时产生,父进程将收到这个信号,如果父进程没有处理这个信号,也没有等待(wait)子进程,子进程虽然终止,但是还会在内核进程表中占有表项,这时的子进程称为僵尸进程,这种情况我们应该避免。父进程默认是忽略SIGCHILD信号的,我们可以捕捉它,做成异步等待它派生的子进程终止,或者父进程先终止,这时子进程的终止自动由init进程来接管。 | 忽略 |
| 18 | SIGCONT | 系统恢复运行信号,让一个停止(stopped)的进程继续执行,本信号不能被阻塞,可以用一个handler来让程序在由stopped状态变为继续执行时完成特定的工作 | 恢复运行 |
| 19 | SIGSTOP | 系统暂停信号,停止进程的执行。注意它和terminate以及interrupt的区别:该进程还未结束,只是暂停执行,本信号不能被阻塞,处理或忽略。 | 暂停 |
| 20 | SIGTSTP | 由控制终端发起的暂停信号,停止进程的运行,但该信号可以被处理和忽略,比如用户键入SUSP字符时(通常是Ctrl+Z)发出这个信号。 | 暂停 |
| 21 | SIGTTIN | 后台进程发起输入请求时控制终端产生该信号。 | 暂停 |
| 22 | SIGTTOU | 后台进程发起输出请求时控制终端产生该信号。 | 暂停 |
| 23 | SIGURG | 套接字上出现紧急数据时产生。 | 忽略 |
| 24 | SIGXCPU | 处理器占用时间超出限制值时产生。 | 终止并产生转储文件(core文件) |
| 25 | SIGXFSZ | 文件尺寸超出限制值时产生。 | 终止并产生转储文件(core文件) |
| 26 | SIGVTALRM | 由虚拟定时器产生的虚拟时钟信号,类似于SIGALRM,但是计算的是该进程占用的CPU时间。 | 终止 |
| 27 | SIGPROF | 类似于SIGALRM / SIGVTALRM,但包括该进程用的CPU时间以及系统调用的时间。 | 终止 |
| 28 | SIGWINCH | 窗口大小改变时发出。 | 忽略 |
| 29 | SIGIO | 文件描述符准备就绪, 可以开始进行输入/输出操作。 | 终止 |
| 30 | SIGPWR | 启动失败时产生。 | 终止 |
| 31 | SIGUNUSED | 非法的系统调用。 | 31 |
- 信号的”值”在 x86、PowerPC 和 ARM平台下是有效的,但是别的平台的信号值也许跟这个表的不一致。
- “描述”中注明的一些情况发生时会产生相应的信号,但并不是说该信号的产生就一定发生了这个事件。事实上,任何进程都可以使用kill()函数来产生任何信号。
- 信号 SIGKILL 和 SIGSTOP 是两个特殊的信号,他们不能被忽略、阻塞或捕捉,只能按缺省动作来响应。
- 一般而言,信号的响应处理过程如下:如果该信号被阻塞,那么将该信号挂起,不对其做任何处理,等到解除对其阻塞为止。如果该信号被捕获,那么进一步判断捕获的类型,如果设置了响应函数,那么执行该响应函数;如果设置为忽略,那么直接丢弃该信号。最后才执行信号的默认处理。
8.3.2 非实时信号与实时信号
非实时信号,它主要是因为这类信号不支持排队,因此信号可能会丢失。比如发送多次相同的信号,进程只能收到一次,也只会处理一次,因此剩下的信号将被丢弃。
实时信号,它是支持排队的,发送了多少个信号给进程,进程就会处理多少次。
一般来说,一个进程收到一个信号后不会被立即处理,而是在恰当时机进行处理。一般是在中断返回的时候,或者内核态返回用户态的时候 (这种情况是比较常见的处理方式)。
也就是说,即使这些信号到来了,进程也不一定会立即去处理它,因为系统不会为了处理一个信号而把当前正在运行的进程挂起,这样的话系统的资源消耗太大了,如果不是紧急信号,是不会立即处理的,所以系统一般都会选择在内核态切换回用户态的时候处理信号。比如有时候进程处于休眠状态,但是又收到了一个信号,于是系统就得把信号储存在进程唯一的 PCB(进程控制块)当中。
非实时信号则是不支持排队的,假如此时又有一个信号到来,那么它将被丢弃,这样进程就无法处理这个信号,所以它是不可靠的。
对于实时信号则没有这种顾虑,因为它支持排队,信号是不会被丢弃的,这样子每个到来的信号都能得到有效处理。
8.3.3 信号的处理
生成信号的事件一般可以归为3大类。
- 程序错误;
- 外部事件;
- 显式请求。
信号的生成既可以是同步的,也可以是异步的。
同步信号大多数是程序执行过程中出现了某个错误而产生的,由进程显式请求生成的给自己的信号也是同步的。
异步信号是接收进程可控制之外的事件所生成的信号,这类信号一般是进程无法控制的,只能被动接收,因为进程也不知道这个信号会何时发生,只能在发生的时候去处理它。一般外部事件总是异步地生成信号,异步信号可在进程运行中的任意时刻产生,进程无法预期信号到达的时刻,它所能做的只是告诉Linux内核假如有信号生成时应当采取什么行动(这相当于注册信号对应的处理)。
无论是同步还是异步信号,当信号发生时,我们可以告诉Linux内核采取如下3种动作中的任意一种:
- 忽略信号。大部分信号都可以被忽略,但有两个除外:SIGSTOP和SIGKILL绝不会被忽略。不能忽略这两个信号的原因是为了给超级用户提供杀掉或停止任何进程的一种手段。此外,尽管其他信号都可以被忽略,但其中有一些却不宜忽略。例如,若忽略硬件例外(非法指令)信号,则会导致进程的行为不确定。
- 捕获信号。这种处理是要告诉Linux内核,当信号出现时调用专门提供的一个函数。这个函数称为信号处理函数,它专门对产生信号的事件作出处理。
- 让信号默认动作起作用。系统为每种信号规定了一个默认动作,这个动作由Linux内核来完成,有以下几种可能的默认动作:
- 终止进程并且生成内存转储文件,即写出进程的- 地址空间内容和寄存器上下文至进程当前目录下名为cone的文件中;
- 终止终止进程但不生成core文件。
- 忽略信号。
- 暂停进程。
- 若进程是暂停暂停,恢复进程,否则将忽略信号。
8.3.4 发送信号 API
8.3.4.1 kill()
kill - SIGHUP 666
kill -1 666 # 这里的-1是指信号值为1 的SIGHUP信号;
8.3.4.2 raise()
raise()函数只是进程向自身发送信号的,而没有向其他进程发送信号,可以说kill(getpid(),sig)等同于raise(sig)。
因为它只往自身发送信号,不存在权限问题,也不存在目标进程不存在的情况。
8.3.4.3 alarm()
alarm()也称为闹钟函数,它可以在进程中设置一个定时器,当定时器指定的时间到时,它就向进程发送SIGALARM信号。
如果在seconds秒内再次调用了alarm()函数设置了新的闹钟,则新的设置将覆盖前面的设置,即之前设置的秒数被新的闹钟时间取代,如果新的seconds为0,则之前设置的闹钟会被取消,并将剩下的时间返回。因此它的返回值是之前闹钟的剩余秒数,如果之前未设闹钟则返回0。
8.3.5 捕获信号 API
8.3.5.1 signal()
