import pandas as pd
import os
import shutil
import random
!cd train & & ls - l | grep "^-" | wc - l
220025
Train_label = pd. read_csv( 'train_labels.csv' )
name_0 = list ( Train_label[ Train_label[ 'label' ] == 0 ] [ 'id' ] )
name_0 = [ '0' + name + '.tif' for name in name_0]
len ( name_0)
130908
name_1 = list ( Train_label[ Train_label[ 'label' ] == 1 ] [ 'id' ] )
name_1 = [ '1' + name + '.tif' for name in name_1]
len ( name_1)
89117
for i in range ( len ( name_0) ) :
if i/ len ( name_0) < 0.1 :
shutil. move( './train/' + name_0[ i] , './test/0' )
else :
shutil. move( './train/' + name_0[ i] , './train/0' )
for i in range ( len ( name_1) ) :
if i/ len ( name_1) < 0.1 :
shutil. move( './train/' + name_1[ i] , './test/1' )
else :
shutil. move( './train/' + name_1[ i] , './train/1' )
!cd train/ 1 & & ls - l | grep "^-" | wc - l
82593
!cd train/ 0 & & ls - l | grep "^-" | wc - l
116929
!cd test/ 0 & & ls - l | grep "^-" | wc - l
13979
!cd test/ 1 & & ls - l | grep "^-" | wc - l
6524
% % time
def train ( model, train_loader, loss_func, optimizer, device) :
total_loss = 0
for i, ( images, targets) in enumerate ( train_loader) :
images = images. to( device)
targets = targets. to( device)
outputs = model( images)
loss = loss_func( outputs, targets)
optimizer. zero_grad( )
loss. backward( )
optimizer. step( )
total_loss += loss. item( )
if ( i + 1 ) % 100 == 0 :
print ( "Step [{}/{}] Train Loss: {:.4f}"
. format ( i+ 1 , len ( train_loader) , loss. item( ) ) )
return total_loss / len ( train_loader)
CPU times: user 8 µs, sys: 1 µs, total: 9 µs
Wall time: 14.8 µs
def evaluate ( model, val_loader, train_loader, device) :
"""
model: CNN networks
val_loader: a Dataloader object with validation data
device: evaluate on cpu or gpu device
return classification accuracy of the model on val dataset
"""
model. eval ( )
with torch. no_grad( ) :
correct = 0
total = 0
for i, ( images, targets) in enumerate ( train_loader) :
images = images. to( device)
targets = targets. to( device)
outputs = model( images)
_, predicted = torch. max ( outputs. data, dim= 1 )
correct += ( predicted == targets) . sum ( ) . item( )
total += targets. size( 0 )
accuracy = correct / total
print ( 'Accuracy on Train Set: {:.4f} %' . format ( 100 * accuracy) )
correct = 0
total = 0
for i, ( images, targets) in enumerate ( val_loader) :
images = images. to( device)
targets = targets. to( device)
outputs = model( images)
_, predicted = torch. max ( outputs. data, dim= 1 )
correct += ( predicted == targets) . sum ( ) . item( )
total += targets. size( 0 )
accuracy = correct / total
print ( 'Accuracy on Test Set: {:.4f} %' . format ( 100 * accuracy) )
return accuracy
import matplotlib. pyplot as plt
def show_curve ( ys, title) :
x = np. array( range ( len ( ys) ) )
y = np. array( ys)
plt. plot( x, y, c= 'b' )
plt. axis( )
plt. title( '{} curve' . format ( title) )
plt. xlabel( 'epoch' )
plt. ylabel( '{}' . format ( title) )
plt. show( )
def show_double_curve ( y1, y2, title, ylabel, label1, label2, locc = 'upper right' ) :
x = np. array( range ( len ( y1) ) )
y1 = np. array( y1)
y2 = np. array( y2)
plt. plot( x, y1, c= 'b' , label = label1)
plt. plot( x, y2, c= 'r' , label = label2)
plt. axis( )
