本节将介绍循环神经网络中梯度的计算和存储方法,即 通过时间反向传播(back-propagation through time) 。
正向传播在循环神经网络中比较直观,而通过时间反向传播其实是反向传播在循环神经网络中的具体应用。我们需要将循环神经网络按时间步展开,从而得到模型变量和参数之间的依赖关系,并依据链式法则应用反向传播计算并存储梯度。
简单起见,我们考虑一个无偏差项的循环神经网络,且激活函数为恒等映射(
ϕ
(
x
)
=
x
\phi(x)=x
ϕ ( x ) = x
t
t
t
x
t
∈
R
d
\boldsymbol{x}_t \in \mathbb{R}^d
x t ∈ R d
y
t
y_t
y t
h
t
∈
R
h
\boldsymbol{h}_t \in \mathbb{R}^h
h t ∈ R h
h
t
=
W
h
x
x
t
+
W
h
h
h
t
−
1
,
\boldsymbol{h}_t = \boldsymbol{W}_{hx} \boldsymbol{x}_t + \boldsymbol{W}_{hh} \boldsymbol{h}_{t-1},
h t = W h x x t + W h h h t − 1 ,
其中
W
h
x
∈
R
h
×
d
\boldsymbol{W}_{hx} \in \mathbb{R}^{h \times d}
W h x ∈ R h × d
W
h
h
∈
R
h
×
h
\boldsymbol{W}_{hh} \in \mathbb{R}^{h \times h}
W h h ∈ R h × h
W
q
h
∈
R
q
×
h
\boldsymbol{W}_{qh} \in \mathbb{R}^{q \times h}
W q h ∈ R q × h
t
t
t
o
t
∈
R
q
\boldsymbol{o}_t \in \mathbb{R}^q
o t ∈ R q
o
t
=
W
q
h
h
t
.
\boldsymbol{o}_t = \boldsymbol{W}_{qh} \boldsymbol{h}_{t}.
o t = W q h h t .
设时间步
t
t
t
ℓ
(
o
t
,
y
t
)
\ell(\boldsymbol{o}_t, y_t)
ℓ ( o t , y t )
T
T
T
L
L
L
L
=
1
T
∑
t
=
1
T
ℓ
(
o
t
,
y
t
)
.
L = \frac{1}{T} \sum_{t=1}^T \ell (\boldsymbol{o}_t, y_t).
L = T 1 t = 1 ∑ T ℓ ( o t , y t ) .
我们将
L
L
L
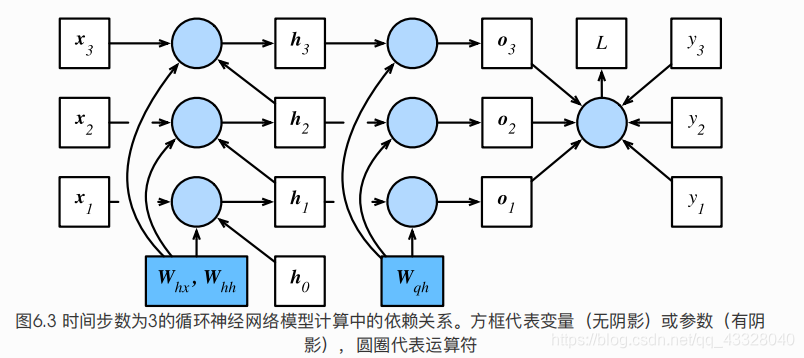
为了可视化循环神经网络中模型变量和参数在计算中的依赖关系,我们可以绘制模型计算图,如图6.3所示。例如,时间步3的隐藏状态
h
3
\boldsymbol{h}_3
h 3
W
h
x
\boldsymbol{W}_{hx}
W h x
W
h
h
\boldsymbol{W}_{hh}
W h h
h
2
\boldsymbol{h}_2
h 2
x
3
\boldsymbol{x}_3
x 3
刚刚提到,图6.3中的模型的参数是
W
h
x
\boldsymbol{W}_{hx}
W h x
W
h
h
\boldsymbol{W}_{hh}
W h h
W
q
h
\boldsymbol{W}_{qh}
W q h
∂
L
/
∂
W
h
x
\partial L/\partial \boldsymbol{W}_{hx}
∂ L / ∂ W h x
∂
L
/
∂
W
h
h
\partial L/\partial \boldsymbol{W}_{hh}
∂ L / ∂ W h h
∂
L
/
∂
W
q
h
\partial L/\partial \boldsymbol{W}_{qh}
∂ L / ∂ W q h
首先,目标函数有关各时间步输出层变量的梯度
∂
L
/
∂
o
t
∈
R
q
\partial L/\partial \boldsymbol{o}_t \in \mathbb{R}^q
∂ L / ∂ o t ∈ R q
∂
L
∂
o
t
=
∂
ℓ
(
o
t
,
y
t
)
T
⋅
∂
o
t
.