signal()主要是用于捕获信号,可以改变进程中对信号的默认行为,我们在捕获这个信号后,也可以自定义对信号的处理行为,当收到这个信号后,应该如何去处理它。
8.3.5.2 sigaction()
8.4 消息队列
8.4.1 基本概念
Linux下的进程通信手段基本上是从Unix平台上的进程通信手段继承而来的。而对Unix发展做出重大贡献的两大主力AT&T的贝尔实验室及BSD(加州大学伯克利分校的伯克利软件发布中心)在进程间通信方面的侧重点有所不同。
前者对Unix早期的进程间通信手段进行了系统的改进和扩充,形成了”system V IPC“,通信进程局限在单个计算机内(同一个设备的不同进程间通讯)。
后者则跳过了该限制,形成了基于套接字(socket)的进程间通信机制(多用于不同设备的进程间通讯)。
Linux既有”system V IPC”,又支持socket。
消息队列、共享内存 和 信号量 被统称为 system-V IPC,V 是罗马数字 5,是 Unix 的AT&T 分支的其中一个版本,一般习惯称呼他们为 IPC 对象,这些对象的操作接口都比较类似,在系统中他们都使用一种叫做 key 的键值来唯一标识,而且他们都是“持续性”资源——即他们被创建之后,不会因为进程的退出而消失,而会持续地存在,除非调用特殊的函数或者命令删除他们。
Linux的消息队列(queue)实质上是一个内核地址空间中的内部链表,它有消息队列标识符(queue ID)。通过Linux内核在各个进程直接传递内容,消息顺序地发送到消息队列中,并以几种不同的方式从队列中获得,每个消息队列可以用消息队列标识符唯一地进行识别。
内核中是通过IPC的标识符来区别不同的消息队列,不同的消息队列之间是相互独立的,每个消息队列中的消息,又构成一个独立的链表,这样子就是在内涵中维护多个消息队列,每个消息队列的内部又通过链表维护了不同的消息。
每个内核中的 IPC 结构(消息队列、信号量或共享存储段)都用一个非负整数的标识符(identifier)加以引用。
用户接触到的只是IPC关键字,并非IPC标识符,这是因为IPC标识符是IPC结构的内部名。为使多个合作进程能够在同一IPC对象上会合,需要提供一个外部名方案,即关键字(key)每一个IPC对象都与一个IPC关键字相关联,于是关键字就作为该IPC结构的外部名。要想获得一个唯一标识符,必须使用一个IPC关键字,这样子只要不同进程间使用的关键字是相同的,就可以得到相同的IPC标识符,这样子就能保证访问到相同的消息队列。因此无论何时创建IPC结构,都应指定一个关键字(key),关键字的数据类型由系统规定为 key_t,是一个长整型的数据类型,关键字由内核变换成标识符。
信号承载的信息量少,而消息队列可以承载大量的数据。
8.4.2 创建或获取消息队列 ID
8.4.2.1 msgget()
该函数的作用是得到消息队列标识符或创建一个消息队列对象并返回消息队列标识符。
8.4.3 发送消息与接收消息
8.4.3.1 msgsnd()
这个函数的主要作用就是将消息写入到消息队列,俗称发送一个消息。
8.4.3.2 msgrcv()
msgrcv()函数是从标识符为msqid的消息队列读取消息并将消息存储到msgp中,读取后把此消息从消息队列中删除,也就是俗话说的接收消息。
8.4.4 操作消息队列
8.4.4.1 msgctl()
消息队列是可以被用户操作的,比如设置或者获取消息队列的相关属性,那么可以通过msgctl()函数去处理它。
8.5 system-V IPC 信号量
8.5.1 基本概念
本质上是一个计数器,用于多进程间对共享数据对象的读取,它和管道有所不同,它不以传送数据为主要目的,它主要是用来保护共享资源(信号量也属于临界资源),使得该临界资源在一个时刻只有一个进程独享。
8.5.2 工作原理
由于信号量只能进行两种操作等待和发送信号,即P操作和V操作,锁行为就是P操作,解锁就是V操作。
PV操作是计算机操作系统需要提供的基本功能之一,它们的行为如下。
- P 操作:如果有可用的资源(信号量值大于0),则占用一个资源(给信号量值减去一,进入临界区代码);如果没有可用的资源(信号量值等于 0),则被阻塞到,直到系统将资源分配给该进程(进入等待队列,一直等到资源轮到该进程)。这就像你要把车开进停车场之前,先要向保安申请一张停车卡一样,P 操作就是申请资源,如果申请成功,资源数(空闲的停车位)将会减少一个,如果申请失败,要不在门口等,要不就走人。
- V 操作:如果在该信号量的等待队列中有进程在等待资源,则唤醒一个阻塞的进程。如果没有进程等待它,则释放一个资源(给信号量值加一),就跟你从停车场出去的时候一样,空闲的停车位就会增加一个。
在信号量进行PV操作时都为原子操作(因为它需要保护临界资源)。
注:原子操作:单指令的操作称为原子的,单条指令的执行是不会被打断的
8.5.3 创建或获取一个信号量
8.5.3.1 semget()
功能是创建或者获取一个已经创建的信号量。
8.5.4 信号量操作
8.5.4.1 semop()
对信号量进行PV操作。
对某个进程,在指定SEM_UNDO后,对信号量的当前值的修改都会反应到信号量调整值上,当该进程终止的时候,内核会根据信号量调整值重新恢复信号量之前的值。
8.5.4.2 semctl()
获取或者设置信号量的相关属性。
函数主要是对信号量集的一系列控制操作,根据操作命令cmd的不同,执行不同的操作,依赖于所请求的命令,第四个参数是可选的。
九、Linux 驱动开发
9.1 内核模块
9.1.1 基本概念
内核按照体系结构分为两类:微内核(microkernel)和宏内核(macrokernel)。
Windows操作系统、华为的鸿蒙操作系统就属于微内核结构。微内核是提供操作系统核心功能的内核 的精简版,实现进程管理、存储器管理、进程间通信、I/O设备管理等基本功能,其他功能模块则需要单独进行编译,具有动态扩展性的优点。
Linux操作系统则是采用了宏内核结构。宏内核是将内核所有的功能都编译成一个整体,其优点是执行 效率非常高,缺点也是十分明显的,一旦我们想要修改、增加内核某个功能时,都需要重新编译一遍内核。
为了解决这个问题,Linux引入了内核模块这一机制。
内核模块就是实现了某个功能的一段内核代 码,在内核运行过程,可以加载这部分代码到内核中, 从而动态地增加了内核的功能。基于这种特性,我们进行 设备驱动开发时,以内核模块的形式编写设备驱动,只需要编译相关的驱动代码即可,无需对整个内核进行编译。
| 命令 | 作用 |
|---|---|
| lsmod | 用于显示所有已载入系统的内核模块。 |
| insmod | 用于加载内核模块,通常可载入的模块一般是设备驱动程序 |
| rmmod | 用于卸载不需要的模块。 |
| modinfo | 用于显示内核模块的相关信息。 |
| depmod | 用于分析检测内核模块之间的依赖关系。 |
| modprobe | 同样用于加载内核模块,与insmod不同,modprobe会根据depmod产生的依赖关系,加载依赖的的其他模块。 |
