文章目录
一、Innodb 逻辑存储结构图
Tablespace⊇Segment⊇Extent⊇Page⊇Row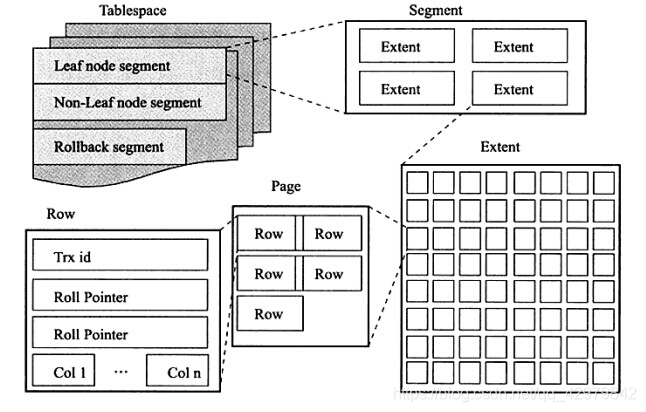
page 结构
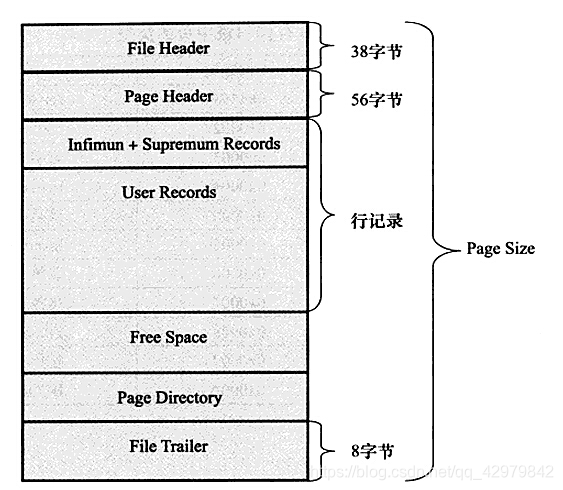
二、数据页结构
| 名称 | 中文名 | 占用空间大小 | 描述 |
|---|---|---|---|
File Header |
文件头部 | 38字节 | 页的一些通用信息 |
Page Header |
页面头部 | 56字节 | 数据页专有的一些信息 |
Infimum + Supremum |
最小记录和最大记录 | 26字节 | 两个虚拟的行记录 |
User Records |
用户记录 | 不确定 | 实际存储的行记录内容 |
Free Space |
空闲空间 | 不确定 | 页中尚未使用的空间 |
Page Directory |
页面目录 | 不确定 | 页中的某些记录的相对位置 |
File Trailer |
文件尾部 | 8字节 | 校验页是否完整 |
2.1 File Header
| 名称 | 占用空间大小 | 描述 |
|---|---|---|
FIL_PAGE_SPACE_OR_CHKSUM |
4字节 | 页的校验和(checksum值) |
FIL_PAGE_OFFSET |
4字节 | 页号 |
FIL_PAGE_PREV |
4字节 | 上一个页的页号 |
FIL_PAGE_NEXT |
4字节 | 下一个页的页号 |
FIL_PAGE_LSN |
8字节 | 页面被最后修改时对应的日志序列位置(Log Sequence Number) |
FIL_PAGE_TYPE |
2字节 | 该页的类型 |
FIL_PAGE_FILE_FLUSH_LSN |
8字节 | 仅在系统表空间的一个页中定义,代表文件至少被刷新到了对应的LSN值 |
FIL_PAGE_ARCH_LOG_NO_OR_SPACE_ID |
4字节 | 页属于哪个表空间 |
FIL_PAGE_OFFSET
- 每个表空间的页号唯一,四个字节
FIL_PAGE_PREV和FIL_PAGE_NEXT
- 上一页和下一页,诶哟,这不是双向链表啊,那所有的页加起来组成了一个双向链表。
FIL_PAGE_TYPE
| 类型名称 | 十六进制 | 描述 |
|---|---|---|
FIL_PAGE_TYPE_ALLOCATED |
0x0000 | 最新分配,还没使用 |
FIL_PAGE_UNDO_LOG |
0x0002 | Undo日志页 |
FIL_PAGE_INODE |
0x0003 | 段信息节点 |
