本文为机器学习的学习总结,讲解神经网络。欢迎交流
非线性假设
如果我们有一个分类问题,其训练集如下:
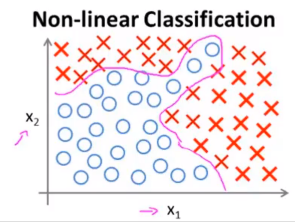
如果我们使用逻辑回归模型进行拟合,这样复杂的图形需要高阶多项式,而当特征变量数量增加时,其二次项会呈
O(n2) 的速度增长,即解空间会随着特征变量的增加而急剧膨胀。这样的模型很容易出现过拟合的问题,并且计算量极大。但如果选取的特征变量较少时,很难拟合出上图中复杂的决策边界。
例如下面的例子,我们构造一个识别汽车的分类器。为画图方便,取车上的 2 个像素点,画出训练集如下:

此时汽车与非汽车被分为两类:

假设图像是 50×50 像素,则特征空间的维数为 2500。如果要包含所有的二次项特征来学习得到的非线性假设,大约需要 300 万个特征。
因此,在
n 很大时,简单的逻辑回归模型不是学习复杂的非线性假设的好方法,因为特征过多。而神经网络被证明是学习复杂非线性假设的很好的算法,即使输入特征空间很大也能轻松解决。
神经元与大脑
神经网络算法是一种很古老的算法,但因为计算量过大,后来人们很少使用。随着计算机计算能力的突飞猛进,神经网络算法由出现在人们的视野中。
神经网络起源于人类用计算机对大脑的模拟。神经网络中神经元的连接方式称为神经网络的架构。
模型表示 I
我们使用一个很简单的模型来模拟神经元的工作,将神经元模拟成一个逻辑单元。

神经元的左边的输入通道传递一些信息,由神经元进行计算,并通过右边的输出通道输出计算到的结果。这里
hθ(x)=1+e−θTx1,其中
x,θ 分别为特征和参数的列向量。有时我们还会在输入层添加一个额外结点
x0,被称为偏置神经元。在神经网络中,激活函数代指非线性函数
g(z)=1+e−z1,参数
θ 被称为权重。
神经网络的计算步骤如下:
a1(2)=g(Θ10(1)x0+Θ11(1)x1+Θ12(1)x2+Θ13(1)x3)
a2(2)=g(Θ20(1)x0+Θ21(1)x1+Θ22(1)x2+Θ23(1)x3)
a3(2)=g(Θ30(1)x0+Θ31(1)x1+Θ32(1)x2+Θ33(1)x3)
hΘ(x)=a1(3)=g(Θ10(2)a0(2)+Θ11(2)a1(2)+Θ12(2)a2(2)+Θ13(2)a3(2))
我们用
ai(j) 表示第
j 层中第
i 个神经元的激活项,即输出值。
Θ(j) 为控制从第
j 层到第
j+1 层映射的参数矩阵,维度为
sj+1×sj,其中
sj 表示第
j 层的神经元个数。通过改变
Θ,我们得到不同的假设(函数)。
模型表示 II
我们需要高效计算,并展示一个向量化的实现方法,可以帮助我们学习复杂的非线性假设函数。
在神经网络的计算步骤中,我们将
g 函数括号内的部分定义为
z1(2),有
a1(2)=g(z1(2))。激活项的计算中,可以将其对应到矩阵乘法。设
x=⎣⎢⎢⎡x0x1x2x3⎦⎥⎥⎤,x0=1,
z(2)=⎣⎢⎡z1(2)z2(2)z3(2)⎦⎥⎤。激活项的计算可以参数化为:
z(2)=Θ(1)x
a(2)=g(z(2))
g 作用于
z(2) 中的每个元素。因为
x 为第一层的激活项,为符号统一,定义
x=a(1),则此时
z(2)=Θ(1)a(1)。再加上偏置神经元
a0(2)=1,则:
z(3)=Θ(2)a(2)
hΘ(x)=a(3)=g(z(3))
这种方式称为前向传播。
我们盖住左边的部分,最右边的部分是一个逻辑回归模型:

神经网络中,算法自己训练逻辑回归模型中的输入特征
a1,a2,a3,因此逻辑回归模型将得到更复杂的特征,从而实现更多的功能。
多元分类
数字识别是一个典型的神经网络用于多元分类问题的例子,我们再举一个例子来说明如何将神经网络运用到多元分类问题上。
有行人、汽车、摩托车、火车 4 类图片,我们需要将输入的图片进行分类。建立一个有 4 个输出单元的神经网络,则此时
hΘ(x)∈R4,输出变为了 4 维的向量。

我们用 4 个输出单元分别判断是否是行人、汽车、摩托车、火车。当为行人时,网络输出
hΘ(x)≈⎣⎢⎢⎡1000⎦⎥⎥⎤,其余同理。
在训练集中,
y(i) 用 4 维列向量表示 4 种不同的物体,
x(i) 为 4 种物体中的一种。因此训练集表示为
(x(1),y(1)),…,(x(m),y(m))。我们希望找到一个方法,让
hΘ(x)=y(i)。