9.1.2 内核模块程序结构
9.1.2.1 加载和卸载内核
9.1.2.1.1 内核模块加载函数
static int __init func_init(void)
{
}
module_init(func_init);
内核模块程序的基本结构包括了以下几个部分:
- 头文件;
- 内核模块加载/卸载函数;
- 内核模块的参数;
- 内核模块导出符号;
- 内核模块的许可证;
- 内核模块的其他信息,如作者,模块的描述信息,模块的别名等;
Linux的头文件都 存放在/usr/include中。编写内核模块所需要的头文件,并不在上述说到的 目录,而是在Linux内核源码中的 include 文件夹中。
编写内核模块中经常要使用到的头文件有以下两个:<linux/init.h>和<linux/module.h>。我们可 以看到在头文件前面也带有一个文件夹的名字linux,对应了include下的linux文件夹。
在C语言中,static关键字的作用如下。
- static修饰的静态局部变量直到程 序运行结束以后才释放,延长了局部变量的生命周期;
- static的修饰全局变量只 能在本文件中访问,不能在其它文件中访问;
- static修饰的函数只能在本文件中 调用,不能被其他文件调用。
内核模块的代码,实际上是内核代码的一部分,假如内核模块定义的函数和内核源代码中的某个函数重复了,编译器就会报错,导致编译失败,因此我们给内核模块的代码加上static修饰符的话,那么就可以避免这种错误。
Linux内核的栈资源十分有限,可能只有一个4096字节大小的页,我们编写的函数与Linux内核 共享同一个栈资源。可想而知,如果在我们的模块程序中定义了一个大的局部数组变量,那么有 可能大致导致堆栈溢出,因此,如果需要很大的空间的变量,应该使用动态分配。
#define __init __section(.init.text) __cold notrace
#define __initdata __section(.init.data)
以上代码 __init、__initdata宏定义(位于内核源码/linux/init.h)中的__init用于修 饰函数,__initdata用于修饰变量。
带有 __init 的修饰符,表示将该函数放到可执行文件的 __init 节 区中,该节区的内容只能用于模块的初始化阶段,初始化阶段执行完毕之 后,这部分的内容就会被释放掉。
#define module_init(x) __initcall(x);
宏定义module_init用于通知内核初始化模块的时候,要使用哪个函数进行初 始化。它会将函数地址加入到相应的节区section中,这样的话,开机的时候就可以自动加载模块了。
9.1.2.1.2 内核模块卸载函数
static void __exit func_exit(void)
{
}
module_exit(func_exit);
使用 __exit,表示将该函数放在可执行文件的 __exit节区,当执行完模块卸载阶 段之后,就会自动释放该区域的空间。
#define __exit __section(.exit.text) __exitused __cold notrace
#define __exitdata __section(.exit.data)
9.1.2.2 内核模块参数
#define module_param(name, type, perm) module_param_named(name, name, type, perm)
#define module_param_array(name, type, nump, perm) module_param_array_named(name, name, type, nump, perm)
在调试内核模块的时候,我们可以使用module_param函数来定义一个变量,控制调试信息的输出。
如果我们定义了一个模块参数,则会在/sys/module/模块名/ parameters下会存在以模块 参数为名的文件。
9.1.2.3 内核模块导出符号
#define EXPORT_SYMBOL(sym) __EXPORT_SYMBOL(sym, "")
符号指的就是函数和变量。
当模块被装入内核后,它所导出的符号都会记录在内核符号表中。在使用命令insmod加载模块后,模块就被连接到了内核,因此可以访问内核的共用符号。
EXPORT_SYMBOL宏用于向内核导出符号,这样的话,其他模块也可以使用导出的符号了。
9.1.2.4 内核模块许可证
#define MODULE_LICENSE(_license) MODULE_INFO(license, _license)
Linux 是一款免费的操作系统,采用了GPL协议,允许用户可以任意修改其源代码。
GPL协议的主要内容是软件产品中即使使用了某个GPL协议产品提供的库,衍生出一个新产品,该软件产品都必须采用 GPL 协议,即必须是开源和免费使用的,可见GPL协议具有传染性。
在Linux内核版本2.4.10之后,模块必须通过MODULE_LICENSE宏声明此模块的许 可证,否则在加载此模块时,会提示内核被污染。
9.1.2.5 内核模块的说明
#define MODULE_DESCRIPTION(_description) MODULE_INFO(description, _description)
模块信息中“description”信息则来自宏MODULE_DESCRIPTION,该宏用于描述该模块的功能作用。
#define MODULE_ALIAS(_alias) MODULE_INFO(alias, _alias)
模块信息中“alias”信息来自于宏定义MODULE_ALIAS。该宏定义用于给内核 模块起别名。
注意,在使用该模块的别名时,需要将该模块复制到/lib/modules/内核 源码/下,使用命令depmod更新模块的依赖关系,否则的话,Linux内核不知道这个模块还有另一个名字。
9.1.3 案例
9.1.3.1 源码
arm 上的案例源码如下。
include <linux/init.h>
include <linux/module.h> // 写内核模块必须要包含的;
//默认不输出调试信息
//权限有限制
bool debug_on = 0; // 定义了一个布尔类型的模块参数 debug_on,用来打开 debug 消息的输出;
module_param(debug_on, bool, S_IRUSR); // 是否开启串口打印信息;
static int __init hello_init(void)
{
if (debug_on)
printk("[ DEBUG ] debug info output\n");
printk("Hello World Module Init\n"); // 使用内核提供的打印函数;
return 0;
}
module_init(hello_init); // 使用 hello_init 函数来进行初始化;
