目录
函数也是对象,内存底层分析
python中一切都是对象。实际上,执行def定义函数后,系统就创建了对应的函数对象。
#测试函数也是对象
def print_star(n):
print("*"*n)
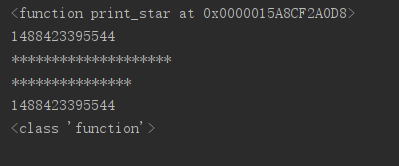
print(print_star)
print(id(print_star))
print_star(20)
c=print_star
c(15)
print(id(c))#此时c的地址和print_star的一样
print(type(c))#c的类型也是函数
运行结果:
变量的作用域(全局变量和局部变量)
变量起作用的范围称为变量的作用域,不同作用域内同名变量之间相互不影响。变量分为全局变量和局部变量
全局变量
1.在函数和类定义之外声明的变量。作用域为定义的模块,从定义位置开始直到模块结束。
2.全局变量降低了函数的通用性和可读性。应尽量避免全局变量的使用。
3.全局变量一般做常量使用。
4.函数内要改变全局变量的值,使用global声明一下
局部变量
1.在函数体中(包含形式参数)声明的变量。
2.局部变量的引用比全局变量快,优先考虑使用局部变量。
3.如果局部变量和全局变量同名,则在函数内隐藏全局变量,只使用同名的局部变量
a = 100 # 全局变量
#测试全局变量和局部变量
a=3#全局变量
def haha():
b=3
print(b)
print(locals())#打印所有局部变量(结果以字典输出)
print(globals())#打印所有全局变量(结果以字典输出)
haha()
print(a)#全局变量可以打出来
print(b)#局部变量打不出来
局部变量和全局变量效率测试
局部变量的查询和访问速度比全局变量快,优先考虑使用,尤其是在循环的时候。
在特别强调效率的地方或者循环次数较多的地方,可以通过将全局变量转为局部变量提高运行速度。
#测试全局变量和局部变量的效率
import math
import time
def test_01():
start=time.time()
for i in range(10000000):
math.sqrt(30)
end=time.time()
print("{0}".format((start-end)))
def test_02():
start=time.time()
b=math.sqrt
for i in range(10000000):
b(30)
end=time.time()
print("{0}".format((start-end)))
test_01()
test_02()
运行结果:
参数的传递
函数的参数传递本质上就是:从实参到形参的赋值操作。
Python中“一切皆对象”,所有的赋值操作都是“引用的赋值”。所以,Python中参数的传递都是“引用传递”,不是“值传递”。具体操作时分为两类:
1.对“可变对象”进行“写操作”,直接作用于原对象本身。
2.对“不可变对象”进行“写操作”,会产生一个新的“对象空间”,并用新的值填充这块空间。(起到其他语言的“值传递”效果,但不是“值传递”)
可变对象
字典、列表、集合、自定义的对象等
不可变对象
数字、字符串、元组、function等
传递可变对象的引用
传递参数是可变对象例如(字典、列表、集合、自定义的对象等),实际传递的还是对象的引用。在函数体中不创建新的对象拷贝,而是可以直接修改所传递的对象。
[操作]参数传递: 传递可变对象的引用
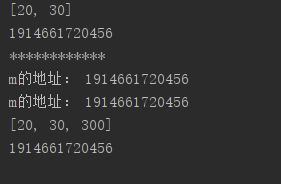
a=[20,30]
print(a)
print(id(a))
print("************")
def gogo(m):
print("m的地址:",id(m))#a和m是同一个对象
m.append(300)#由于m是可变对象,所以不创建对象拷贝,而是直接修改这个对象
print("m的地址:",id(m))
gogo(a)
print(a)
print(id(a))
运行结果:
传递不可变对象的引用
传递参数是不可变对象(例如:int、float、字符串、元组、布尔值),在赋值操作时,由于不可变对象无法修改,系统会创建一个新对象。
[操作]参数传递:传递不可变对象的引用
a=100
print(a)
print(id(a))
print("************")
def haha(n):
print("n的地址:",id(n))#传递进来的是a对象的地址
n=n+200 #由于a是不可变对象,所以创建新的对象n
print("n的新地址:",id(n))#n已经是新的对象
print(n)
haha(a)
print(a)#打印的还是原对象
运行结果:
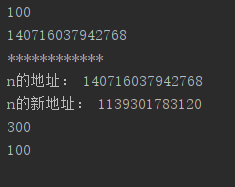
显然,通过id值我们可以看到n和a一开始是同一个对象,给n赋值后,n是新的对象。
浅拷贝和深拷贝
我们可以使用内置函数:copy(线接贝)、deepcopy(深拷贝)。
浅拷贝:
不拷贝子对象的内容,只是拷贝子对象的引用。
深拷贝:
会连子对象的内存也全部烤贝一份,对子对象的修改不会影响源对象。
浅拷贝
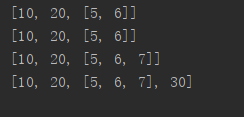
#测试浅拷贝
import copy
a=[10,20,[5,6]]
b=copy.copy(a)#浅拷贝,只拷贝了a指向的地址
print(a)
print(b)
b.append(30)#加了一个新元素,加到b里所以a没有
b[2].append(7)#b[2]指向的a[2]的地址,加了个7,就加到了a[2]里,a就有了
print(a)
print(b)
运行结果:
深拷贝
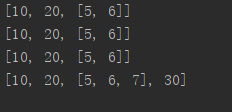
