如何再hadoop集群上跑我们自己写MapReduce程序
1.首先我们要将想要被执行的文件放到HDFS上去,例如我在hadoop102:9870 / 路径下创建了一个input文件下 放入我们需要被执行的文件 word.txt
- 将我们再 idea上写的wordcount打包,并且把这个包上传到 linux 上去,然后鼠标右击 driver类,选择copy reference
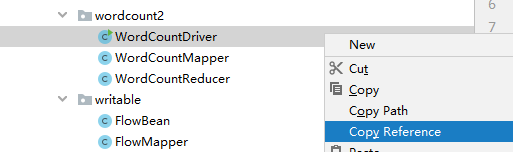
-
再linux 下找到导入了自己编写的 MapperReducer.jar 包
-
输入指令
hadoop jar MapperReducer-1.0-SNAPSHOT.jar wordcount2.WordCountDriver /input /output
wordcount2.WordCountDriver ------这一串就是我们之前得到的Copy-Refernece 粘贴即可 /input /output 是因为我们配置了默认 core-site.xml 文件中的路径,如图所示(快速获取路径)

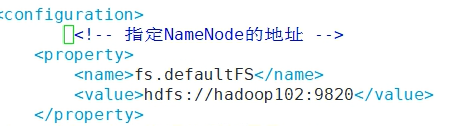
如果没有配置的话:就需要写成 hdfs://hadoop102:9820/input
hdfs://hadoop102:9820/output
hdfs://hadoop102:9820/output