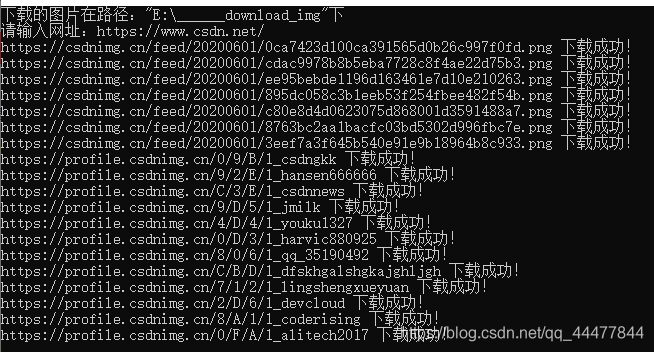
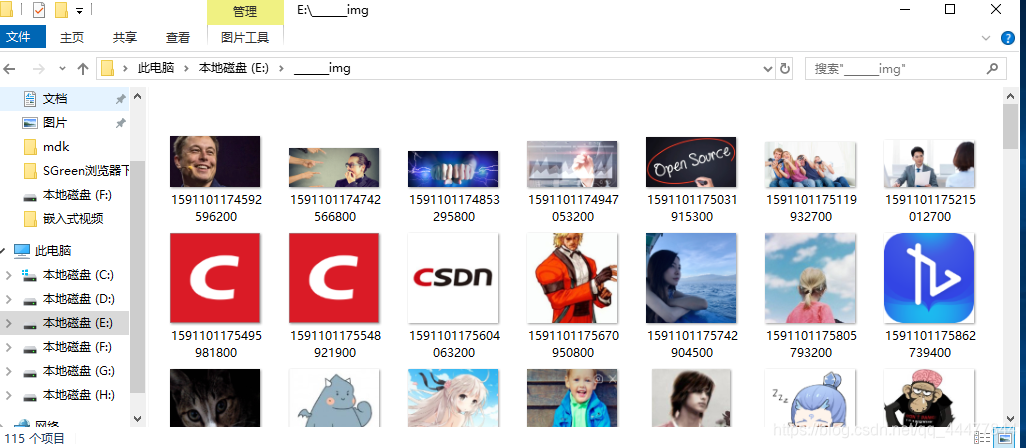
效果展示:

源代码:
package main
import (
"sync"
"os"
"strconv"
"time"
"regexp"
"io/ioutil"
"net/http"
"fmt"
)
var (
//用于阻塞主程序
waitgroup sync.WaitGroup
//开一个5个大小的管道(同步执行5个go)
dlchan = make(chan int,5)
)
//爬网页找图片(此函数不止爬图片)
func FindMatchString(htmlAddr string, regexp_exp string)[][]string{
//1.得到请求的回复(拿到网页的句柄)
resp, err := http.Get(htmlAddr)
if err != nil {
fmt.Println(err)
return nil
}
//2.resp.Body是输入输出流,开始读网页
html_byte, _:= ioutil.ReadAll(resp.Body)
defer resp.Body.Close()
html := string(html_byte)
//3.解析正则表达式
re := regexp.MustCompile(regexp_exp)
//4.match -1表示匹配无上限
res_slice := re.FindAllStringSubmatch(html, -1)
return res_slice
}
//异步下载
func Download(uil string)error{
current, err := http.Get(uil)
if err != nil{
return err
}
imgbytes, err := ioutil.ReadAll(current.Body)
if err != nil{
return err
}
//给文件命名,0644权限不知道。视频上老师给的0000011001000100
err = ioutil.WriteFile(`E:\\_______img\\`+strconv.Itoa(int(time.Now().UnixNano()))+".jpg",
imgbytes, 0644)
if err != nil{
return err
}
return nil
}
//同步下载
func DownloadAsync(uil string)error{
//计数器加一,下完后在done,-1
waitgroup.Add(1)
go func()error{
//信号量+1
dlchan<-1
err := Download(uil)
if err !=nil{
return err
}
<-dlchan
waitgroup.Done()
return nil
}()
//阻塞等待计数器为0
waitgroup.Wait()
return nil
}
//查看文件是否存在
func PathExists(path string) bool {
//err!=nil表示路径错误
_, err := os.Stat(path)
if err == nil {
return true
}
//该错误是否表示一个文件或目录不存在
if os.IsNotExist(err) {
return false
}
return false
}
func main(){
fmt.Println("下载的图片在路径:\"E:\\______download_img\"下")
pathTmp := "E:\\______download_img"
if !PathExists(pathTmp){
err := os.Mkdir(pathTmp,0777)
if err != nil {
fmt.Println(err)
return
}
}
var htmlAddr string
fmt.Print("请输入网址:")
fmt.Scanln(&htmlAddr)
//正则表达式
regexp_exp := `<img src="(http[\s\S]+?)"`
res_slice := FindMatchString(htmlAddr, regexp_exp)
for _,v :=range res_slice{
err := DownloadAsync(v[1])
if err == nil{
fmt.Println(v[1], "下载成功!")
}else{
fmt.Println(v[1], "下载失败!err :", err)
}
}
}
想写继续爬视频的,正在研究