\frac{\partial L}{\partial \boldsymbol{o}_t} = \frac{\partial \ell (\boldsymbol{o}_t, y_t)}{T \cdot \partial \boldsymbol{o}_t}.
∂ o t ∂ L = T ⋅ ∂ o t ∂ ℓ ( o t , y t ) .
下面,我们可以计算目标函数有关模型参数
W
q
h
\boldsymbol{W}_{qh}
W q h
∂
L
/
∂
W
q
h
∈
R
q
×
h
\partial L/\partial \boldsymbol{W}_{qh} \in \mathbb{R}^{q \times h}
∂ L / ∂ W q h ∈ R q × h
L
L
L
o
1
,
…
,
o
T
\boldsymbol{o}_1, \ldots, \boldsymbol{o}_T
o 1 , … , o T
W
q
h
\boldsymbol{W}_{qh}
W q h
∂
L
∂
W
q
h
=
∑
t
=
1
T
prod
(
∂
L
∂
o
t
,
∂
o
t
∂
W
q
h
)
=
∑
t
=
1
T
∂
L
∂
o
t
h
t
⊤
.
\frac{\partial L}{\partial \boldsymbol{W}_{qh}} = \sum_{t=1}^T \text{prod}\left(\frac{\partial L}{\partial \boldsymbol{o}_t}, \frac{\partial \boldsymbol{o}_t}{\partial \boldsymbol{W}_{qh}}\right) = \sum_{t=1}^T \frac{\partial L}{\partial \boldsymbol{o}_t} \boldsymbol{h}_t^\top.
∂ W q h ∂ L = t = 1 ∑ T prod ( ∂ o t ∂ L , ∂ W q h ∂ o t ) = t = 1 ∑ T ∂ o t ∂ L h t ⊤ .
其次,我们注意到隐藏状态之间也存在依赖关系。
L
L
L
o
T
\boldsymbol{o}_T
o T
T
T
T
h
T
\boldsymbol{h}_T
h T
∂
L
/
∂
h
T
∈
R
h
\partial L/\partial \boldsymbol{h}_T \in \mathbb{R}^h
∂ L / ∂ h T ∈ R h
∂
L
∂
h
T
=
prod
(
∂
L
∂
o
T
,
∂
o
T
∂
h
T
)
=
W
q
h
⊤
∂
L
∂
o
T
.
\frac{\partial L}{\partial \boldsymbol{h}_T} = \text{prod}\left(\frac{\partial L}{\partial \boldsymbol{o}_T}, \frac{\partial \boldsymbol{o}_T}{\partial \boldsymbol{h}_T} \right) = \boldsymbol{W}_{qh}^\top \frac{\partial L}{\partial \boldsymbol{o}_T}.
∂ h T ∂ L = prod ( ∂ o T ∂ L , ∂ h T ∂ o T ) = W q h ⊤ ∂ o T ∂ L .
接下来对于时间步
t
<
T
t < T
t < T
L
L
L
h
t
+
1
\boldsymbol{h}_{t+1}
h t + 1
o
t
\boldsymbol{o}_t
o t
h
t
\boldsymbol{h}_t
h t
t
<
T
t < T
t < T
∂
L
/
∂
h
t
∈
R
h
\partial L/\partial \boldsymbol{h}_t \in \mathbb{R}^h
∂ L / ∂ h t ∈ R h
∂
L
∂
h
t
=
prod
(
∂
L
∂
h
t
+
1
,
∂
h
t
+
1
∂
h
t
)
+
prod
(
∂
L
∂
o
t
,
∂
o
t
∂
h
t
)
=
W
h
h
⊤
∂
L
∂
h
t
+
1
+
W
q
h
⊤
∂
L
∂
o
t
\frac{\partial L}{\partial \boldsymbol{h}_t} = \text{prod} (\frac{\partial L}{\partial \boldsymbol{h}_{t+1}}, \frac{\partial \boldsymbol{h}_{t+1}}{\partial \boldsymbol{h}_t}) + \text{prod} (\frac{\partial L}{\partial \boldsymbol{o}_t}, \frac{\partial \boldsymbol{o}_t}{\partial \boldsymbol{h}_t} ) = \boldsymbol{W}_{hh}^\top \frac{\partial L}{\partial \boldsymbol{h}_{t+1}} + \boldsymbol{W}_{qh}^\top \frac{\partial L}{\partial \boldsymbol{o}_t}
∂ h t ∂ L = prod ( ∂ h t + 1 ∂ L , ∂ h t ∂ h t + 1 ) + prod ( ∂ o t ∂ L , ∂ h t ∂ o t ) = W h h ⊤ ∂ h t + 1 ∂ L + W q h ⊤ ∂ o t ∂ L
将上面的递归公式展开,对任意时间步
1
≤
t
≤
T
1 \leq t \leq T
1 ≤ t ≤ T
∂
L
∂
h
t
=
∑
i
=
t
T
(
W
h
h
⊤
)
T
−
i
W
q
h
⊤
∂
L
∂
o
T
+
t
−
i
.
