啥是持久化?听着很高端,我觉得就是这样子的。Redis是存在内存的,关机容易丢失,所以就使用各种机制(如RDB、AOF)将redis的数据存放
在磁盘,数据这样就持久(就是能用很久),就实现了持久化

| RDB |
万物都从是什么开始,RDB自然也不例外,RDB就是在指定时间间隔内将内存中的数据集快照写入磁盘
Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。整个过程中,主进程是不进行任何IO操作的,这就确保了极高的性能。
fork可以理解为是拷贝,复制一个与当前进程一样的进程。
优势如下:
-
适合大规模的数据恢复
-
对数据完整性和一致性要求不高
劣势如下:
缺点应该很明显了,复制文件本身就是一个很消耗资源的事情,如果redis的数据量过大,那么就会给服务器很大的负担,double份的压力,想想就可怕。另外,在一定间隔时间做一次备份,所以如果redis意外down掉的话,就会丢失最后一次快照后的所有修改
如何使用
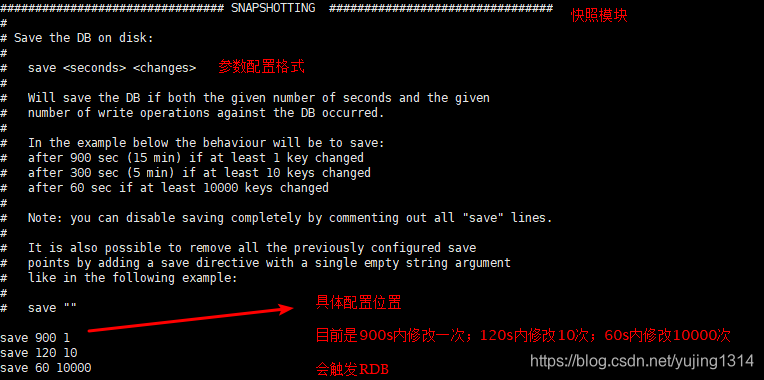
save 900 1 # 表示900 秒内如果至少有 1 个 key 的值变化,则触发RDB
save 300 10 # 表示300 秒内如果至少有 10 个 key 的值变化,则触发RDB
save 60 10000 # 表示60 秒内如果至少有 10000 个 key 的值变化,则触发RDB
如果不需要 Redis 进行持久化,那么可以注释掉所有的 save 行来停用保存功能,也可以直接一个空字符串来停用持久化:save “”。
此时来实验一下,120秒内修改10次,开始是没有dump.db文件的
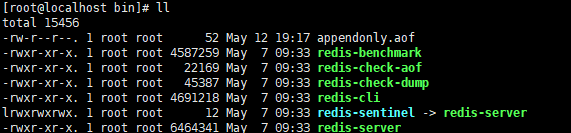
经过10次修改
127.0.0.1:6379> set k1 v1
OK
127.0.0.1:6379> set k2 v2
OK
127.0.0.1:6379> set k3 v3
OK
127.0.0.1:6379> set k4 v4
OK
127.0.0.1:6379> set k5 v5
OK
127.0.0.1:6379> set k6 v6
OK
127.0.0.1:6379> set k7 v7
OK
127.0.0.1:6379> set k8 v8
OK
127.0.0.1:6379> set k9 v9
OK
127.0.0.1:6379> set k10 v10
OK
如下图,快照dump.rdb已经就绪
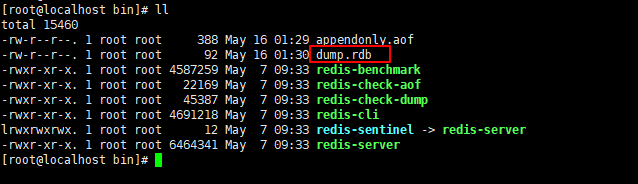
备份一份dump.rdb
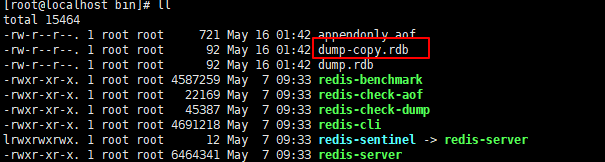
查看redis数据库中的数据
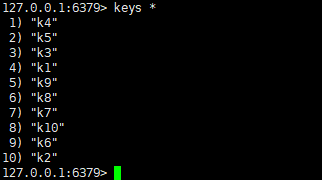
删除所有数据
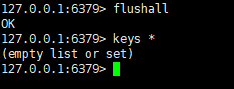
然后执行shutdown-exit命令关闭redis
重新启动之后,keys *并未恢复