plt. title( '{} curve' . format ( title) )
plt. xlabel( 'epoch' )
plt. ylabel( '{}' . format ( ylabel) )
plt. legend( bbox_to_anchor= ( 1.0 , 1 ) , borderaxespad= 0 , loc = locc)
plt. show( )
def show_multiple_curve ( ys, title, ylabel, labels, locc = 'upper right' ) :
x = np. array( range ( len ( ys[ 0 ] ) ) )
for i in range ( len ( ys) ) :
plt. plot( x, np. array( ys[ i] ) , label = labels[ i] )
plt. axis( )
plt. title( '{} curve' . format ( title) )
plt. xlabel( 'epoch' )
plt. ylabel( '{}' . format ( ylabel) )
plt. legend( bbox_to_anchor= ( 1.0 , 1 ) , borderaxespad= 0 , loc = locc)
plt. show( )
import torch
import torch. nn as nn
import torchvision
import torchvision. transforms as transforms
import numpy as np
train_transform = transforms. Compose( [
transforms. RandomHorizontalFlip( 0.6 ) ,
transforms. RandomVerticalFlip( 0.3 ) ,
transforms. Pad( 4 ) ,
transforms. RandomCrop( 96 ) ,
transforms. ToTensor( ) ,
transforms. Normalize( mean = ( 0.70541453 , 0.55419785 , 0.69922107 ) , std = ( 0.24204749 , 0.28683773 , 0.21985182 ) )
] )
test_transform = transforms. Compose( [
transforms. ToTensor( ) ,
transforms. Normalize( mean = ( 0.70541453 , 0.55419785 , 0.69922107 ) , std = ( 0.24204749 , 0.28683773 , 0.21985182 ) )
] )
train_dataset = torchvision. datasets. ImageFolder( root= './train' , transform= train_transform)
test_dataset = torchvision. datasets. ImageFolder( root= './test' , transform= test_transform)
train_loader = torch. utils. data. DataLoader( dataset= train_dataset,
batch_size= 100 ,
shuffle= True )
test_loader = torch. utils. data. DataLoader( dataset= test_dataset,
batch_size= 100 ,
shuffle= False )
def get_mean_std ( dataset) :
"""Get mean and std by sample ratio
"""
dataloader = torch. utils. data. DataLoader( dataset, batch_size= int ( len ( dataset) ) ,
shuffle= True )
train = iter ( dataloader) . next ( ) [ 0 ]
mean = np. mean( train. numpy( ) , axis= ( 0 , 2 , 3 ) )
std = np. std( train. numpy( ) , axis= ( 0 , 2 , 3 ) )
return mean, std
train_mean, train_std = get_mean_std( train_dataset)
test_mean, test_std = get_mean_std( test_dataset)
print ( train_mean, train_std)
print ( test_mean, test_std)
[ 0.70215523 0.54543036 0.69617653] [ 0.238572 0.28159615 0.21588241]
[ 0.70541453 0.55419785 0.69922107] [ 0.24204749 0.28683773 0.21985182]
def fit ( model, num_epochs, optimizer, device) :
loss_func = nn. CrossEntropyLoss( )
model. to( device)
loss_func. to( device)
losses = [ ]
accs = [ ]
for epoch in range ( num_epochs) :
print ( 'Epoch {}/{}:' . format ( epoch + 1 , num_epochs) )
loss = train( model, train_loader, loss_func, optimizer, device)
losses. append( loss)
accuracy = evaluate( model, test_loader, train_loader, device)
accs. append( accuracy)
if epoch% 10 == 0 :
for param_group in optimizer. param_groups:
param_group[ 'lr' ] = param_group[ 'lr' ] * 0.6
save_path = './vgg' + str ( epoch) + '.pt'
torch. save( model. state_dict( ) , save_path)
show_curve( losses, "train loss" )
show_curve( accs, "test accuracy" )
return losses, accs
import math
import torch
import torch. nn as nn
import torch. utils. data as Data
import torchvision
class VGG ( nn. Module) :
def __init__ ( self, cfg) :
super ( VGG, self) . __init__( )
