一、处理星期数据
1、datetime对象的weekday()方法
该方法将会用0到6这七个数字表示周一到周日
2、计算周一到周五数据平均值的三种方法
- 数组[关系表达式]:关系表达式的值是一个布尔型数组,其中为True的元素是数组中满足关系表达式的元素。以上下标运算的值就是从数组拣选与布尔数组中为True的元素相对于的元素。
- np.where(关系表达式):数组中满足关系表达式的元素的下标数组
- np.take(数组, 下标数组):数组中由下标数组所表示的元素的集合
3、按星期求均值案例
import numpy as np
import datetime as dt
# 将日期转换成天数
def dmy2week(dmy):
dmy = str(dmy, encoding='utf-8')
date = dt.datetime.strptime(dmy, '%d-%m-%Y').date()
wdays = date.weekday() # 将日期变成星期的格式
return wdays
# 解包取出日期、收盘价
wdays, closing_prices = np.loadtxt(
'0=数据源/beer_price.csv', delimiter=',',
usecols=(0, 4), unpack=True,
converters={0: dmy2week}
)
# print(wdays)
# 计算周一到周五的平均值
ave_closing_prices = np.zeros(7)
for wday in range(ave_closing_prices.size):
# 方法一:用掩码的方法
# ave_closing_prices[wday] = \
# closing_prices[wdays == wday].mean()
# 方法二:用下标序列直接获取对应元素的均值
# ave_closing_prices[wday] = \
# closing_prices[np.where(wdays == wday)].mean()
# 方法三:take方法,一参是被提取数组,二参是下标数组
ave_closing_prices[wday] = \
np.take(closing_prices, np.where(wdays == wday)).mean()
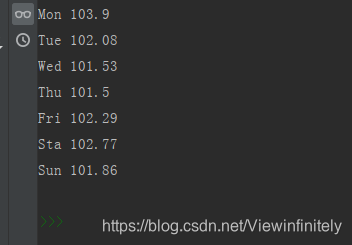
for wday, ave_closing_price in zip(
['Mon','Tue','Wed','Thu','Fri','Sta','Sun'],
ave_closing_prices):
print(wday, np.round(ave_closing_price, 2)) # 保留两位小数
二、apply_along_axis函数的用法
1、格式
Y = numpy.apply_along_axis(函数, 轴向, 高维数组)
2、作用
再高维数组中沿着指向的轴向,提出低维子数组,作为参数传递给函数中,并将返回值按照同样的轴向组成新的数组返回给调用者。
3、轴向
二维:0是行方向,1是列方向
三维:0是页方向,1是行方向,2是列方向
4、练习
import numpy as np
def Func(x):
return x ** 2
# X = [10, 11, 12]
X = np.array([
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
])
Y1 = np.apply_along_axis(Func, 0, X)
print(Y1)
Y2 = np.apply_along_axis(Func, 1, X)
print(Y2)
# 将X沿着二参所指向的轴向来降维传入一参的函数中进行处理
# 此处的0表示沿着行方向降维,即纵向,则分别传入[1, 2, 3]、[4, 5, 6]、[7, 8, 9]
# 若是1则是沿着列方向降维,即横向,则分别传入[1, 4, 7]、[2, 5, 8]、[3, 6, 9]
三、星期汇总案例
1、目的
对每一个星期的数据进行汇总,将每个星期的星期一开盘价作为开盘价,每个星期的星期五的收盘价作为收盘价,整个星期的所有最高价中的最高价作为最高价,最低价作为最低价。这样就是将一个星期作为一个整体,分别求出各个星期整体的开盘价,最高价,最低价,收盘价了。
2、参考代码
import datetime as dt
import numpy as np
def dmy2wday(dmy):
dmy = str(dmy, encoding='utf-8') # 转码dmy日期
date = dt.datetime.strptime(dmy, '%d-%m-%Y').date() # 获取时间对象
wday = date.weekday() # 转换成星期的格式
return wday
wdays, opening_prices, highest_prices, lowest_prices, closing_prices = np.loadtxt(
'0=数据源/beer_price.csv', delimiter=',',
usecols=(0, 1, 2, 3, 4), unpack=True,
converters={0: dmy2wday}
)
# 只取前16个数据,索引是0到15,正好是4*4
wdays = wdays[:16]
opening_prices = opening_prices[:16]
highest_prices = highest_prices[:16]
lowest_prices = lowest_prices[:16]
closing_prices = closing_prices[:16]
# print(np.where(wdays == 0)) # 所有为0的下标,即所有星期一的日期
# 获取第一个星期一的下标
first_monday = np.where(wdays == 0)[0][0]
# 获取最后一个星期五的下标
last_sunday = np.where(wdays == 4)[0][-1]
# 取所有的日期:所有的日期都应该在第一个星期一到最后一个星期五之间
indices = np.arange(first_monday, last_sunday + 1)
indices = np.split(indices, 3) # 分成三份,三个星期
# print(indices)
# 按照每一个星期来处理每个星期的数据
# 汇总每个星期的数据,传入的indices是每周的下标
def week_summary(indices):
opening_price = opening_prices[indices[0]] # 第一周第一天的开盘价
highest_price = np.max(np.take(highest_prices, indices)) # 所有最高价中与idices下标相对应的数据,再取最大值,就是本周的最高价
lowest_price = np.min(np.take(lowest_prices, indices)) # 本周最低价中的最小值
closing_price = closing_prices[indices[-1]] # 最后一个及交易日的收盘价
return opening_price, highest_price,\
lowest_price, closing_price
# 让每周的数据做汇总,传入汇总函数与对应的下标,因为是二维数组,1表示列方向即水平方向
summaries = np.apply_along_axis(
week_summary, 1, indices
)
print(summaries)
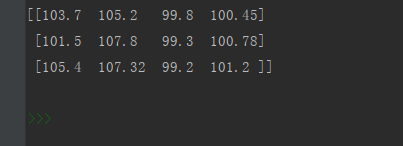
3、参考结果