这是因为,如下图,在redis清库之后,突然断掉redis,redis会快速保存一次快照,清库之后的快照在重启redis之后会被恢复过来


如果此时把备份的快照复制一份
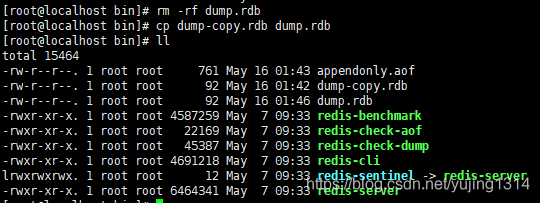
重启之后发现,keys * 并没有恢复,那是因为我还开启这aof,等我关闭aof之后,再次重复步骤 keys * 全部恢复了
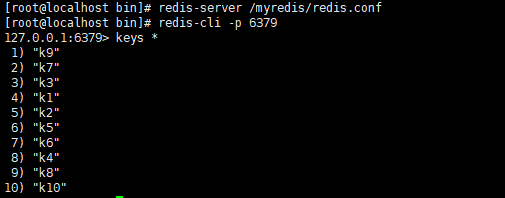
所以根据我的测试,我猜想aof的恢复快照是在rdb之后的,或者说aof是随时保存的,所以aof和rdb同时开启,那么最后恢复的是aof的快照
另外,也可以在运行的时候直接输入save命令,直接备份一次,或者输入bgsave异步备份。
RDB总结
- RDB是一个非常紧凑的文件
- RDB在保存RDB文件时父进程唯一需要做的就是fork出一个子进程,接下来的工作全部由子进程来做,父进程不需要再做其他IO操作,所以RDB持久化方式可以最大化redis的性能
- 与AOF相比RDB恢复大数据集更快
- 数据易丢失
- 耗时大
- RDB和AOF同时开启,默认无脑加载AOF的配置文件相同数据集,AOF文件要远大于RDB文件,恢复速度慢于RDB
AOF运行效率慢于RDB
| AOF |
AOF出现在RDB之后,根据我多年经验,必定弥补了之前机制的部分缺点,AOF以日志的形式来记录每个写操作,将Redis执行过的所有写指令记录下来(读操作不记录),只许追加文件但不可以改写文件,redis启动之初会读取该文件重新构建数据,换言之,redis重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作
优势如下:
每修改同步:appendfsync always 同步持久化 每次发生数据变更会被立即记录到磁盘 性能较差但数据完整性比较好
劣势如下:
- 相同数据集的数据而言aof文件要远大于rdb文件,恢复速度慢于rdb
- Aof运行效率要慢于rdb,每秒同步策略效率较好,不同步效率和rdb相同
如何使用
由于aof的功能和rdb看起来基本是一样的,就不再测试了
开启aof
修改redis.conf
appendfsync yes
关闭aof
config set appendfsync no
检查是否成功
config get appendfsync
或者直接修改redis.conf文件
appendfsync no
| 总结 |
持久化就是关机吧,我不怕!
区别
- 两种机制全部开启的时候,Redis在重启的时候会默认使用AOF去重新构建数据,因为AOF的数据是比RDB更完整的
- RDB:RDB 持久化机制,是对 Redis 中的数据执行周期性的持久化。
- AOF 机制对每条写入命令作为日志,以 append-only 的模式写入一个日志文件中,因为这个模式是只追加的方式,所以没有任何磁盘寻址的开销,所以很快,有点像Mysql中的binlog。
容灾
集群容灾:1.为每个master节点配置一个slave节点 2.使用不对称集群
异地容灾:
我杭州的某电商公司有这两个数据,我备份一份到我杭州的节点,再备份一个到上海的,就算发生无法避免的自然灾害,也不会两个地方都一起挂吧,这灾备也就是异地容灾,地球毁灭他没办法。
混合使用
你单独用RDB你会丢失很多数据,你单独用AOF,你数据恢复没RDB来的快,所以现在的持久化一般是RDB和AOF一起使用