self. features = self. _make_layers( cfg)
self. fc = nn. Linear( 512 , 2 )
def forward ( self, x) :
out = self. features( x)
out = out. view( out. size( 0 ) , - 1 )
out = self. fc( out)
return out
def _make_layers ( self, cfg) :
"""
cfg: a list define layers this layer contains
'M': MaxPool, number: Conv2d(out_channels=number) -> BN -> ReLU
"""
layers = [ ]
in_channels = 3
for x in cfg:
if x == 'M' :
layers += [ nn. MaxPool2d( kernel_size= 2 , stride= 2 ) ]
elif x == 'MM' :
layers += [ nn. MaxPool2d( kernel_size= 3 , stride= 3 ) ]
elif x == 'D' :
layers += [ nn. Dropout( p= 0.1 ) ]
else :
layers += [ nn. Conv2d( in_channels, x, kernel_size= 3 , padding= 1 ) ,
nn. BatchNorm2d( x) ,
nn. ReLU( inplace= True ) ]
in_channels = x
layers += [ nn. AvgPool2d( kernel_size= 1 , stride= 1 ) ]
return nn. Sequential( * layers)
vggnet = VGG( [ 64 , 'M' , 128 , 'M' , 128 , 256 , 'M' , 256 , 512 , 'MM' , 512 , 512 , 'M' , 512 , 'M' ] )
print ( vggnet)
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(5): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(6): ReLU(inplace)
(7): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(8): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(9): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(10): ReLU(inplace)
(11): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(12): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(13): ReLU(inplace)
(14): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(15): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(16): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(17): ReLU(inplace)
(18): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(19): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(20): ReLU(inplace)
(21): MaxPool2d(kernel_size=3, stride=3, padding=0, dilation=1, ceil_mode=False)
(22): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(23): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(24): ReLU(inplace)
(25): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(26): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(27): ReLU(inplace)
(28): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(29): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(30): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(31): ReLU(inplace)
(32): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(33): AvgPool2d(kernel_size=1, stride=1, padding=0)
)
(fc): Linear(in_features=512, out_features=2, bias=True)
)
from torchsummaryX import summary
import torch
summary( vggnet, torch. zeros( ( 128 , 3 , 96 , 96 ) ) )
===========================================================================================
Kernel Shape Output Shape Params (K) \
Layer
0_features.Conv2d_0 [3, 64, 3, 3] [128, 64, 96, 96] 1.792
1_features.BatchNorm2d_1 [64] [128, 64, 96, 96] 0.128
2_features.ReLU_2 - [128, 64, 96, 96] -
3_features.MaxPool2d_3 - [128, 64, 48, 48] -
4_features.Conv2d_4 [64, 128, 3, 3] [128, 128, 48, 48] 73.856
5_features.BatchNorm2d_5 [128] [128, 128, 48, 48] 0.256
6_features.ReLU_6 - [128, 128, 48, 48] -
7_features.MaxPool2d_7 - [128, 128, 24, 24] -
8_features.Conv2d_8 [128, 128, 3, 3] [128, 128, 24, 24] 147.584
9_features.BatchNorm2d_9 [128] [128, 128, 24, 24] 0.256
