4. Redis功能实现机制
4.1 持久化
由于Redis是内存数据库,它将自己的数据库状态存储在内存里面,所以如果不想办法将储存在内存中的数据库状态保存到磁盘里面,那么一旦服务器退出,服务器中的数据库状态也会消失不见。为了解决这个问题,Redis提供了RDB、AOF持久化方式,将内存中的数据保存到磁盘中,避免数据意外丢失。
(1)RDB
RDB持久化通过将服务器某个时间点上的数据库状态(非空数据库以及相关键值对)保存到一个RDB文件中,Redis服务器可以用它来还原数据库状态。 SAVE命令会阻塞Redis服务器进程。而BGSAVE会派生出一个子进程,然后由子进程负责创建RDB文件,服务器父进程继续处理命令请求。还可以SAVE命令设置自动间隔保存, 例如SAVE 60 10000 服务器在60秒之内,对数据库进行了至少10000次修改,自动执行BGSAVE命令。RDB文件是一个经过压缩的二进制文件。
(a)服务器状态结构redisServer的saveparams属性用来保存一个save选项设置的保存条件。
(b) dirty计数器记录距离上一次成功执行SAVE命令或者BGSAVE命令之后,服务器对数据库状态进行了多少次修改。lastsave属性是一个时间戳,记录了服务器上一次成功执行SAVE或BGSAVE命令的时间

(2)AOF(重点)
AOF持久化通过保存Redis服务器所执行的写命令来记录数据库状态的。被写入AOF文件的所有命令都是以Redis的命令请求协议格式保存的,Redis的命令请求协议保存为纯文本格式。
AOF持久化功能的实现分为命令追加、文件写入、文件同步三个步骤:
当AOF持久化处于打开状态时,服务器在执行完一个写命令后,会以协议格式将被执行的写命令(如SET、SADD、RPUSH)追加到服务器状态的aof_buf缓冲区的末尾。
服务器在每次结束一个事件循环之前,它都会调用flushAppendOnlyFile函数,考虑是否需要将aof_buf缓冲区中的内容写入和保存到AOF文件里面。flushAppendOnlyFile函数的行为由服务器配置的appendfsync选项的值( always 、 everysec(默认) 、 no )来决定。


(3)RDB与AOF对比
RDB
优点:RDB 是一个非常紧凑的文件,它保存了 Redis 在某个时间点上的数据集。这种文件非常适合用于进行备份。
缺点:如果你需要尽量避免在服务器故障时丢失数据,那么 RDB 不适合你。 虽然 Redis 允许你设置不同的保存点(save point)来控制保存 RDB 文件的频率, 但是, 因为RDB 文件需要保存整个数据集的状态,所以它并不是一个轻松的操作。因此你可能会至少 5 分钟才保存一次 RDB 文件。 在这种情况下, 一旦发生故障停机, 你就可能会丢失好几分钟的数据。
AOF(重点)
优点:使用 AOF 持久化会让 Redis 变得非常耐久:你可以设置不同的 fsync 策略,比如无 fsync ,每秒钟一次 fsync ,或者每次执行写入命令时 fsync 。 AOF 的默认策略为每秒钟 fsync 一次,在这种配置下,Redis 仍然可以保持良好的性能,并且就算发生故障停机,也最多只会丢失一秒钟的数据( fsync 会在后台线程执行,所以主线程可以继续努力地处理命令请求)。
缺点:对于相同的数据集来说,AOF 文件的体积通常要大于 RDB 文件的体积。根据所使用的 fsync 策略,AOF 的速度可能会慢于 RDB 。
注意:Redis不适合用于做分布式锁,除了Redis本身是一个AP模型(主库挂掉而还没同步到从库)而分布式锁是一个CP模型问题,Redis一般在金融场景下采用的AOP的持久化方式,一般也采用默认的everysec同步方式,即开另外一个同步线程每秒钟同步一次,Redis一般在金融场景下不用于做分布式锁。尤其对代扣,代付业务。并且代扣代付业务的自动过期时间不能太短。将在分布式锁章节有分析。
4.2 事务
Redis中的事务是一组命令的集合。事务同命令一样都是Redis的最小执行单位,一个事务中的命令要么都执行,要么都不执行。一个事务从开始到结束通常会经过事务开始、命令入队、事务执行三个阶段。
Redis实际上是单个线程,这样能确保每个操作都是原子操作。当一个命令被执行,其他命令都不会运行。(我们将在下一个章节中讲到scaling)。当你考虑到一些命令在完成多个事情的时候特别有用。
每个Redis客户端都有自己的事务状态,保存在mstate属性中。进一步,每一个事务状态包含一个事务队列以及已入队命令的计数器,事务队列是一个数组,数组中的每个元素保存了已入队命令的相关信息,包含指向命令实现函数的指针、命令的参数,以及参数的数量。