FIL_PAGE_IBUF_FREE_LIST |
0x0004 | Insert Buffer空闲列表 |
FIL_PAGE_IBUF_BITMAP |
0x0005 | Insert Buffer位图 |
FIL_PAGE_TYPE_SYS |
0x0006 | 系统页 |
FIL_PAGE_TYPE_TRX_SYS |
0x0007 | 事务系统数据 |
FIL_PAGE_TYPE_FSP_HDR |
0x0008 | 表空间头部信息 |
FIL_PAGE_TYPE_XDES |
0x0009 | 扩展描述页 |
FIL_PAGE_TYPE_BLOB |
0x000A | BLOB页 |
FIL_PAGE_INDEX |
0x45BF | 索引页,也就是我们所说的数据页 |
2.2 Page Header
| 名称 | 占用空间大小 | 描述 |
|---|---|---|
PAGE_N_DIR_SLOTS |
2字节 | 在页目录中的槽数量 |
PAGE_HEAP_TOP |
2字节 | 还未使用的空间最小地址,也就是说从该地址之后就是Free Space |
PAGE_N_HEAP |
2字节 | 本页中的记录的数量(包括最小和最大记录以及标记为删除的记录) |
PAGE_FREE |
2字节 | 第一个已经标记为删除的记录地址(各个已删除的记录通过next_record也会组成一个单链表,这个单链表中的记录可以被重新利用) |
PAGE_GARBAGE |
2字节 | 已删除记录占用的字节数 |
PAGE_LAST_INSERT |
2字节 | 最后插入记录的位置 |
PAGE_DIRECTION |
2字节 | 记录插入的方向 |
PAGE_N_DIRECTION |
2字节 | 一个方向连续插入的记录数量 |
PAGE_N_RECS |
2字节 | 该页中记录的数量(不包括最小和最大记录以及被标记为删除的记录) |
PAGE_MAX_TRX_ID |
8字节 | 修改当前页的最大事务ID,该值仅在二级索引中定义 |
PAGE_LEVEL |
2字节 | 当前页在B+树中所处的层级 |
PAGE_INDEX_ID |
8字节 | 索引ID,表示当前页属于哪个索引 |
PAGE_BTR_SEG_LEAF |
10字节 | B+树叶子段的头部信息,仅在B+树的Root页定义 |
PAGE_BTR_SEG_TOP |
10字节 | B+树非叶子段的头部信息,仅在B+树的Root页定义 |
2.3 Infimum + Supremum
- 分别是最小记录和最大记录,属于MySQL为每个页添加的虚拟记录
- 由五个字节的记录头 和 八个字节的 值(分别是单词Infimum和Supremum)组成