10_features.ReLU_10 - [128, 128, 24, 24] -
11_features.Conv2d_11 [128, 256, 3, 3] [128, 256, 24, 24] 295.168
12_features.BatchNorm2d_12 [256] [128, 256, 24, 24] 0.512
13_features.ReLU_13 - [128, 256, 24, 24] -
14_features.MaxPool2d_14 - [128, 256, 12, 12] -
15_features.Conv2d_15 [256, 256, 3, 3] [128, 256, 12, 12] 590.08
16_features.BatchNorm2d_16 [256] [128, 256, 12, 12] 0.512
17_features.ReLU_17 - [128, 256, 12, 12] -
18_features.Conv2d_18 [256, 512, 3, 3] [128, 512, 12, 12] 1180.16
19_features.BatchNorm2d_19 [512] [128, 512, 12, 12] 1.024
20_features.ReLU_20 - [128, 512, 12, 12] -
21_features.MaxPool2d_21 - [128, 512, 4, 4] -
22_features.Conv2d_22 [512, 512, 3, 3] [128, 512, 4, 4] 2359.81
23_features.BatchNorm2d_23 [512] [128, 512, 4, 4] 1.024
24_features.ReLU_24 - [128, 512, 4, 4] -
25_features.Conv2d_25 [512, 512, 3, 3] [128, 512, 4, 4] 2359.81
26_features.BatchNorm2d_26 [512] [128, 512, 4, 4] 1.024
27_features.ReLU_27 - [128, 512, 4, 4] -
28_features.MaxPool2d_28 - [128, 512, 2, 2] -
29_features.Conv2d_29 [512, 512, 3, 3] [128, 512, 2, 2] 2359.81
30_features.BatchNorm2d_30 [512] [128, 512, 2, 2] 1.024
31_features.ReLU_31 - [128, 512, 2, 2] -
32_features.MaxPool2d_32 - [128, 512, 1, 1] -
33_features.AvgPool2d_33 - [128, 512, 1, 1] -
34_fc [512, 2] [128, 2] 1.026
Mult-Adds (M)
Layer
0_features.Conv2d_0 15.9252
1_features.BatchNorm2d_1 6.4e-05
2_features.ReLU_2 -
3_features.MaxPool2d_3 -
4_features.Conv2d_4 169.869
5_features.BatchNorm2d_5 0.000128
6_features.ReLU_6 -
7_features.MaxPool2d_7 -
8_features.Conv2d_8 84.9347
9_features.BatchNorm2d_9 0.000128
10_features.ReLU_10 -
11_features.Conv2d_11 169.869
12_features.BatchNorm2d_12 0.000256
13_features.ReLU_13 -
14_features.MaxPool2d_14 -
15_features.Conv2d_15 84.9347
16_features.BatchNorm2d_16 0.000256
17_features.ReLU_17 -
18_features.Conv2d_18 169.869
19_features.BatchNorm2d_19 0.000512
20_features.ReLU_20 -
21_features.MaxPool2d_21 -
22_features.Conv2d_22 37.7487
23_features.BatchNorm2d_23 0.000512
24_features.ReLU_24 -
25_features.Conv2d_25 37.7487
26_features.BatchNorm2d_26 0.000512
27_features.ReLU_27 -
28_features.MaxPool2d_28 -
29_features.Conv2d_29 9.43718
30_features.BatchNorm2d_30 0.000512
31_features.ReLU_31 -
32_features.MaxPool2d_32 -
33_features.AvgPool2d_33 -
34_fc 0.001024
-------------------------------------------------------------------------------------------
Params (K): 9374.85
Mult-Adds (M): 780.3410559999999
===========================================================================================
Kernel Shape
Output Shape
Params (K)
Mult-Adds (M)
Layer
0_features.Conv2d_0
[3, 64, 3, 3]
[128, 64, 96, 96]
1.792
15.925248
1_features.BatchNorm2d_1
[64]
[128, 64, 96, 96]
0.128
0.000064
2_features.ReLU_2
-
[128, 64, 96, 96]
NaN
NaN
3_features.MaxPool2d_3
-
[128, 64, 48, 48]
NaN
NaN
4_features.Conv2d_4
[64, 128, 3, 3]
[128, 128, 48, 48]
73.856
169.869312
5_features.BatchNorm2d_5
[128]
[128, 128, 48, 48]
0.256
0.000128
6_features.ReLU_6
-
[128, 128, 48, 48]
NaN
NaN
7_features.MaxPool2d_7
-
[128, 128, 24, 24]
NaN
NaN
8_features.Conv2d_8
[128, 128, 3, 3]
[128, 128, 24, 24]
147.584
84.934656
9_features.BatchNorm2d_9
[128]
[128, 128, 24, 24]
0.256
0.000128
10_features.ReLU_10
-
[128, 128, 24, 24]
