分析请求
Chrome浏览器点击我的微博首页之后,右键检查→手机模式→刷新之后url变成
https://m.weibo.cn/p...→network→XHR筛选
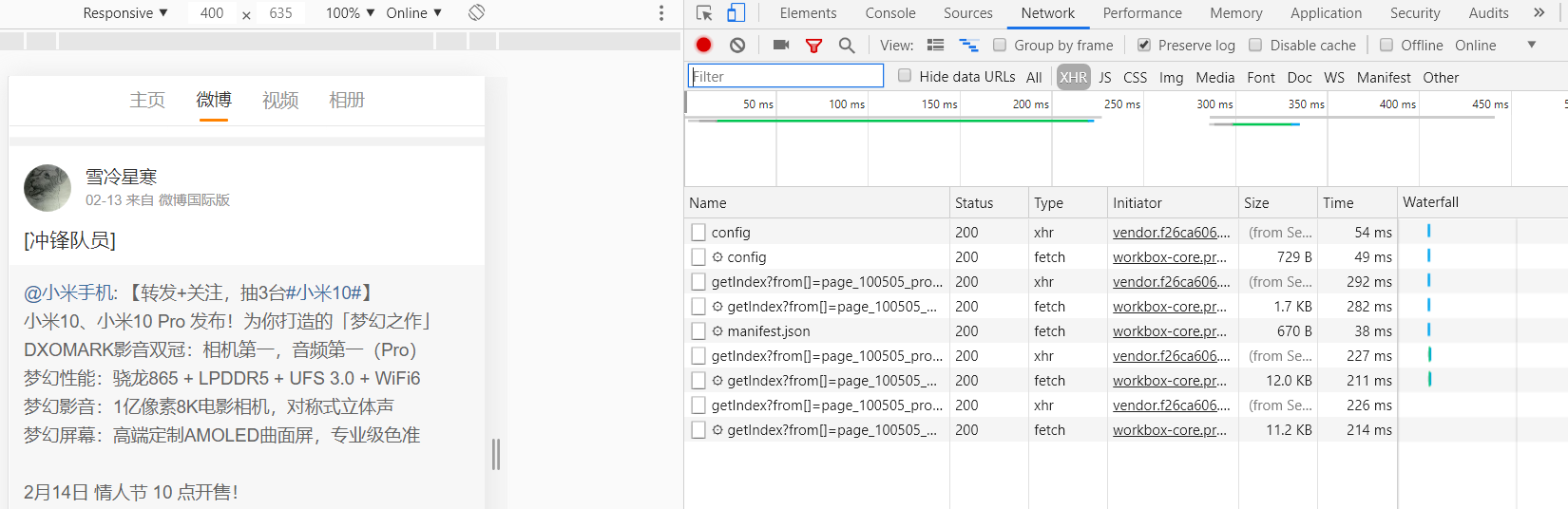
依次对不同类型的内容进行预览
- 以home开头的请求:空白框架,无实质内容
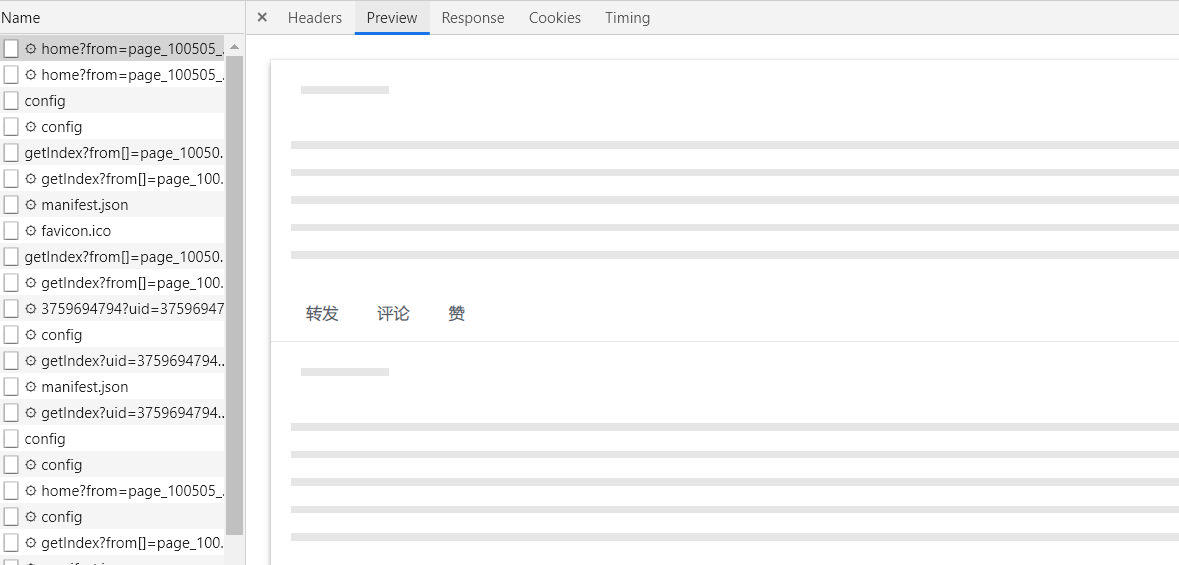
- 以config开头的请求:用于校验
- 以getIndex开头的请求:
- 如果请求的url中containerid=100505+id,则内容是网页设置

- 如果请求的url中containerid=107603+id,则内容是微博内容
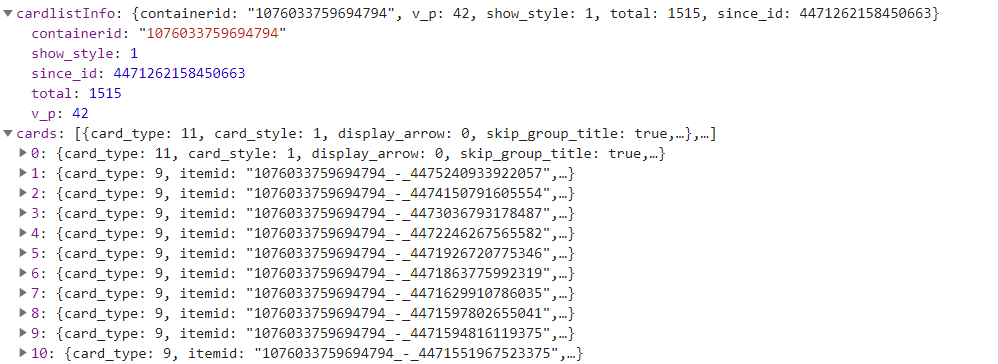
- 后一个url中since_id的内容来源于上一次请求返回的内容

- 如果请求的url中containerid=100505+id,则内容是网页设置
请求一页的函数
import requests
uid = "3759694794"
headers = {
'Accept': 'application/json, text/plain, */*',
'MWeibo-Pwa': '1',
'Referer':
'https://m.weibo.cn/p/100505'+uid+'/home?from=page_100505_profile&from=page_100505_profile&wvr=6&wvr=6&mod=data&mod=data&is_all=1&is_all=1&jumpfrom=weibocom',
'User-Agent':
'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Mobile Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'X-XSRF-TOKEN': '3ef4df'
}
baseurl = "https://m.weibo.cn/api/container/getIndex?from[]=page_100505_profile&from[]=page_100505_profile&wvr[]=6&wvr[]=6&mod[]=data&mod[]=data&is_all[]=1&is_all[]=1&jumpfrom=weibocom&containerid=107603"
def get_onepage(url):
try:
response = requests.get(url, headers)
if response.status_code == 200:
return response.json()
except requests.ConnectionError as e:
print('Error:', e.args)
testjson = get_onepage(baseurl+uid)
解析json
## 获取sinceid
testjson['data']['cardlistInfo']['since_id']
4471262158450663
## 获取微博总数
testjson['data']['cardlistInfo']['total']
1515
## 获取微博
import re
for m in testjson['data']['cards']:
if m['card_type'] == 9:
print('创建时间:', m['mblog']['created_at'])
if m['mblog'].get('raw_text') == None:
print('原创内容:', re.sub('<s.*>', '', m['mblog']['text']))
else:
print('转载内容:', m['mblog']['raw_text'])
创建时间: 昨天 21:20
转载内容: 哈哈哈//@马伯庸 :给你看这件事的后续,这兄弟俩的互动实在太……狗了 http://t.cn/A6hrdI0a //@幻想狂劉先生 :段子感也太强了