static void __exit hello_exit(void)
{
printk("Hello World Module Exit\n");
}
module_exit(hello_exit); // 使用宏 module_exit 在内核注册该模块的卸载函数;
MODULE_LICENSE("GPL"); // 必须声明该模块使用遵循的许可证,这里我们设置为 GPL 协议。
MODULE_AUTHOR("xiechen");
MODULE_DESCRIPTION("hello world module");
MODULE_ALIAS("test_module");
Linux 上的环境如下。
xiechen@xiechen-Ubuntu:~/2.测试中心/2.linux系统编程$ uname -r
5.4.0-42-generic
xiechen@xiechen-Ubuntu:~/2.测试中心/2.linux系统编程$ lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 18.04.4 LTS
Release: 18.04
Codename: bionic
Linux 上的案例源码如下。
include<linux/module.h>
include<linux/kernel.h>
include<linux/init.h>
static int __init lkp_init(void)
{
printk("<1>Hello, World! from the kernel space...\n");
return 0;
}
static void __exit lkp_cleanup(void)
{
printk("<1>Good Bye, World! leaving kernel space...\n");
}
module_init(lkp_init); // 注册模块;
module_exit(lkp_cleanup); // 注销模块;
MODULE_LICENSE("GPL"); //告诉内核该模块具有GNU公共许可证;
9.1.3.2 Makefile
编译Linux内核所采用的Kbuild系统,因此在编译内核模块时,我们需要指定环境变量ARCH和CROSS_COMPILE的值。
KERNEL_DIR=/home/embedfire/module/linux-imx
obj-m := hello_world.o
all:
$(MAKE) -C $(KERNEL_DIR) M=$(CURDIR) modules
clean:
$(MAKE) -C $(KERNEL_DIR) M=$(CURDIR) clean
以上代码中提供了一个关于编译内核模块的Makefile。该Makefile定义了 变量KERNEL_DIR,来保存内核源码的目录。变量obj-m保存着需要编译成模块的目标文件名。 “ (CURDIR) 表明然后返回到当前目录,读取并执行当前目录的Makefile,开始编译内核模块。CURDIR是make的 内嵌变量,自动设置为当前目录。
执行“make ARCH=arm CROSS_COMPILE=arm-linux-gnueabihf-”命令,生成内核模块hello_world.ko。
obj-m := testKernel.o
CURRENT_PATH := $(shell pwd)
LINUX_KERNEL := $(shell uname -r)
LINUX_KERNEL_PATH := /usr/src/linux-headers-$(LINUX_KERNEL)
all:
make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) modules
clean:
make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) clean
9.1.3.3 案例结果
xiechen@xiechen-Ubuntu:~/2.测试中心/2.linux系统编程$ make
make -C /usr/src/linux-headers-5.4.0-42-generic M=/home/xiechen/2.测试中心/2.linux系统编程 modules
make[1]: 进入目录“/usr/src/linux-headers-5.4.0-42-generic”
CC [M] /home/xiechen/2.测试中心/2.linux系统编程/testKernel.o
Building modules, stage 2.
MODPOST 1 modules
CC [M] /home/xiechen/2.测试中心/2.linux系统编程/testKernel.mod.o
LD [M] /home/xiechen/2.测试中心/2.linux系统编程/testKernel.ko
make[1]: 离开目录“/usr/src/linux-headers-5.4.0-42-generic”
xiechen@xiechen-Ubuntu:~/2.测试中心/2.linux系统编程$ ls
Makefile modules.order Module.symvers testKernel.c testKernel.ko testKernel.mod testKernel.mod.c testKernel.mod.o testKernel.o
xiechen@xiechen-Ubuntu:~/2.测试中心/2.linux系统编程$ insmod testKernel.ko
insmod: ERROR: could not insert module testKernel.ko: Operation not permitted
xiechen@xiechen-Ubuntu:~/2.测试中心/2.linux系统编程$ sudo insmod testKernel.ko
[sudo] xiechen 的密码:
xiechen@xiechen-Ubuntu:~/2.测试中心/2.linux系统编程$ sudo lsmod | grep testKernel
testKernel 16384 0
xiechen@xiechen-Ubuntu:~/2.测试中心/2.linux系统编程$ cat syslog | grep Hello
cat: syslog: 没有那个文件或目录
xiechen@xiechen-Ubuntu:~/2.测试中心/2.linux系统编程$ cat /var/losyslog | grep Hello
local/ lock/ log/
xiechen@xiechen-Ubuntu:~/2.测试中心/2.linux系统编程$ cat /var/log/syslog | grep Hello
Aug 6 18:57:11 xiechen-Ubuntu kernel: [ 8143.203249] <1>Hello, World! from the kernel space...