- 最小记录的记录头中heap_no为0
- 最大记录的记录头中heap_no为1
- 也就是说正式记录中的heap_no属性从2开始
- 最小记录的record_type 是2
- 最大记录的record_type 是3
- 最小记录是页中单链表的头结点
- 最大记录是页中单链表的尾结点
2.4 User Records 和 Free Space
- 完全空闲的页是没有 User Records部分的
- 插入数据时,从Free Space分配空间给User Records,直到Free Space没有空间或空间不够分配新的记录,这时需要申请新的页
2.5 Page Directory
- 这个页目录里面存的是一个一个的槽(slot)
- 每个槽指向组内最大记录的地址偏移量(我理解为页内偏移量)
- 这个数据结构是数组,按主键值从小到大排列
- 这种结构注定了查询最快的方式是二分法,时间复杂度O(lgN)
- 页分裂(前面说过) 时会增加一个槽
三、行格式
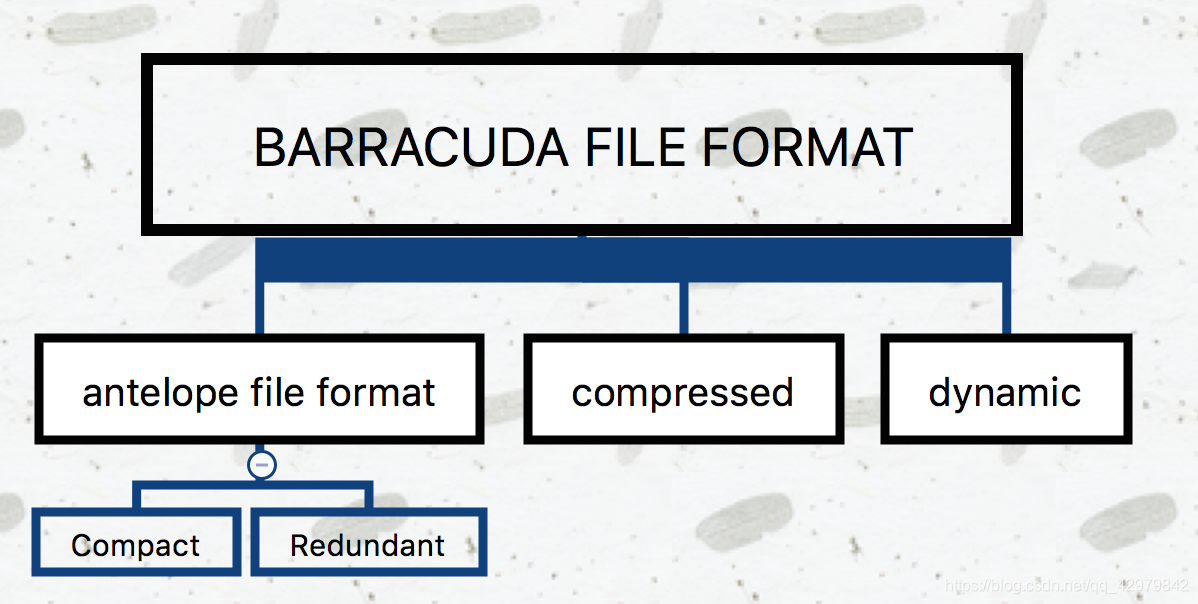
-
Antelope: 先前未命名的,原始的InnoDB文件格式。它支持两种行格式:COMPACT 和 REDUNDANT。MySQL5.6的默认文件格式。可以与早期的版本保持最大的兼容性。不支持 Barracuda 文件格式。
-
Barracuda: 新的文件格式。它支持InnoDB的所有行格式,包括新的行格式:COMPRESSED 和 DYNAMIC。与这两个新的行格式相关的功能包括:InnoDB表的压缩,长列数据的页外存储和索引建前缀最大长度为3072字节。
在 msyql 5.7.9 及以后版本,默认行格式由innodb_default_row_format变量决定,它的默认值是DYNAMIC,也可以在 create table 的时候指定ROW_FORMAT=DYNAMIC。用户可以通过命令 SHOW TABLE STATUS LIKE’table_name’ 来查看当前表使用的行格式,其中 row_format 列表示当前所使用的行记录结构类型。
PS:如果要修改现有表的行模式为compressed或dynamic,必须先将文件格式设置成Barracuda:set global innodb_file_format=Barracuda;,再用ALTER TABLE tablename ROW_FORMAT=COMPRESSED;去修改才能生效。
3.1 Compact
Compact行记录是在MySQL5.0中引入的,为了高效的存储数据,简单的说,就是为了让一个页(Page)存放的行数据越多,这样性能就越高。行记录格式如下:

-
变长字段长度列表:变长字段长度最大不超过2字节(MySQL数据库varcahr类型的最大长度限制为65535)
-
NULL标识位:该位指示了该行数据中是否有NULL值,有则用1。
-
记录头信息:固定占用5字节(40位)
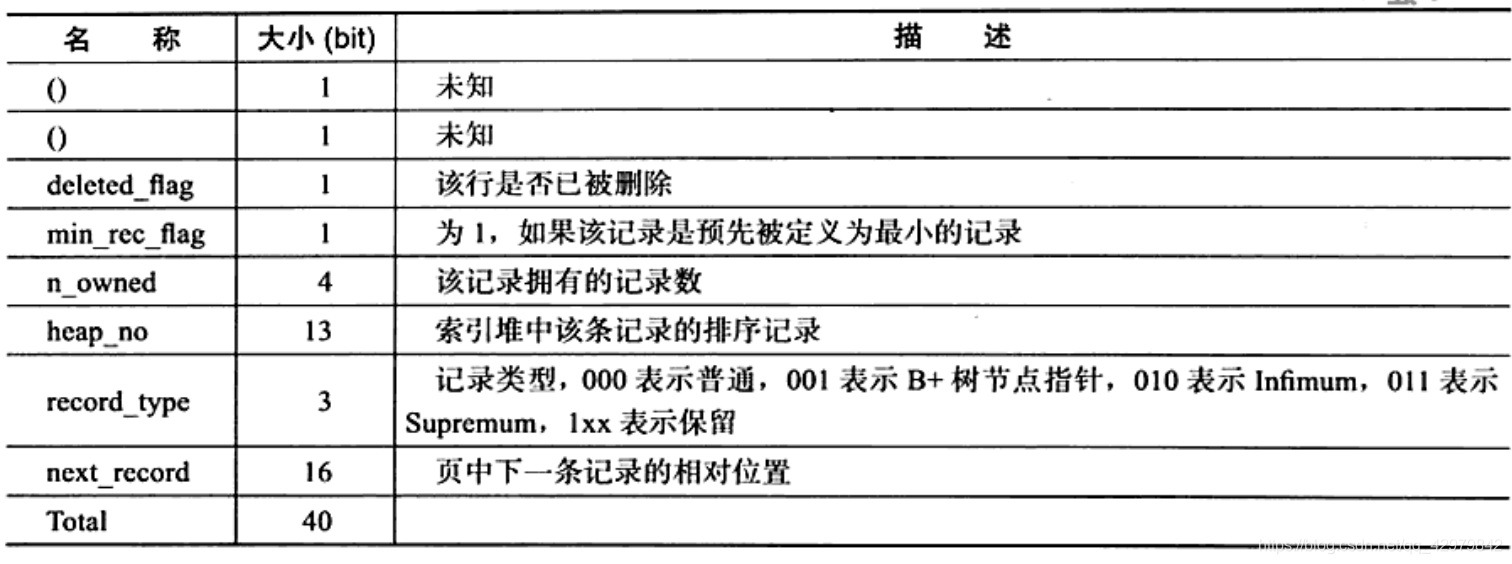
-
列N数据:实际存储每列的数据,NULL不占该部分任何空间,即NULL占有NULL标志位,实际存储不占任何空间。
每一行数据除了用户定义的例外,还有两个隐藏列,事物ID列和回滚指针列,分别位6字节和7字节的大小,若InnoDB表没有定义主键,每行还未增加一个6字节的rowid列。
3.2 Redundant
MySQL5.0之前的行记录格式:

字段偏移列表:同样是按照列的顺序逆序放置的,若列的长度小于255字节,用1字节表示,若大于255字节,用2字节表示。
记录头信息:占用6字节(48位)

3.3 行溢出数据
当行记录的长度没有超过行记录最大长度时,所有数据都会存储在当前页。
当行记录的长度超过行记录最大长度时,变长列(variable-length column)会选择外部溢出页(overflow page,一般是Uncompressed BLOB Page)进行存储。
Compact + Redundant:保留前768Byte在当前页(B+Tree叶子节点),其余数据存放在溢出页。768Byte后面跟着20Byte的数据,用来存储指向溢出页的指针。
对于 Compact 和 Redundant 行格式,InnoDB将变长字段(VARCHAR, VARBINARY, BLOB 和 TEXT)的前786字节存储在B+树节点中,其余的数据存放在溢出页(off-page),如下图:
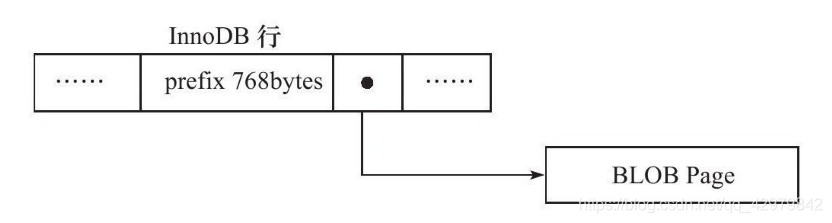
上面所讲的讲的blob或变长大字段类型包括blob,text,varchar,其中varchar列值长度大于某数N时也会存溢出页,在latin1字符集下N值可以这样计算:innodb的块大小默认为16kb,由于innodb存储引擎表为索引组织表,树底层的叶子节点为一双向链表,因此每个页中至少应该有两行记录,这就决定了innodb在存储一行数据的时候不能够超过8k,减去其它列值所占字节数,约等于N。
使用Antelope文件格式,若字段的值小于等于786字节,不需要溢出页,因为字段的值都在B+树节点中,所以会降低I/O操作。这对于相对较短的BLOB字段有效,但可能由于B+树节点存储过多的数据而导致效率低下。
3.4 Compressed 和 Dynamic
