第一个写一个爬网站文章标题的Python程序
使用模块为requests bs4
# -*- coding:utf-8 -*- import requests from bs4 import BeautifulSoup r = requests.get("https://www.sec-wiki.com/") soup = BeautifulSoup(r.text,'html.parser') content_list = soup.find_all('a',attrs={'rev':'news'}) for content in content_list: if len(content.text) < 10: pass else: print content.text
代码虽然不长,但是对新人入手还是有所帮助的
首先导入模块什么的不用说了
这里主要记录一下 如何使用beautifulesoup取得文章标题
打开chrome
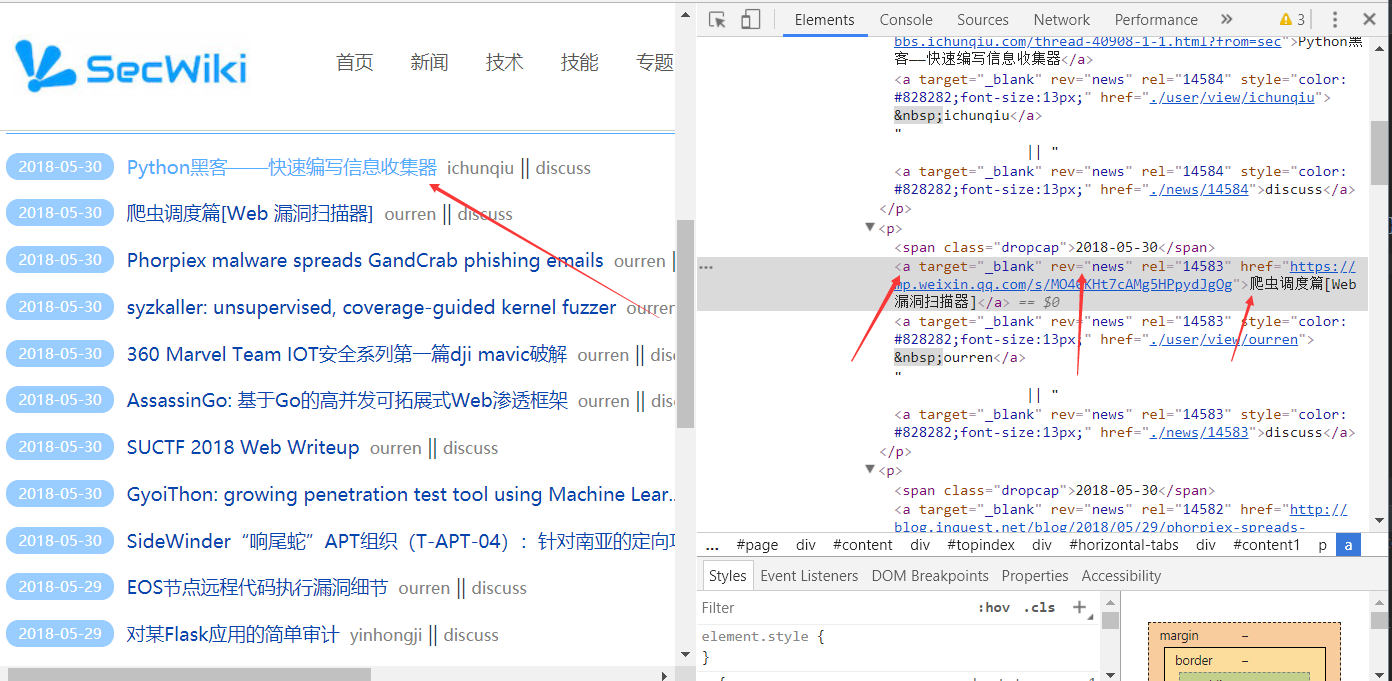
可以看到代码这里使用find_all函数取得所有的匹配结果,我们需要关注的是 这里
('a',attrs={'rev':'news'})
a代表的是标签。而attrs对应的则是这个标签下的属性
那么rev则为属性 news为属性的值
然后我们使用对象.text将标题输出出来