xiechen@xiechen-Ubuntu:~/2.测试中心/2.linux系统编程$ rmmod testKernel
rmmod: ERROR: ../libkmod/libkmod-module.c:793 kmod_module_remove_module() could not remove 'testKernel': Operation not permitted
rmmod: ERROR: could not remove module testKernel: Operation not permitted
xiechen@xiechen-Ubuntu:~/2.测试中心/2.linux系统编程$ sudo rmmod testKernel
9.2 字符设备驱动
Linux中,根据设备的类型可以分为三类:字符设备、块设备和网络设备。
字符设备:应用程序按字节/字符来读写数据,通常不支持随机存取。我们常用的键盘、串口都是字符设备。
块设备:应用程序可以随机访问设备数据。典型的块设备有硬盘、SD卡、闪存等,应用程序 可以寻址磁盘上的任何位置,并由此读取数据。此外,数据的读写只能以块的倍数进行。
网络设备是一种特殊设备,它并不存在于/dev下面,主要用于网络数据的收发。
9.3 内存管理单元 MMU
在linux环境直接访问物理内存是很危险的,如果用户不小心修改了内存中的数据,很有可能造成错误甚至系统崩溃。 为了解决这些问题内核便引入了MMU。
MMU为编程提供了方便统一的内存空间抽象,其实我们的程序中所写的变量地址是虚拟内存当中的地址, 倘若处理器想要访问这个地址的时候,MMU便会将此虚拟地址(Virtual Address)翻译成实际的物理地址(Physical Address), 之后处理器才去操作实际的物理地址。
MMU是一个实际的硬件,并不是一个软件程序。他的主要作用是将虚拟地址翻译成真实的物理地址同时管理和保护内存, 不同的进程有各自的虚拟地址空间,某个进程中的程序不能修改另外一个进程所使用的物理地址,以此使得进程之间互不干扰,相互隔离。 而且我们可以使用虚拟地址空间的一段连续的地址去访问物理内存当中零散的大内存缓冲区。
很多实时操作系统都可以运行在无MMU的CPU中, 比如uCOS、FreeRTOS、uCLinux,以前想CPU也运行linux系统必须要该CPU具备MMU,但现在Linux也可以在不带MMU的CPU中运行了。
MMU具有如下功能:
- 保护内存。MMU给一些指定的内存块设置了读、写以及可执行的权限,这些权限存储在页表当中,MMU会检查CPU当前所处的是特权模式还是用户模式,如果和操作系统所设置的权限匹配则可以访问,如果CPU要访问一段虚拟地址,则将虚拟地址转换成物理地址,否则将产生异常,防止内存被恶意地修改。
- 提供方便统一的内存空间抽象,实现虚拟地址到物理地址的转换。CPU可以运行在虚拟的内存当中,虚拟内存一般要比实际的物理内存大很多,使得CPU可以运行比较大的应用程序。
物理地址就是内存单元的绝对地址,好比你电脑上插着一张8G的内存条,则第一个存储单元便是物理地址0x0000, 内存条的第6个存储单元便是0x0005,无论处理器怎样处理,物理地址都是它最终的访问的目标。
当CPU开启了MMU时,CPU发出的地址将被送入到MMU,被送入到MMU的这段地址称为虚拟地址, 之后MMU会根据去访问页表地址寄存器然后去内存中找到页表(假设只有一级页表)的条目,从而翻译出实际的物理地址
9.4 设备树
include <dt-bindings/input/input.h>
include "imx6ull.dtsi" ---------------①
/ { --------------------②
model = "Seeed i.MX6 ULL NPi Board";
compatible = "fsl,imx6ull-14x14-evk", "fsl,imx6ull";
aliases {
pwm0 = &pwm1;
pwm1 = &pwm2;
pwm2 = &pwm3;
pwm3 = &pwm4;
};
chosen {
stdout-path = &uart1;
};
memory {
reg = <0x80000000 0x20000000>;
};
reserved-memory {
#address-cells = <1>;
#size-cells = <1>;
ranges;
linux,cma {
compatible = "shared-dma-pool";
reusable;
size = <0x14000000>;
linux,cma-default;
};
};
};
&cpu0 { --------------------③
dc-supply = <®_gpio_dvfs>;
clock-frequency = <800000000>;
};
&clks { --------------------④
assigned-clocks = <&clks IMX6UL_CLK_PLL4_AUDIO_DIV>;
assigned-clock-rates = <786432000>;
};
&fec1 { --------------------⑤
pinctrl-names = "default";
pinctrl-0 = <&pinctrl_enet1>;
phy-mode = "rmii";
phy-handle = <ðphy0>;
status = "okay";
};
- 第一部分,头文件。
- 第二部分,添加设备树节点。
- 第三部分,对已经存在的设备树节点追加内容。
十、Linux 内核调试
10.1 GDB
10.1.1 安装
sudo apt install gdb -y
10.1.2 gdb 启动应用程序
gdb -q hello
加-q参数,启动时不会打印gdb的默认信息,界面清爽干净些。
10.1.3 查看源码
输入list(简写l)命令可以查看程序源代码,默认显示10行,通过回车键不断查看剩余代码。
l
10.1.4 运行程序
执行run(简写r)命令用于运行代码,在程序结束或者遇到断点处停下。
r
10.1.5 设置断点
运行break(简写b)命令可以在指定行设置一个断点,断点调试是程序调试里面使用频率最高的技巧。
设置方法为“b”命令后加上相应的行号。
b
10.1.6 查看断点信息
info b
- NUM:断点编号
- Disp:断点执行一次之后是否还有效(keep:有效 dis:无效)
- Enb:当前断点是否有效(y:有效 n:无效)
- Address:内存地址
10.1.7 单步调试
c
n
s
continue(简写c):继续执行,到下一个断点处(或运行结束)。
next(简写n):单步执行,跳过子函数。
strp(简写s):单步执行,进入子函数。
10.1.8 查看变量
使用print(简写p)指令可以查看变量的值,用法为print+变量名。
p i
10.1.9 清除断点
clear 10
使用clear指令可以删除某一行对应的断点,用法为clear+行号。
10.1.10 运行至函数结束
finish
使用finish指令可以让程序运行到函数结束位置。
10.1.11 显示源代码窗口
layout src
程序运行以后,使用“layout src”命令可以显示源代码窗口,当前执行代码会高亮标志,单步调试非常方便。
10.1.12 退出 gdb
q
执行quit(简写q)会退出gdb调试,返回到控制台终端。
10.2 CGDB 的使用
cgbd是gdb的终端界面增强版,相比windows下的visual studio而言, 它的功能显得十分轻量级而没有太多繁杂,它有上下两栏窗口,上栏的窗口支持vi编辑器的语法, 可以方便的使用它来进行字符串定位等功能。在gdb下使用“layout src”时,界面往往容易花屏, 而cgbd更加的稳定可靠。
10.2.1 安装
sudo apt install cgdb -y
10.3 核心转储调试
10.3.1 core 文件简介