NaN
NaN
11_features.Conv2d_11
[128, 256, 3, 3]
[128, 256, 24, 24]
295.168
169.869312
12_features.BatchNorm2d_12
[256]
[128, 256, 24, 24]
0.512
0.000256
13_features.ReLU_13
-
[128, 256, 24, 24]
NaN
NaN
14_features.MaxPool2d_14
-
[128, 256, 12, 12]
NaN
NaN
15_features.Conv2d_15
[256, 256, 3, 3]
[128, 256, 12, 12]
590.080
84.934656
16_features.BatchNorm2d_16
[256]
[128, 256, 12, 12]
0.512
0.000256
17_features.ReLU_17
-
[128, 256, 12, 12]
NaN
NaN
18_features.Conv2d_18
[256, 512, 3, 3]
[128, 512, 12, 12]
1180.160
169.869312
19_features.BatchNorm2d_19
[512]
[128, 512, 12, 12]
1.024
0.000512
20_features.ReLU_20
-
[128, 512, 12, 12]
NaN
NaN
21_features.MaxPool2d_21
-
[128, 512, 4, 4]
NaN
NaN
22_features.Conv2d_22
[512, 512, 3, 3]
[128, 512, 4, 4]
2359.808
37.748736
23_features.BatchNorm2d_23
[512]
[128, 512, 4, 4]
1.024
0.000512
24_features.ReLU_24
-
[128, 512, 4, 4]
NaN
NaN
25_features.Conv2d_25
[512, 512, 3, 3]
[128, 512, 4, 4]
2359.808
37.748736
26_features.BatchNorm2d_26
[512]
[128, 512, 4, 4]
1.024
0.000512
27_features.ReLU_27
-
[128, 512, 4, 4]
NaN
NaN
28_features.MaxPool2d_28
-
[128, 512, 2, 2]
NaN
NaN
29_features.Conv2d_29
[512, 512, 3, 3]
[128, 512, 2, 2]
2359.808
9.437184
30_features.BatchNorm2d_30
[512]
[128, 512, 2, 2]
1.024
0.000512
31_features.ReLU_31
-
[128, 512, 2, 2]
NaN
NaN
32_features.MaxPool2d_32
-
[128, 512, 1, 1]
NaN
NaN
33_features.AvgPool2d_33
-
[128, 512, 1, 1]
NaN
NaN
34_fc
[512, 2]
[128, 2]
1.026
0.001024
num_epochs = 32
lr = 1e - 5
device = torch. device( 'cuda:1' )
optimizer = torch. optim. Adam( vggnet. parameters( ) , lr= lr)
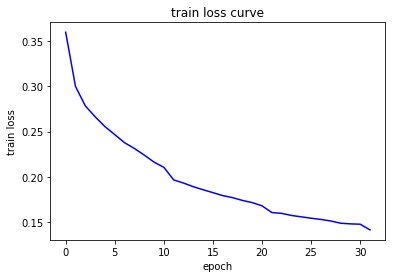
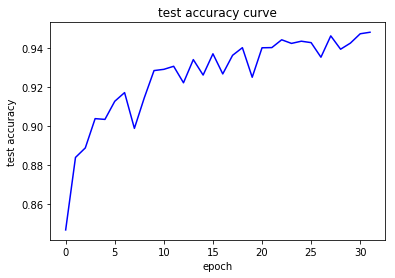
fit( vggnet, num_epochs, optimizer, device)
Epoch 1/32:
Step [100/1996] Train Loss: 0.6435
Step [200/1996] Train Loss: 0.3753
Step [300/1996] Train Loss: 0.3293
Step [400/1996] Train Loss: 0.3352
Step [500/1996] Train Loss: 0.4041
Step [600/1996] Train Loss: 0.3956
Step [700/1996] Train Loss: 0.4544
Step [800/1996] Train Loss: 0.3475
Step [900/1996] Train Loss: 0.3589
Step [1000/1996] Train Loss: 0.2784
Step [1100/1996] Train Loss: 0.3917
Step [1200/1996] Train Loss: 0.2907
Step [1300/1996] Train Loss: 0.2534
Step [1400/1996] Train Loss: 0.2708
Step [1500/1996] Train Loss: 0.2601
Step [1600/1996] Train Loss: 0.2590
Step [1700/1996] Train Loss: 0.2357
Step [1800/1996] Train Loss: 0.3057
Step [1900/1996] Train Loss: 0.2773
Accuracy on Train Set: 85.5044 %
Accuracy on Test Set: 84.6803 %
Epoch 2/32:
Step [100/1996] Train Loss: 0.3205
Step [200/1996] Train Loss: 0.2809
Step [300/1996] Train Loss: 0.2924
Step [400/1996] Train Loss: 0.3045
Step [500/1996] Train Loss: 0.3805
Step [600/1996] Train Loss: 0.3427
Step [700/1996] Train Loss: 0.2957
Step [800/1996] Train Loss: 0.2942
Step [900/1996] Train Loss: 0.3697
Step [1000/1996] Train Loss: 0.2627
Step [1100/1996] Train Loss: 0.3467
Step [1200/1996] Train Loss: 0.1966
Step [1300/1996] Train Loss: 0.3518
Step [1400/1996] Train Loss: 0.3212
Step [1500/1996] Train Loss: 0.3209
Step [1600/1996] Train Loss: 0.2841
Step [1700/1996] Train Loss: 0.3483
Step [1800/1996] Train Loss: 0.3784
Step [1900/1996] Train Loss: 0.2279
Accuracy on Train Set: 88.2840 %
Accuracy on Test Set: 88.3871 %
...