注意:Atomicity of scripts(lua脚本的原子操作类似于multi/exec命令,所以为啥redis在某些场景下可以用作分布式锁)
Redis uses the same Lua interpreter to run all the commands. Also Redis guarantees that a script is executed in an atomic way: no other script or Redis command will be executed while a script is being executed. This semantic is similar to the one of MULTI / EXEC. From the point of view of all the other clients the effects of a script are either still not visible or already completed.
4.3 发布与订阅
redis的订阅与发布完全是鸡肋,建议使用RocketMQ,在生产上经常会遇到莫名其妙的问题,不建议使用,除非你是背锅侠。
Redis提供了一组命令可以让开发者实现“发布/订阅” (publish/subscribe)模式。“发布/订阅”模式可以实现进程间的消息传递,“发布/订阅”模式中包含两种角色,分别是发布者和订阅者。订阅者可以订阅一个或若干个频道,发布者可以向指定的频道发送消息,所有订阅此频道的人都会收到此消息。

原理:
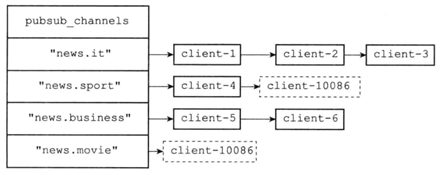
Redis将所有频道的订阅关系都保存在服务器状态的pubsub_channels字典里面,这个字典的键是某个被订阅的频道,而键的值则是一个链表,链表里面记录了所有订阅这个频道的客户端。在MQ章节里会介绍RockeMQ、KafKa、RabitMQ、Redis的原理对比。
每当客户端执行SUBSCRIBE命令订阅某个或某些频道的时候,服务器都会将客户端与被订阅的频道在pubsub_channels字典中进行关联。如果频道已经有其他订阅者,那么它在pubsub_channels字典中必然有相应的订阅者链表,程序唯一要做的就是将客户端添加到订阅者链表的末尾如果频道还未有任何订阅者,程序首先在pubsub_channels字典中为频道创建一个键,并将这个键的值设置为空链表,然后成为第一个链表中的元素。
**
4.4 集群
过程:
(1)节点握手
Redis集群是Redis提供的分布式数据库方案,集群通过分片来进行数据共享,并提供复制和故障转移功能。一个Redis集群通常由多个节点(node)组成,(这里的数据只在某个节点上存储一份),在刚开始的时候,每个节点都是相互独立的,它们都处于一个只包含自己的集群当中,要组建一个真正可工作的集群,必须将这些独立的节点连接起来,构成一个包含多个节点的集群。使用CLUSTER MEET命令,可以让node节点与ip和port所指定的节点添加到node节点当前所在的集群中。
CLUSTER MEET 127.0.0.1 7001
过程:

(2)槽指派
Redis集群通过分片的方式来保存数据库中的键值对:集群中的整个数据库被分为16384个槽(slot),数据库中的每个键都属于这些槽中的一个,集群中的每个节点可以处理0个或最多16834个槽。
127.0.0.1:7000> CLUSTER ADDSLOTS 0 1 2 3 4…5000
一个节点除了会将自己负责的槽记录下来以外,还会通过消息发送给集群中的其他节点,以此来告知其他节点自己负责处理哪些槽。
因此集群中的每个节点都会知道数据库中的16834个槽分别被指派给了集群中的哪些节点。

(3)执行命令、重新分片
当客户端向节点发送与数据库键有关的命令时,接收命令的节点会计算出命令要处理的数据库键属于哪个槽,并检查这个槽是否指派给了自己。涉及到两个算法:计算键属于哪个槽?判断键是否由当前节点处理?
当节点发现键所在的槽并非由自己负责的时候,节点就会向客户端返回一个MOVED错误,指引客户端转向至正在负责槽的节点。
Redis集群的重新分片操作可以将任意数量已经指派给某个节点(源节点)的槽改为指派给另一个节点,并且相关槽所在的键值对也会从源节点被移动到目标节点。在进行重新分片期间,源节点向目标节点迁移一个槽的过程中,可能会出现这样一种情况:属于被迁移槽的一部分键值对保存在源节点里面,而另一部分键值对则保存在目标节点里面。


