上级文章
[编译原理随记]正则表达式记号和状态图:https://blog.csdn.net/qq_28033719/article/details/107067798
[编译原理随记]NFA转DFA子集构造算法:https://blog.csdn.net/qq_28033719/article/details/107068996
准备知识
语法制导:
解析(parse)输入的字符串时,在特定位置执行指定的动作。
语法制导算法:
其实就本文内容,解析字符串是什么状态(像>=通常弄个状态图,如果是关键字弄个表暂存比较适合)来说,这个算法相当于对字符串每一个字符进行下一个状态判断,就是 switch(string.charAt(i))这样逐个处理。
NFA状态数 = 正则表达式的 (符号 + 操作符数) * 2:
正则里面常有的运算符 *,| ,连接符
1、输入 ε 和 a(符号),NFA状态图为:
![]()
![]() 状态数都是 2 = 1(符号数为1) * 2
状态数都是 2 = 1(符号数为1) * 2
2、输入 s|t ,NFA状态图为:
 状态数是 6 = 3(符号数2 + 操作数1) * 2
状态数是 6 = 3(符号数2 + 操作数1) * 2
3、s*,NFA状态图为:
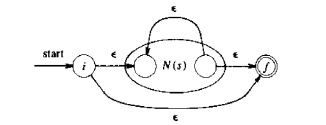 状态数是 4 = 2(符号数1 + 操作符数1) * 2
状态数是 4 = 2(符号数1 + 操作符数1) * 2
所以每多一个符号数或者操作符数,对原图新增的状态数最多2。
出边入边,出度入度:
前后者概念相近,出边入边本文指状态 A 转到下一个状态的边()为出边,进入状态A的边(
)为入边.
而后者相对分化一点,就是专指有向图的出边数( 的出边数量)和入边数(
的入边数量)
NFA三点性质:
1、NFA状态数 = 正则表达式的 (符号 + 操作符数) * 2
2、开始状态无入边,终结状态无出边
3、每个状态有一个[A-Za-z0-9]出边,或者至多两个 ε
Thompsion构造法
例题:将正则表达式 (a|b)*abb 变为 NFA
先将复合正则变为最基本的子表达式,然后进行语法制导(一步一步来)。
1、先处理优先度高的组合 (a | b),首先开始无入边,终结无出边,然后状态有一个字符出边,或者至多两个 ε
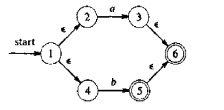
2、处理 (a|b)*,一样,根据 NFA 三性质得出,6 -> 1 状态代表循环输入,1 不能作为开始(有入边)6不能作为终结(有出边):
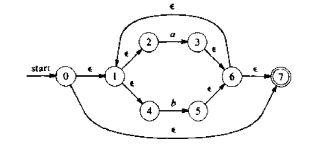
3、再把 abb 拼上去就行了:
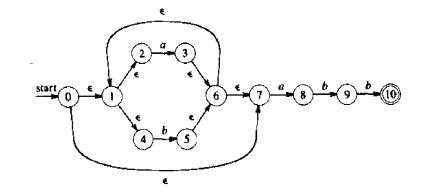
3展示的就是 从正则 (a|b)*abb 转的 状态图。
模拟NFA
用双栈模拟:
因为 ε-closure(move(T , a)), T代表一个状态集合 比如T={1,2}
然后S = ε-closure(move(T , a)), S代表T移动a之后的集合 比如 S={3,4},T S都是多个元素,不是一个确定状态(DFA就是一个)。
所以使用两个栈(存储方面可以理解为数组,只是crud操作不同),存放 S、T 两种状态的转换(因为状态不确定,所以下一个状态是一个集合)
具体算法是:
S := ε-closure(0);
a := nextchar; // 理解为超前标记
while a != eof do begin
S := ε-closure(move(S , a));
a := nextchar;
end
// F 为终结集合
if S != F then
return "no";
return "yes";当然,将 NFA -> DFA也可以不过,这两者都需要衡量空间复杂度和时间复杂度。
DFA 和 NFA 时间空间衡量
NFA 空间是 <= 正则表达式的 (符号 + 操作符数) * 2
DFA 空间是 <= 2 ^ n (n为(a|b)数量,因为这个或运算使用状态数最多,所以推断任意数量 符号 + 操作符数)
NFA 时间复杂度 = 正则表达式的 (符号 + 操作符数) * X(输入的字符串长度,因为每个字符串都匹配)
DFA 时间复杂度 = X(因为每个字符都有一个确定状态,不用遍历)