创建时间: 02-20
转载内容: //@大侦探家福尔摩斯 :此案无反馈!
创建时间: 02-17
转载内容: 我也想当助理//@著名网黄猫日 :我的工作之路真的很艰辛
创建时间: 02-15
转载内容: 转发微博
创建时间: 02-14
原创内容: 王者荣耀搞到改名卡啦,现在我叫鹤立鳖群
创建时间: 02-13
转载内容: [并不简单]
创建时间: 02-13
转载内容: //@折翼丛林 :可怜的北红尾鸲……可以用风油精去胶(千万别硬撕),接着用洗洁精去风油精,再用温水去洗洁精,最后用吹风机吹干。用个大纸箱装起来让它休息一下,注意保暖,喂点水,等体力恢复后就放飞(不要抛扔,放在树枝上就可以了)
创建时间: 02-13
转载内容: 转发微博
创建时间: 02-13
转载内容: [冲锋队员]
整合函数
import pandas as pd
def get_weibo(uid, number):
headers = {
'Accept': 'application/json, text/plain, */*',
'MWeibo-Pwa': '1',
'Referer': 'https://m.weibo.cn/p/100505' + uid +
'/home?from=page_100505_profile&from=page_100505_profile&wvr=6&wvr=6&mod=data&mod=data&is_all=1&is_all=1&jumpfrom=weibocom',
'User-Agent':
'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Mobile Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'X-XSRF-TOKEN': '3ef4df'
}
baseurl = "https://m.weibo.cn/api/container/getIndex?from[]=page_100505_profile&from[]=page_100505_profile&wvr[]=6&wvr[]=6&mod[]=data&mod[]=data&is_all[]=1&is_all[]=1&jumpfrom=weibocom&containerid=107603"+uid
info = get_onepage(baseurl)
tnumber = info['data']['cardlistInfo']['total']
# 确保要爬取的微博数小于等于微博总数
if tnumber < number:
number = tnumber
timelist = []
contentlist = []
baseurl = baseurl + "&since_id="
while len(timelist) < number:
for m in info['data']['cards']:
if m['card_type'] == 9:
timelist.append(m['mblog']['created_at'])
if m['mblog'].get('raw_text') == None:
contentlist.append('原创内容:' + re.sub('<.*>', '', m['mblog']['text']))
else:
contentlist.append('转载内容:' + m['mblog']['raw_text'])
if info['data']['cardlistInfo'].get('since_id') == None:
break
since_id = info['data']['cardlistInfo']['since_id']
info = get_onepage(baseurl+str(since_id))
output = pd.DataFrame( data={"时间":timelist, "内容":contentlist})
# 解决中文乱码
output.to_csv( uid+".csv", encoding="utf_8_sig")
get_weibo("3759694794", 30)