核心转储文件(core文件,也被称之为core dump文件,可能某些书籍上称之为“内核转储文件”,都是一样的,不必纠结名称) 是操作系统在进程收到某些信号而终止运行时,将此时进程地址空间的内容以及有关进程状态的其他信息写入一个磁盘文件, 这个文件就是核心转储文件,它里面包含了进程崩溃时的所有信息,比如包含终止时进程内存的映像、寄存器状态,堆栈指针, 内存管理信息等,而这种信息往往用于调试,比如在gdb调试器使用,导致进程终止运行的信号可以在系统的signal列表中找到。
简单的说,在一个程序崩溃时,系统会在指定目录下生成一个core文件,core文件主要是用来调试的。
10.3.2 打开或关闭 core 文件的生成
在默认情况下,系统是没有打开core文件生成的,可以通过以下命令打开core文件的生成。
ulimit -c unlimited # 改为无限制大小;
系统是否打开了core文件的生成,那么可以通过以下命令判断,如果终端打印的值是0,则代表系统并未开启 生成core文件的功能,而如果是其他数值:比如1024,这代表系统最大可以产生1024字节的core文件,而如果是unlimited则 代表系统不限制core文件的大小,只要有足够的磁盘空间,可以产生10G、100G、甚至是10000G的core文件,当然啦,你的程序 有足够大才行。
ulimit -c # 检验是否打开core文件生成;
ulimit -c 1024000 # 改为限制大小 1024000 字节;
10.3.3 设置永久生效
在 profile 文件中添加一句代码 ulimit -c xxxx 即可。
10.3.4 不生成核心转储文件的情况
linux系统在多种情况下不会生成核心转储文件:
- 该进程无权写入核心转储文件。在默认情况下,产生的核心转储文件名称为core或core.pid,其中pid是转储核心转储的进程的ID,并在当前进程的工作目录中创建,而如果核心转储文件创建失败或者该目录不可写,或者存在相同名称的文件且该文件是不可写的(它是目录或符号链接),那么在进程奔溃时将无法产生核心转储文件。
- 已经存在一个与可用于核心转储的名称相同的(可写的,常规的)文件,但是该文件有多个硬链接。
- 用于创建核心转储文件的文件系统已满,存放不下心产生的core文件
- 文件系统是只读形式的。
- 要在其中创建核心转储文件的目录不存在。
- 系统中核心转储文件大小资源限制设置为0,或者核心转储文件大小已经超过core文件限制的上限。
10.3.5 指定核心转储的文件名和目录
在默认情况下,系统在进程崩溃时产生的core文件是存在与该进程的程序文件相同的目录下的,并且固定命名为core, 如此此时系统中有多个程序文件都存放在同一个目录下,而恰巧有多个进程崩溃,那么产生的core文件就会相互覆盖, 而如果我们想要分析他们,那就没法去分析了,因此我们可以通过修改配置,让产生的核心转储文件命名包含相应的信息, 而不会导致覆盖,也可以指定核心转储文件的路径。
只需在 /etc/sysctl.conf 文件中,设置kernel.core_pattern的值即可。
vi /etc/sysctl.conf
kernel.core_pattern = core_%e_%p # 这代表着在当前目录下产生core文件;
kernel.core_uses_pid = 0
kernel.core_pattern = /var/core/core_%e_%p # 在/var/core目录下产生core文件;
kernel.core_uses_pid = 0
其中core_pattern的配置中%e, %p分别代表以下参数:
- %e:所dump的文件名
- %p:所dump的进程PID
- %c:转储文件的大小上限
- %g:所dump的进程的实际组ID
- %h:主机名
- %s:导致本次coredump的信号
- %t:转储时刻(由1970年1月1日起计的秒数)
- %u:所dump进程的实际用户ID
如果 /proc/sys/kernel/core_uses_pid 文件的内容被设置为1,即使 kernel.core_pattern 中没 有设置%p,最后生成的core文件名仍会加上进程ID。
sudo /sbin/sysctl -p # 立刻生效配置;
10.3.6 强制某个进程产生 core dump
可以尝试在外部让进程崩溃, 从而产生core文件,根据linux的信号默认的处理行为, SIGQUIT,SIGABRT, SIGFPE和SIGSEGV 都可以让该进程产生core文件, 那么我们可以手动发送这些信号让进程终止并且产生core文件,前提是进程没有处理这些信号。
还有一种方法,在你认为程序可能出现卡死的地方主动调用 abort() 函数产生core文件,这个函数首先取消阻止SIGABRT信号, 然后为调用进程引发该信号(就像调用了 raise() 函数一样),除此之外还有可以使用gdb调试工具来产生core文件。
10.3.7 使用 gdb 调试 core 文件
gdb [程序文件] [core文件]
xiechen@xiechen-Ubuntu:~/2.测试中心/2.linux系统编程$ ./targets
这是一个错误
段错误 (核心已转储)
xiechen@xiechen-Ubuntu:~/2.测试中心/2.linux系统编程$ ls
core_dump.c core_dump.o core_targets_21186 targets test
xiechen@xiechen-Ubuntu:~/2.测试中心/2.linux系统编程$ gdb targets core_targets_21186
GNU gdb (Ubuntu 8.1-0ubuntu3.2) 8.1.0.20180409-git
Copyright (C) 2018 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-linux-gnu".
Type "show configuration" for configuration details.
For bug reporting instructions, please see:
<http://www.gnu.org/software/gdb/bugs/>.
Find the GDB manual and other documentation resources online at:
<http://www.gnu.org/software/gdb/documentation/>.
For help, type "help".
Type "apropos word" to search for commands related to "word"...
Reading symbols from targets...done.
[New LWP 21186]
Core was generated by `./targets'.
13 *a = 0x1;
单步调试的案例如下。
下面是gdb调试的步骤:
首先在main函数中打一个断点
(gdb) b main
Breakpoint 1 at 0x400b55: file core_dump.c, line 8.
运行到断点处
(gdb) r
Starting program: /home/jiejie/embed_linux_tutorial/base_code/linux_debug/core_dump/targets
Breakpoint 1, main () at core_dump.c:8
8 int *a = NULL;
单步运行
(gdb) s
10 printf("这是一个错误\n");
(gdb) s
这是一个错误
13 *a = 0x1;
运行到第13行这里就出现错误了
(gdb) s
Program received signal SIGSEGV, Segmentation fault.
0x0000000000400b6d in main () at core_dump.c:13
13 *a = 0x1;
退出gdb调试
(gdb) quit
A debugging session is active.
Inferior 1 [process 19261] will be killed.