Epoch 30/32:
Step [100/1996] Train Loss: 0.1237
Step [200/1996] Train Loss: 0.1236
Step [300/1996] Train Loss: 0.1687
Step [400/1996] Train Loss: 0.1455
Step [500/1996] Train Loss: 0.0666
Step [600/1996] Train Loss: 0.1796
Step [700/1996] Train Loss: 0.2382
Step [800/1996] Train Loss: 0.0954
Step [900/1996] Train Loss: 0.1450
Step [1000/1996] Train Loss: 0.0748
Step [1100/1996] Train Loss: 0.1481
Step [1200/1996] Train Loss: 0.1721
Step [1300/1996] Train Loss: 0.0872
Step [1400/1996] Train Loss: 0.1785
Step [1500/1996] Train Loss: 0.1604
Step [1600/1996] Train Loss: 0.2249
Step [1700/1996] Train Loss: 0.1070
Step [1800/1996] Train Loss: 0.1704
Step [1900/1996] Train Loss: 0.2214
Accuracy on Train Set: 94.4222 %
Accuracy on Test Set: 94.2350 %
Epoch 31/32:
Step [100/1996] Train Loss: 0.1209
Step [200/1996] Train Loss: 0.1470
Step [300/1996] Train Loss: 0.1198
Step [400/1996] Train Loss: 0.0985
Step [500/1996] Train Loss: 0.1920
Step [600/1996] Train Loss: 0.0988
Step [700/1996] Train Loss: 0.1128
Step [800/1996] Train Loss: 0.1519
Step [900/1996] Train Loss: 0.1162
Step [1000/1996] Train Loss: 0.1357
Step [1100/1996] Train Loss: 0.0848
Step [1200/1996] Train Loss: 0.1087
Step [1300/1996] Train Loss: 0.1963
Step [1400/1996] Train Loss: 0.1025
Step [1500/1996] Train Loss: 0.1235
Step [1600/1996] Train Loss: 0.1427
Step [1700/1996] Train Loss: 0.1792
Step [1800/1996] Train Loss: 0.1654
Step [1900/1996] Train Loss: 0.1518
Accuracy on Train Set: 94.4452 %
Accuracy on Test Set: 94.7130 %
Epoch 32/32:
Step [100/1996] Train Loss: 0.1606
Step [200/1996] Train Loss: 0.0931
Step [300/1996] Train Loss: 0.0738
Step [400/1996] Train Loss: 0.1140
Step [500/1996] Train Loss: 0.1462
Step [600/1996] Train Loss: 0.1682
Step [700/1996] Train Loss: 0.0993
Step [800/1996] Train Loss: 0.2225
Step [900/1996] Train Loss: 0.0880
Step [1000/1996] Train Loss: 0.1019
Step [1100/1996] Train Loss: 0.1696
Step [1200/1996] Train Loss: 0.1691
Step [1300/1996] Train Loss: 0.1612
Step [1400/1996] Train Loss: 0.1052
Step [1500/1996] Train Loss: 0.1834
Step [1600/1996] Train Loss: 0.1454
Step [1700/1996] Train Loss: 0.1393
Step [1800/1996] Train Loss: 0.1126
Step [1900/1996] Train Loss: 0.1546
Accuracy on Train Set: 94.6497 %
Accuracy on Test Set: 94.7910 %
import math
import torch
import torch. nn as nn
import torch. utils. data as Data
import torchvision
class MyRnn ( nn. Module) :
def __init__ ( self, in_dim, hidden_dim, n_layer, n_class) :
super ( MyRnn, self) . __init__( )
self. n_layer = n_layer
self. hidden_dim = hidden_dim
self. lstm = nn. LSTM( in_dim, hidden_dim, n_layer, bidirectional= True )
self. fc1 = nn. Linear( hidden_dim* 4 , 512 )
self. fc2 = nn. Linear( 512 , 64 )
self. fc3 = nn. Linear( 64 , 2 )
self. relu = nn. ReLU( )
self. dropout = nn. Dropout( 0.2 )
def forward ( self, x) :
x = x. view( - 1 , 96 , 96 * 3 )
y = x. permute( [ 1 , 0 , 2 ] )
out, _ = self. lstm( y)
encoding = torch. cat( [ out[ 0 ] , out[ - 1 ] ] , dim= 1 )
result = self. relu( encoding)
result = self. dropout( result)
result = self. fc1( result)
result = self. relu( result)
result = self. dropout( result)
result = self. fc2( result)
result = self. relu( result)
result = self. dropout( result)
result = self. fc3( result)
return result
from torchsummaryX import summary
import torch
summary( model, torch. zeros( ( 128 , 3 , 96 , 96 ) ) )
==================================================================