\frac{\partial L}{\partial \boldsymbol{h}_t} = \sum_{i=t}^T {\left(\boldsymbol{W}_{hh}^\top\right)}^{T-i} \boldsymbol{W}_{qh}^\top \frac{\partial L}{\partial \boldsymbol{o}_{T+t-i}}.
∂ h t ∂ L = i = t ∑ T ( W h h ⊤ ) T − i W q h ⊤ ∂ o T + t − i ∂ L .
由上式中的指数项可见,当时间步数
T
T
T
t
t
t 衰减 和 爆炸 。这也会影响其他包含
∂
L
/
∂
h
t
\partial L / \partial \boldsymbol{h}_t
∂ L / ∂ h t
∂
L
/
∂
W
h
x
∈
R
h
×
d
\partial L / \partial \boldsymbol{W}_{hx} \in \mathbb{R}^{h \times d}
∂ L / ∂ W h x ∈ R h × d
∂
L
/
∂
W
h
h
∈
R
h
×
h
\partial L / \partial \boldsymbol{W}_{hh} \in \mathbb{R}^{h \times h}
∂ L / ∂ W h h ∈ R h × h
L
L
L
h
1
,
…
,
h
T
\boldsymbol{h}_1, \ldots, \boldsymbol{h}_T
h 1 , … , h T
∂
L
∂
W
h
x
=
∑
t
=
1
T
prod
(
∂
L
∂
h
t
,
∂
h
t
∂
W
h
x
)
=
∑
t
=
1
T
∂
L
∂
h
t
x
t
⊤
,
∂
L
∂
W
h
h
=
∑
t
=
1
T
prod
(
∂
L
∂
h
t
,
∂
h
t
∂
W
h
h
)
=
∑
t
=
1
T
∂
L
∂
h
t
h
t
−
1
⊤
.
\begin{aligned} \frac{\partial L}{\partial \boldsymbol{W}_{hx}} &= \sum_{t=1}^T \text{prod}\left(\frac{\partial L}{\partial \boldsymbol{h}_t}, \frac{\partial \boldsymbol{h}_t}{\partial \boldsymbol{W}_{hx}}\right) = \sum_{t=1}^T \frac{\partial L}{\partial \boldsymbol{h}_t} \boldsymbol{x}_t^\top,\\ \frac{\partial L}{\partial \boldsymbol{W}_{hh}} &= \sum_{t=1}^T \text{prod}\left(\frac{\partial L}{\partial \boldsymbol{h}_t}, \frac{\partial \boldsymbol{h}_t}{\partial \boldsymbol{W}_{hh}}\right) = \sum_{t=1}^T \frac{\partial L}{\partial \boldsymbol{h}_t} \boldsymbol{h}_{t-1}^\top. \end{aligned}
∂ W h x ∂ L ∂ W h h ∂ L = t = 1 ∑ T prod ( ∂ h t ∂ L , ∂ W h x ∂ h t ) = t = 1 ∑ T ∂ h t ∂ L x t ⊤ , = t = 1 ∑ T prod ( ∂ h t ∂ L , ∂ W h h ∂ h t ) = t = 1 ∑ T ∂ h t ∂ L h t − 1 ⊤ .
每次迭代中,我们在依次计算完以上各个梯度后,会将它们存储起来,从而避免重复计算。例如,由于隐藏状态梯度
∂
L
/
∂
h
t
\partial L/\partial \boldsymbol{h}_t
∂ L / ∂ h t
∂
L
/
∂
W
h
x
\partial L/\partial \boldsymbol{W}_{hx}
∂ L / ∂ W h x
∂
L
/
∂
W
h
h
\partial L/\partial \boldsymbol{W}_{hh}
∂ L / ∂ W h h
∂
L
/
∂
h
t
\partial L/\partial \boldsymbol{h}_t
∂ L / ∂ h t
∂
L
/
∂
W
h
h
\partial L/\partial \boldsymbol{W}_{hh}
∂ L / ∂ W h h
t
=
0
,
…
,
T
−
1
t = 0, \ldots, T-1
t = 0 , … , T − 1
h
t
\boldsymbol{h}_t
h t
h
0
\boldsymbol{h}_0
h 0
通过时间反向传播是反向传播在循环神经网络中的具体应用。
当总的时间步数较大或者当前时间步较小时,循环神经网络的梯度较容易出现衰减或爆炸。