Quit anyway? (y or n) y
10.4 backtrace 函数调用栈
在写代码的时候,我们会封装很多函数,而这些函数之中又会调用其他的函数,当程序每次调用函数的时候,就会跳转到函数的地方去执行,那么这期间就有很多信息产生了。
比如:调用函数的地方,函数的参数,被调用函数的变量等,这些信息其实是存储在栈中的。
其实更确切地说,这些信息是存储在函数调用信息帧中的,每个函数及其变量都被分配了一个帧(frame),这些函数信息帧就组成了函数调用栈。
使用 gdb 调试工具就可以查看函数调用栈的内容信息,可以清晰地看到各个函数的调用顺序以及各函数的输入形参值,是分析程序的执行流程和输入依赖的重要手段。
gdb提供了一些指令可以查看这些帧中的信息,当查询函数变量的信息时,gdb就是从这个被选中的帧内获取信息,但是查看被选中帧外的变量信息是非法的,当程序运行停止的时候,gdb会自动选择当前被调用的函数帧,并且打印简单帧信息。
10.4.1 查看栈信息
- bt :bt是 backtrace 指令的缩写,显示所有的函数调用栈的信息,栈中的每个函数都被分配了一个编号,最近被调用的函数在 0 号帧中(栈顶),并且每个帧占用一行。
- bt n :显示函数调用栈从栈顶算起的n帧信息(n 表示一个正整数)。
- bt -n :显示函数调用栈从栈底算起的n帧信息。
- bt full :显示栈中所有信息如:函数参数,本地变量等。
- bt full n :显示函数调用栈从栈顶算起的n帧的所有信息。
- bt full -n :显示函数调用栈从栈底算起的n帧的所有信息。
10.4.2 查看帧信息
上面的bt指令主要是查看栈的信息,而每一帧都会有详细的信息,这些函数调用信息帧包括:调用函数的地方,函数的参数等。如果想查看栈中某一帧的信息,首先要做的是切换当前栈。这时候需用用到 frame 指令(缩写形式为 f)。
- f n: 它的功能是切换到编号为 n 的栈帧(n 表示一个正整数),并显示相关信息。
10.4.3 up / down
除了使用 frame 指令切换栈帧外,还可以使用 up 和 down 指令。
- down n :表示往栈顶方向下移 n 层(n 表示一个正整数,默认值为 1)。
- up n :表示往栈底方向上移 n 层。
10.4.4 查看更详细的帧信息
info 指令是一个很强大的指令,使用它可以查看各种变量的值,如果我们希望看到详细的函数调用信息帧的信息,如:
- 函数地址
- 调用函数的地址
- 被调用函数的地址
- 当前函数由哪种编程语言编写
- 函数参数地址及形参值
- 局部变量的地址
- 当前桢中存储的寄存器等
可以使用以下指令:
- info frame : 指令的缩写形式为 i f ,查看函数调用帧的所有信息。
- info args :查看函数变量的值。
- info locals :查看本地变量的信息。
除此之外 info 指令还可以查看当前寄存器的值:
- info registers :查看寄存器的情况(除了浮点寄存器)。
- info all-registers :查看所有寄存器的情况(包括浮点寄存器)。
10.4.5 案例
include <sys/types.h>
include <unistd.h>
include <stdio.h>
include <stdlib.h>
void test1(int arg)
{
int num;
num = arg;
printf("\t\t---我是 test%d 函数\n", num);
}
void test2(int arg)
{
int num;
num = arg;
printf("\t--我是 test%d 函数\n", num);
printf("\t-- test%d 开始调用 test1 \n", num);
test1(1);
printf("\t-- test%d 结束调用 test1 \n", num);
printf("\t--结束调用 test%d \n", num);
}
void test3(int arg)
{
int num;
num = arg;
printf("-我是 test%d 函数\n", num);
printf("- test%d 开始调用 test2 \n", num);
test2(2);
printf("- test%d 结束调用 test1 \n", num);
printf("-结束调用 test%d \n", num);
}
int main(void)
{
test3(3);
sleep(1); // 防止进程过快退出
return 0;
}
info frame 指令查看函数调用帧的所有信息,在这步操作前我们切换回到test1函数中(切换帧)。
xiechen@xiechen-Ubuntu:~/2.测试中心/2.linux系统编程$ gdb a.out
GNU gdb (Ubuntu 8.1-0ubuntu3.2) 8.1.0.20180409-git
Copyright (C) 2018 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-linux-gnu".
Type "show configuration" for configuration details.
For bug reporting instructions, please see:
<http://www.gnu.org/software/gdb/bugs/>.
Find the GDB manual and other documentation resources online at:
<http://www.gnu.org/software/gdb/documentation/>.
For help, type "help".
Type "apropos word" to search for commands related to "word"...
Reading symbols from a.out...(no debugging symbols found)...done.
(gdb) r
Starting program: /home/xiechen/2.测试中心/2.linux系统编程/a.out
-我是 test3 函数
- test3 开始调用 test2
--我是 test2 函数
-- test2 开始调用 test1
---我是 test1 函数
-- test2 结束调用 test1
--结束调用 test2
- test3 结束调用 test1
-结束调用 test3
[Inferior 1 (process 22516) exited normally]
(gdb) b test1
Breakpoint 1 at 0x55555555468e
(gdb) r
Starting program: /home/xiechen/2.测试中心/2.linux系统编程/a.out
-我是 test3 函数
- test3 开始调用 test2
--我是 test2 函数
-- test2 开始调用 test1
Breakpoint 1, 0x000055555555468e in test1 ()
(gdb) bt
0 0x000055555555468e in test1 ()
1 0x00005555555546fb in test2 ()
2 0x0000555555554771 in test3 ()
3 0x00005555555547ae in main ()
(gdb) bt 2
0 0x000055555555468e in test1 ()
1 0x00005555555546fb in test2 ()
(More stack frames follow...)