Kernel Shape Output Shape Params (K) Mult-Adds (M)
Layer
0_lstm - [96, 128, 2048] 35946.5 35.9137
1_relu - [128, 4096] - -
2_dropout - [128, 4096] - -
3_fc1 [4096, 512] [128, 512] 2097.66 2.09715
4_relu - [128, 512] - -
5_dropout - [128, 512] - -
6_fc2 [512, 64] [128, 64] 32.832 0.032768
7_relu - [128, 64] - -
8_dropout - [128, 64] - -
9_fc3 [64, 2] [128, 2] 0.13 0.000128
------------------------------------------------------------------
Params (K): 38077.121999999996
Mult-Adds (M): 38.043775999999994
==================================================================
Kernel Shape
Output Shape
Params (K)
Mult-Adds (M)
Layer
0_lstm
-
[96, 128, 2048]
35946.496
35.913728
1_relu
-
[128, 4096]
NaN
NaN
2_dropout
-
[128, 4096]
NaN
NaN
3_fc1
[4096, 512]
[128, 512]
2097.664
2.097152
4_relu
-
[128, 512]
NaN
NaN
5_dropout
-
[128, 512]
NaN
NaN
6_fc2
[512, 64]
[128, 64]
32.832
0.032768
7_relu
-
[128, 64]
NaN
NaN
8_dropout
-
[128, 64]
NaN
NaN
9_fc3
[64, 2]
[128, 2]
0.130
0.000128
model = MyRnn( 288 , 1024 , 2 , 2 )
model
MyRnn(
(lstm): LSTM(288, 1024, num_layers=2, bidirectional=True)
(fc1): Linear(in_features=4096, out_features=512, bias=True)
(fc2): Linear(in_features=512, out_features=64, bias=True)
(fc3): Linear(in_features=64, out_features=2, bias=True)
(relu): ReLU()
(dropout): Dropout(p=0.2)
)
num_epochs = 70
lr = 1e - 4
device = torch. device( 'cuda:1' )
optimizer = torch. optim. Adam( model. parameters( ) , lr= lr)
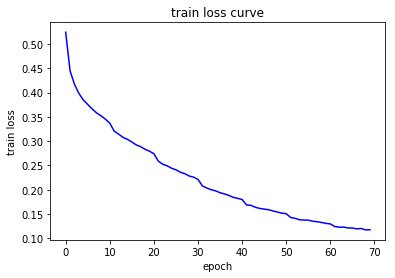
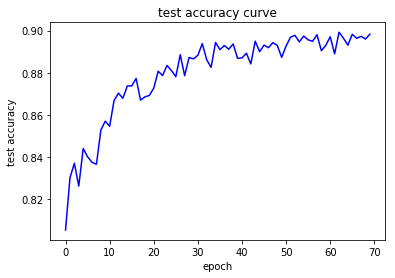
fit( model, num_epochs, optimizer, device)
Epoch 1/70:
Step [100/1559] Train Loss: 0.6516
Step [200/1559] Train Loss: 0.5623
Step [300/1559] Train Loss: 0.5309
Step [400/1559] Train Loss: 0.5903
Step [500/1559] Train Loss: 0.5542
Step [600/1559] Train Loss: 0.5293
Step [700/1559] Train Loss: 0.5013
Step [800/1559] Train Loss: 0.5523
Step [900/1559] Train Loss: 0.5209
Step [1000/1559] Train Loss: 0.5653
Step [1100/1559] Train Loss: 0.4562
Step [1200/1559] Train Loss: 0.4115
Step [1300/1559] Train Loss: 0.4277
Step [1400/1559] Train Loss: 0.4983
Step [1500/1559] Train Loss: 0.4299
Accuracy on Train Set: 79.8193 %
Accuracy on Test Set: 80.5492 %
Epoch 2/70:
Step [100/1559] Train Loss: 0.5156
Step [200/1559] Train Loss: 0.5145
Step [300/1559] Train Loss: 0.5255
Step [400/1559] Train Loss: 0.5319
Step [500/1559] Train Loss: 0.4295
Step [600/1559] Train Loss: 0.4307
Step [700/1559] Train Loss: 0.4712
Step [800/1559] Train Loss: 0.4979
Step [900/1559] Train Loss: 0.3949
Step [1000/1559] Train Loss: 0.5165
Step [1100/1559] Train Loss: 0.3943
Step [1200/1559] Train Loss: 0.4350
Step [1300/1559] Train Loss: 0.5146
Step [1400/1559] Train Loss: 0.2779
Step [1500/1559] Train Loss: 0.4307
Accuracy on Train Set: 81.4396 %
Accuracy on Test Set: 83.0171 %
Epoch 3/70:
Step [100/1559] Train Loss: 0.4699
Step [200/1559] Train Loss: 0.4977
Step [300/1559] Train Loss: 0.4993
Step [400/1559] Train Loss: 0.4876
Step [500/1559] Train Loss: 0.4446
Step [600/1559] Train Loss: 0.5243
Step [700/1559] Train Loss: 0.4131
Step [800/1559] Train Loss: 0.4891
Step [900/1559] Train Loss: 0.5236
Step [1000/1559] Train Loss: 0.3616
Step [1100/1559] Train Loss: 0.5291
Step [1200/1559] Train Loss: 0.4133
Step [1300/1559] Train Loss: 0.3593
Step [1400/1559] Train Loss: 0.4399
Step [1500/1559] Train Loss: 0.3548
Accuracy on Train Set: 82.4125 %
Accuracy on Test Set: 83.7097 %
...