InnoDB1.0x开始引入心的文件格式Barracuda,这个新的格式拥有两种新的行记录格式:Compressed和Dynamic。
新的两种记录格式对于存放BLOB中的数据采用了完全的行溢出的方式。如图:
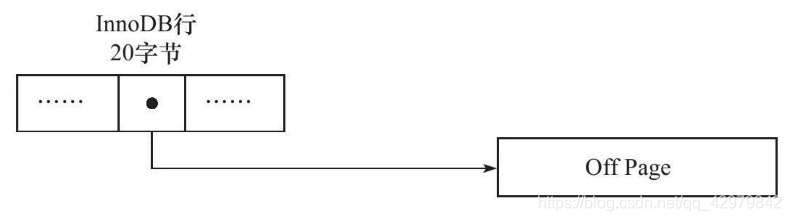
Dynamic行格式,列存储是否放到off-page页,主要取决于行大小,他会把行中最长的一列放到off-page,直到数据页能存放下两行。TEXT或BLOB列<=40bytes时总是存在于数据页。这种方式可以避免compact那样把太多的大列值放到B-tree Node(数据页中只存放20个字节的指针,实际的数据存放在Off Page中,之前的Compact 和 Redundant 两种格式会存放768个字前缀字节)。
Compressed物理结构上与Dynamic类似,Compressed行记录格式的另一个功能就是存储在其中的行数据会以zlib的算法进行压缩,因此对于BLOB、TEXT、VARCHAR这类大长度数据能够进行有效的存储(减少40%,但对CPU要求更高)。
四、总结
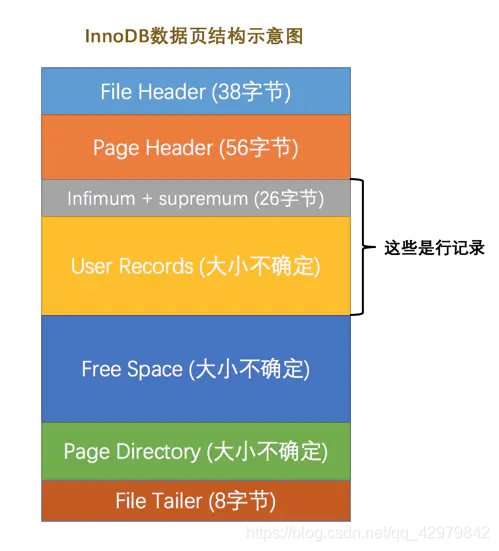
InnoDB为了不同的目的设计了不同类型的页,我们把用于存放记录的页叫做数据页
一个数据页可以被大致分为7个部分,分别是:
- File Header:表示页的一些通用信息,占固定的38字节
- Page Header:表示数据页专有的一些信息,占固定的56个字节
- Infimum + Supremum:两个虚拟的伪记录,分别表示页中的最小和最大记录,占固定的26个字节
- User Records:真实存储我们插入的记录的部分,大小不固定
- Free Space:页中尚未使用的部分,大小不确定
- Page Directory:页中的某些记录相对位置,也就是各个槽在页面中的地址偏移量,大小不固定,插入的记录越多,这个部分占用的空间越多
- File Trailer:用于检验页是否完整的部分,占用固定的8个字节
每个记录的头信息中都有一个next_record属性,从而使页中的所有记录串联一单个链表
InnoDB会为把页中的记录划分为若干个组,每个组的最后一个记录的地址偏移量作为一个槽,存放在Page_Directory中,所以在一个页中根据主键查找记录是非常快的。
通过记录的next_record属性遍历该槽所在的组中的各个记录
每个数据页的File Header 部分都有上一个和下一个页的编号,所以所有的数据页会组成一个双链表
为保证从内存中同步到磁盘的页的完整性,在页的首部和尾部都会存储页中数据的校验和和页面最后修改时对应的LSN值,如果首部和尾部的校验和和LSN值校验不成功的话,就说明同步失败了。