还有就是看我的这里
len(content.text) < 10
为什么呢 因为这里会匹配到其他的

所以
可以思考的
https://www.tuicool.com/articles/Y3MVz2R#c-30458
这里的
import requests # 导入网页请求库 from bs4 import BeautifulSoup # 导入网页解析库 # 传入URL r = requests.get('https://www.csdn.net/') # 解析URL soup = BeautifulSoup(r.text, 'html.parser') content_list = soup.find_all('div', attrs = {'class': 'title'}) for content in content_list: print(content.h2.a.text)
他的主要的一段是
content.h2.a.text
那么我们来打开网站源码看一看
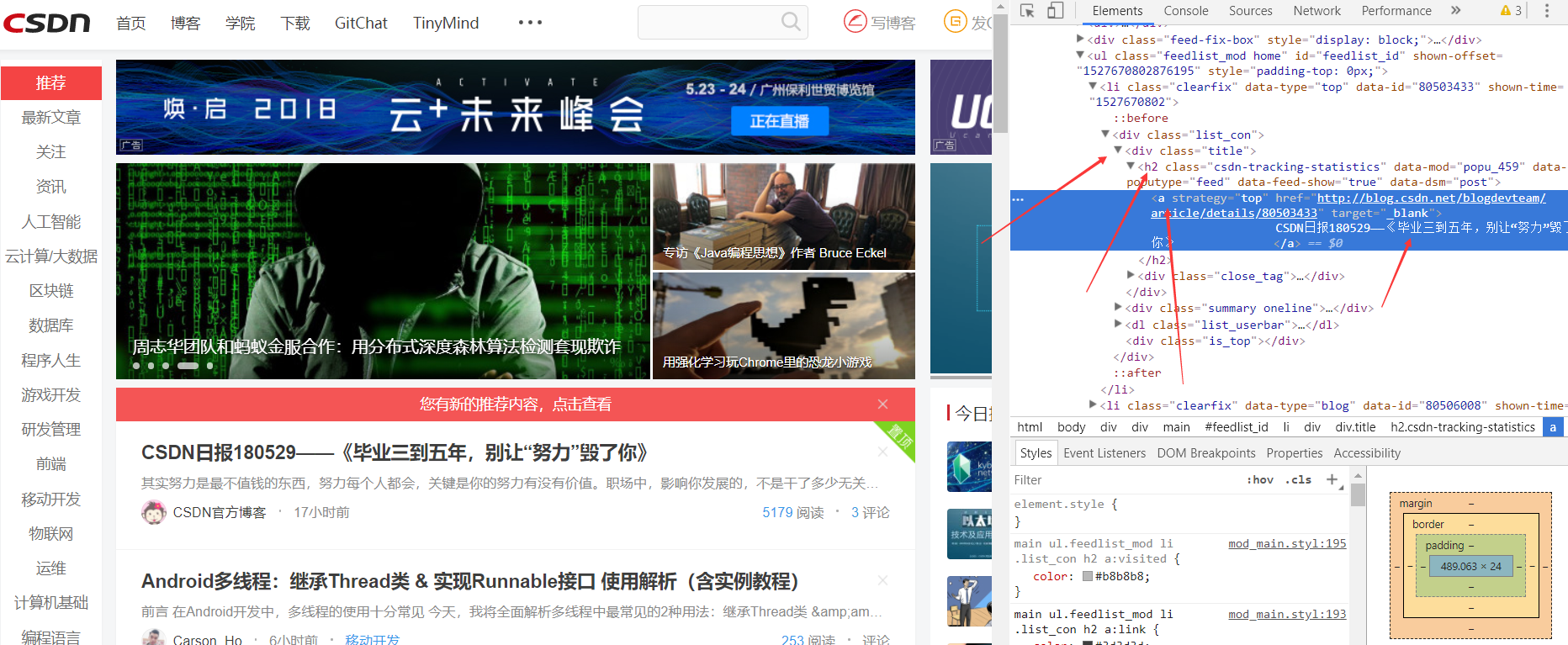
可以看到这里的每一个都在子标签下
但是secwiki就不一样了

如果我这里用上面的话 我不知道应该这个span应该怎么取
我试着和csdn写的一样 但是报错了。。这里的问题先放下
就先这样。。。