4.5 排序
redis支持对list,set,sorted set元素的排序。但是不建议用redis对大量数据进行排序,因为redis是单线程,对大量数据进行排序需要消耗线程大量时间,导致不能服务其他更加紧急的请求。
4.6 事件
redis事件可以参考:
https://blog.csdn.net/u010900754/article/details/77602160
https://www.cnblogs.com/paulversion/p/8314164.html
5. 探讨 Redis与Memcached比较
Memcached只有String结构。
Redis默认有16个数据库db。
其他待续。。。
6.Redis运维
6.1运维常用的server端命令
TIME 查看时间戳与微秒数
DBSIZE 查看当前库中的key数量
BGREWRITEAOF 后台进程重写AOF
BGSAVE 后台保存rdb快照
SAVE 保存rdb快照
LASTSAVE 上次保存时间
SLAVEOF 设为slave服务器
FLUSHALL 清空所有db
FLUSHDB 清空当前db
SHUTDOWN[""|save|nosave] 断开连接,关闭服务器
SLOWLOG 显示慢查询
INFO 显示服务器信息
CONFIG GET 获取配置信息
CONFIG SET 设置配置信息
MONITOR 打开控制台
SYNC 主从同步
CLIENT LIST 客户端列表
CLIENT KILL 关闭某个客户端
CLIENT SETNAME 为客户端设置名字
CLIENT GETNAME 获取客户端名字
6.2运维时的观察参数
1: 内存
Memory
used_memory:859192 数据结构的空间
used_memory_rss:7634944 实占空间
mem_fragmentation_ratio:8.89 前2者的比例,1.N为佳
2: 主从复制
Replication
role:slave
master_host:192.168.1.128
master_port:6379
master_link_status:up
3:持久化
Persistence
rdb_changes_since_last_save:0
rdb_last_save_time:1375224063
4: fork耗时
#Status
latest_fork_usec:936 上次持久化花费微秒
5: 慢日志
config get/set slowlog-log-slower-than
CONFIG get/SET slowlog-max-len
slow log get 获取慢日志
6.3 sentinel监控主从服务器
6.4 sentinel监控配置及平滑迁移
sentinel monitor def_master 127.0.0.1 6379 2
sentinel auth-pass def_master 012_345^678-90
##master被当前sentinel实例认定为“失效”的间隔时间
##如果当前sentinel与master直接的通讯中,在指定时间内没有响应或者响应错误代码,那么
##当前sentinel就认为master失效(SDOWN,“主观”失效)
##
##默认为30秒
sentinel down-after-milliseconds def_master 30000
##当前sentinel实例是否允许实施“failover”(故障转移)
##no表示当前sentinel为“观察者”(只参与"投票".不参与实施failover),
##全局中至少有一个为yes
sentinel can-failover def_master yes
##sentinel notification-script mymaster /var/redis/notify.sh
sentinel模式
sentinel模式的简介和配置,同上不再赘述。
sentinel的中文含义是哨兵、守卫。也就是说既然主从模式中,当master节点挂了以后,slave节点不能主动选举一个master节点出来,那么我就安排一个或多个sentinel来做这件事,当sentinel发现master节点挂了以后,sentinel就会从slave中重新选举一个master。
对sentinel模式的理解:
sentinel模式是建立在主从模式的基础上,如果只有一个Redis节点,sentinel就没有任何意义
当master节点挂了以后,sentinel会在slave中选择一个做为master,并修改它们的配置文件,其他slave的配置文件也会被修改,比如slaveof属性会指向新的master
当master节点重新启动后,它将不再是master而是做为slave接收新的master节点的同步数据
sentinel因为也是一个进程有挂掉的可能,所以sentinel也会启动多个形成一个sentinel集群
当主从模式配置密码时,sentinel也会同步将配置信息修改到配置文件中,不许要担心。
一个sentinel或sentinel集群可以管理多个主从Redis。
sentinel最好不要和Redis部署在同一台机器,不然Redis的服务器挂了以后,sentinel也挂了
sentinel监控的Redis集群都会定义一个master名字,这个名字代表Redis集群的master Redis。
当使用sentinel模式的时候,客户端就不要直接连接Redis,而是连接sentinel的ip和port,由sentinel来提供具体的可提供服务的Redis实现,这样当master节点挂掉以后,sentinel就会感知并将新的master节点提供给使用者。
sentinel模式基本可以满足一般生产的需求,具备高可用性。但是当数据量过大到一台服务器存放不下的情况时,主从模式或sentinel模式就不能满足需求了,这个时候需要对存储的数据进行分片,将数据存储到多个Redis实例中,就是下面要讲的。
cluster模式
sentinel模式的简介和配置,此处不再重复,看管担待=_=。
cluster的出现是为了解决单机Redis容量有限的问题,将Redis的数据根据一定的规则分配到多台机器。对cluster的一些理解:
cluster可以说是sentinel和主从模式的结合体,通过cluster可以实现主从和master重选功能,所以如果配置两个副本三个分片的话,就需要六个Redis实例。
因为Redis的数据是根据一定规则分配到cluster的不同机器的,当数据量过大时,可以新增机器进行扩容
这种模式适合数据量巨大的缓存要求,当数据量不是很大使用sentinel即可。
实际应用
实例1:通过id或者email找到User对象。如果一个值参考另外一个值。像下面一样,我们可以使用hashes让查询变得简单一点。如果你手工管理/update/delete这些引用。而在Redis中没有比较好的解决方法。

2.配置配置Redis的所有输入的命令日志。
config set slowlog-log-slower-than 0
3.配置监听路由。
sadd watch:leto 12339 1382 338 9338

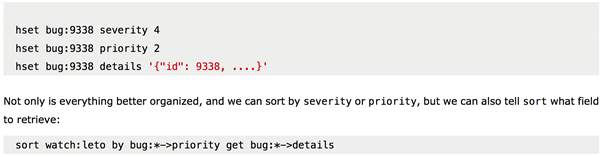
In addition to scan, hscan, sscan and zscan commands were also added.
参考书籍:
http://openmymind.net/redis.pdf
http://blog.csdn.net/a600423444/article/details/8944601
https://wenku.baidu.com/view/72eb832b5f0e7cd185253632.html
https://wenku.baidu.com/view/f1ab91df0722192e4436f6b0.html
http://www.cnblogs.com/WJ5888/p/4516782.html
https://wenku.baidu.com/view/4e6f9b156529647d26285206.html
https://www.cnblogs.com/kevingrace/p/5569938.html