Epoch 69/70:
Step [100/1559] Train Loss: 0.1127
Step [200/1559] Train Loss: 0.1356
Step [300/1559] Train Loss: 0.0965
Step [400/1559] Train Loss: 0.0732
Step [500/1559] Train Loss: 0.0706
Step [600/1559] Train Loss: 0.1228
Step [700/1559] Train Loss: 0.0812
Step [800/1559] Train Loss: 0.1042
Step [900/1559] Train Loss: 0.1054
Step [1000/1559] Train Loss: 0.1461
Step [1100/1559] Train Loss: 0.1589
Step [1200/1559] Train Loss: 0.0724
Step [1300/1559] Train Loss: 0.1406
Step [1400/1559] Train Loss: 0.0955
Step [1500/1559] Train Loss: 0.1438
Accuracy on Train Set: 96.0907 %
Accuracy on Test Set: 89.5966 %
Epoch 70/70:
Step [100/1559] Train Loss: 0.1222
Step [200/1559] Train Loss: 0.0991
Step [300/1559] Train Loss: 0.1290
Step [400/1559] Train Loss: 0.0402
Step [600/1559] Train Loss: 0.0958
Step [800/1559] Train Loss: 0.0545
Step [900/1559] Train Loss: 0.1083
Step [1000/1559] Train Loss: 0.1351
Step [1100/1559] Train Loss: 0.0810
Step [1200/1559] Train Loss: 0.0882
Step [1300/1559] Train Loss: 0.1177
Step [1400/1559] Train Loss: 0.0832
Step [1500/1559] Train Loss: 0.0738
Accuracy on Train Set: 96.1648 %
Accuracy on Test Set: 89.8259 %
save_path = './vgg14.pt'
device = torch. device( 'cuda:0' )
saved_parametes = torch. load( save_path)
new_vgg = VGG( [ 64 , 'M' , 128 , 'M' , 128 , 256 , 'M' , 256 , 512 , 'MM' , 512 , 512 , 'M' , 512 , 'M' ] ) . to( device)
new_vgg. load_state_dict( saved_parametes)
import os
from PIL import Image
def get_result ( model, path) :
imgs = os. listdir( path)
correct = 0
model. eval ( )
with torch. no_grad( ) :
for name in imgs:
img = Image. open ( path+ name)
img = test_transform( img)
s = model( img. unsqueeze( 0 ) . to( device) )
_, pre = torch. max ( s. data, dim= 1 )
if pre. item( ) == ord ( name[ 0 ] ) - 48 :
correct += 1
print ( '在' + path+ '上的准确率为:' , correct/ len ( imgs) )
get_result( vggnet, "./train/1/" )
在./train/1/上的准确率为: 0.9282869008269466
get_result( vggnet, "./train/0/" )
在./train/0/上的准确率为: 0.9639695883826938
get_result( vggnet, "./test/1/" )
在./test/1/上的准确率为: 0.9216738197424893
get_result( vggnet, "./test/0/" )
在./test/0/上的准确率为: 0.9601545174905215
def get_resultcsv ( model) :
path = './predict/'
imgs = os. listdir( path)
model. eval ( )
label = [ ]
i = 0
with torch. no_grad( ) :
for name in imgs:
i += 1
img = Image. open ( path+ name)
img = test_transform( img)
s = model( img. unsqueeze( 0 ) . to( device) )
_, pre = torch. max ( s. data, dim= 1 )
label. append( pre. item( ) )
if i% 1000 == 0 :
print ( "Step [{}/{}] prediction!" . format ( i, len ( imgs) ) )
df = pd. DataFrame( { 'id' : [ x[ : - 4 ] for x in imgs] , 'label' : label} )
df. to_csv( "result.csv" , index= False , sep= ',' )
% % time
import pandas as pd
get_resultcsv( vggnet)
Step [1000/57458] prediction!
...
Step [56000/57458] prediction!
Step [57000/57458] prediction!
CPU times: user 5min 12s, sys: 59.5 s, total: 6min 11s
Wall time: 18min 16s