#测试深拷贝
import copy
a=[10,20,[5,6]]
b=copy.deepcopy(a)#深拷贝,带内存拷贝了a,有了纯粹独立带内存的b
print(a)
print(b)
b.append(30)#给b地址里加
b[2].append(7)#给b[2]加,不影响a
print(a)
print(b)
运行结果:
传递不可变对象是浅拷贝
传递参数是不可变对象(例如:int、float、字符串、元组、布尔值),实际传递的还是对象的引用。但在”写操作”时,会创建一个新的对象拷贝。这个拷贝使用的是“浅拷贝“,不是“深拷贝”。
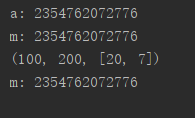
##传递不可变对象,如果发生拷贝,是浅拷贝
a=(100,200,[6,7])#as是元组是不可变对象
print("a:",id(a))
def hah(m):
print("m:",id(m))
m[2][0]=20 '''由于对不可变对象是浅拷贝,只拷贝了地址,
而该地址里是列表对象,列表对象可变,所以结果变了'''
print(m)
print("m:",id(m))
hah(a)
运行结果:
参数的几种类型
位置参数
函数调用时,实参默认按位顺序传递,需要个数和形参匹配。按位置传递的参数,称为:“位置参数”。
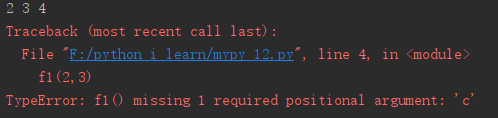
[操作]测试位置参数
def f1(a,b,c):
print(a,b,c)
f1(2,3,4)
f1(2,3)#报错,参数个数不匹配
运行结果:
默认值参数
我们可以为某些参数设置默认值,这样这些参数在传递时就是可选的。称为“默认值参数”。默认值参数放到位置参数后面。
[操作]测试默认值参数
def f1(a,b,c=10,d=20):#默认值参数必须位于普通位置参数后面
print(a,b,c,d)
f1(2,3)
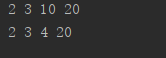
f1(2,3,4)#传了就覆盖掉原来的c
运行结果:
命名参数
按照形参的名称传递参数,称为“命名参数”,也称“关键词参数”
[操作]测试命名参数
def f1(a,b,c):
print(a,b,c)
f1(2,3,4)#默认值参数
f1(c=2,b=3,a=4)#命名参数,通过形参名字来匹配
运行结果:

可变参数
可变参数指的是"可变数量的参数"。分两种情况:
1."param(一个星号),将多个参数收集到一个"元组"对象中.
2"param(两个星号),将多个参数收集到一个"字典"对象中。
[操作]测试可变参数处理(元组,字典两种方式)
在这里插入代码片
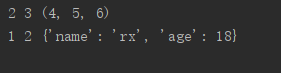
def f1(a,b,*c):
print(a,b,c)
f1(2,3,4,5,6)#4,5,6按元组放到c中了,c是一个元组
def f2(a,b,**c):
print(a,b,c)
f2(1,2,name="rx",age=18)
'''name="rx",age=18都放到c里,c是一个字典'''
运行结果:
强制命名参数
在带号的"可变参数”后面增加新的参数,必须是"强制命名参数".
[操作]强制命名参数的使用
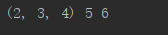
def f1(*a,b,c):
print(a,b,c)
'''f1(2,3,4,5,6)会报错,会将所有数字全部收集,
导致b,c无赋值'''
f1(2,3,4,b=5,c=6)
运行结果:
lambda表达式和匿名函数
lambda表达式可以用来声明匿名函数.lambda函数是一种简单的,在同一行中定义函数的方法.lambda函数实际生成了一个函数对象.
lambda表达式只允许包含一个表达式,不能包含复杂语句,该表达式的计算结果就是函数的返回值。
lambda表达式的基本语法如下:
lambda arg1,arg2,arg3.:<表达式>
arg1/arg2/arg3为函数的参数.<表达式>相当于函数体。运算结果是:表达式的运算结果.
[操作]lambda表达式
f=lambda a,b,c,d:a*b*c*d
print(f(1,2,3,4))
g=[lambda a:a*2,lambda b:b*3,lambda c:c*4]
print(g[2](4))
运行结果::

eval()函数)
(倒是没听懂)
功能:将字符串str当成有效的表达式来求值并返回计算结果。
语法:eval(source[,globalsl[,locals]])-> value
参数:
source:一个Python表达式或函数compile()返回的代码对象
globals:可选.必须是dictionary
locals:可选,任意映射对象
[操作]测试eval函数
递归函数
逆归函数指的是:自己调用自己的函数,在函数体内部直接或间接的自己调用自己.递归类似于大家中学数学学习过的“数学归纳法.每个递归函数必须包含两个部分:
1.终止条件
表示递归什么时候结束。一般用于返回值,不再调用自己。
2.递归步骤
把第n步的值和第n-1步相关联
递归函数由于会创建大量的函数对象、过量的消耗内存和运算能力。在处理大量数据时,谨慎使用。
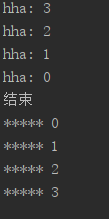
def hha(n):
print("hha:",n)
if n==0:
print('结束')
else:
hha(n-1)
print("*****",n)#最后调用,先被执行。
hha(3)
运行结果:
递归实现阶乘
#使用递归函数算阶乘
def jiec(n):
if n>0:
return n*jiec(n-1)
else:
return 1
a=jiec(5)
print(a)
运行结果:
120