(gdb) bt -2
2 0x0000555555554771 in test3 ()
3 0x00005555555547ae in main ()
(gdb) f 2
2 0x0000555555554771 in test3 ()
(gdb) f 3
3 0x00005555555547ae in main ()
(gdb) f 0
0 0x000055555555468e in test1 ()
(gdb) i f
Stack level 0, frame at 0x7fffffffdb80:
rip = 0x55555555468e in test1; saved rip = 0x5555555546fb
called by frame at 0x7fffffffdbb0
Arglist at 0x7fffffffdb70, args:
Locals at 0x7fffffffdb70, Previous frame's sp is 0x7fffffffdb80
Saved registers:
rbp at 0x7fffffffdb70, rip at 0x7fffffffdb78
这里面有很多信息:
- 当前桢的地址:0x7fffffffe030。
- rip的值:0x400b58。
- 此处引申介绍一下rip是什么:它是指令地址寄存器,用来存储 CPU 即将要执行的指令地址。每次 CPU 执行完相应的汇编指令之后,rip 寄存器的值就会自行累加,rip 无法直接赋值。
- 当前桢函数:test1 (backtrace.c:9)。
- 调用者的rip值:saved rip = 0x400bbe。
- 调用者的帧地址:0x7fffffffe060。
- 源代码所用的程序的语言: source language c。
- 当前桢的参数的地址及值:Arglist at 0x7fffffffe020, args: arg=1。
- 当前帧中局部变量的地址:Locals at 0x7fffffffe020, Previous frame’s sp is 0x7fffffffe030。
- 当前桢中存储的寄存器:rbp at 0x7fffffffe020, rip at 0x7fffffffe028。
10.4.6 gdb 调试递归函数
int fibonacci(int n)
{
if (n == 1 || n == 2) {
return 1;
}
return fibonacci(n - 1) + fibonacci(n - 2);
}
int main()
{
int n = 10;
int ret = 0;
ret = fibonacci(n);
printf("fibonacci(%d)=%d\n", n, ret);
return 0;
}
调试流程如下。
xiechen@xiechen-Ubuntu:~/2.测试中心/2.linux系统编程$ gcc -g -o test test.c
xiechen@xiechen-Ubuntu:~/2.测试中心/2.linux系统编程$ gdb test
GNU gdb (Ubuntu 8.1-0ubuntu3.2) 8.1.0.20180409-git
Copyright (C) 2018 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-linux-gnu".
Type "show configuration" for configuration details.
For bug reporting instructions, please see:
<http://www.gnu.org/software/gdb/bugs/>.
Find the GDB manual and other documentation resources online at:
<http://www.gnu.org/software/gdb/documentation/>.
For help, type "help".
Type "apropos word" to search for commands related to "word"...
Reading symbols from test...done.
(gdb) b f
fibonacci frame_dummy
(gdb) b fibonacci if n == 5
Breakpoint 1 at 0x656: file test.c, line 5.
(gdb) r
Starting program: /home/xiechen/2.测试中心/2.linux系统编程/test
Breakpoint 1, fibonacci (n=5) at test.c:5
5 if (n == 1 || n == 2) {
(gdb) bt
0 fibonacci (n=5) at test.c:5
1 0x0000555555554676 in fibonacci (n=6) at test.c:9
2 0x0000555555554676 in fibonacci (n=7) at test.c:9
3 0x0000555555554676 in fibonacci (n=8) at test.c:9
4 0x0000555555554676 in fibonacci (n=9) at test.c:9
5 0x0000555555554676 in fibonacci (n=10) at test.c:9
6 0x00005555555546ae in main () at test.c:17
10.5 strace 跟踪系统调用
一般用来跟踪任何程序的系统调用,比如Linux系统中自带的命令,或者是其他不开源的可执行文件,strace 都可以跟踪他们的系统调用。
10.5.1 基本概念
strace 命令是一个集诊断、调试、统计与一体的工具,我们用它来监控用户空间进程和内核的交互,比如对应用程序的系统调用、信号传递与进程状态变更等进行跟踪与分析,以达到解决问题或者是了解应用工作过程的目的。
可以清楚地看到这些系统调用的过程、使用的参数、返回值与执行消耗的 时间等,还可以了解它们与操作系统之间的底层交互。
10.5.2 输出的格式参数
- [-o file]:将strace的输出写入指定的文件。
- [-s strsize]:将打印字符串的长度限制为strsize个字符(默认值为32)。
- -d:输出strace关于标准错误的调试信息。
- -r:打印出相对时间关于每一个系统调用。
- -f:跟踪由fork()调用所产生的子进程。
- -t:在输出中的每一行前加上时间信息。
- -tt:在输出中的每一行前加上时间信息(微秒级)。
- -T:打印在每个系统调用中花费的时间。
- -r:打印相对时间戳。
- -x:以十六进制打印非ascii字符串。
- -xx:以十六进制打印所有字符串。
- -y:打印与文件描述符参数关联的路径。
- -yy:打印与套接字文件描述符关联的协议特定信息。
10.5.3 统计参数
- -c:统计每一系统调用的所执行的时间,次数和出错的次数等。
- -C:像-c一样,也可以打印常规输出。
- -w:汇总系统调用延迟(默认为系统时间)
- [-O overhead]:设置将系统调用跟踪到OVERUSE的开销
- [-S sortby]:按以下顺序对系统调用计数:时间,调用,名称等
10.5.4 过滤参数
[-e expr]…:指定一个表达式,用来控制如何跟踪。格式如下:
[qualifier=][!]value1[,value2]...
描述说明: qualifier 只能是 trace、abbrev、verbose、raw、signal、read、write 其中之一。
value是用来限定的符号或数字,默认的 qualifier是trace。
感叹号是否定符号,例如: -e open 等价于 -e trace=open ,表示只跟踪 open 调用。
而 -etrace!=open 表示跟踪除了open以外的其他调用,还有两个特殊的符号 all 和 none ,它们分别代表所有选项与没有选项。
10.5.5 过滤的例子
- -e trace=set 只跟踪指定的系统调用,例如: -e trace=open,close,rean,write 表示只跟踪这四个系统调用,默认的为 set=all 。
- -e trace=file 只跟踪有关文件操作的系统调用。
- -e trace=process 只跟踪有关进程控制的系统调用。
- -e trace=network 跟踪与网络有关的所有系统调用。
- -e strace=signal 跟踪所有与信号有关的系统调用。
- -e trace=ipc 跟踪所有与进程通讯有关的系统调用。
- -e raw=set 将指定的系统调用的参数以十六进制显示。
- -e signal=se t 指定跟踪的系统信号。默认为all(所有信号)。如 signal=!SIGIO 或者 signal=!io ,表示不跟踪 SIGIO 信号。
- -e read=set 输出从指定文件中读出的数据。
- -e write=set 输出写入到指定文件中的数据。
10.5.6 案例
strace ls # 跟踪 ls;
strace -c ls # 跟踪并统计 ls 命令;
10.5.7 重定向输出信息
strace命令在终端输出的信息太多了,我们想要将它重定向输出某个文件中(使用 [-o filename] 参数), 然后对文件进行分析,这样子的操作就比在终端上分析要好得多,但是需要注意的是,因为输出的信息很多, 生成的日志文件可能会很大,所以在日常使用中要注意设置过滤,不需要完全跟踪所有的内容。
strace -o ls.log ls
10.5.8 跟踪自己的代码
使用strace命令去跟踪它,看看遇到错误是怎么样的情况。
strace test
使用 -T 参数查看每个系统调用的时间(在输出的最右边 <> 的内容就是时间)。
strace -T test
strace -t -tt test