sqoop分库分表shell导入脚本
之前的生产集群使用到了mysql的分库分表,所以抽取同一张表的数据就需要从不同的库与表中进行抽取了!话不多说先上图
分库:
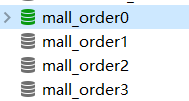
分表:
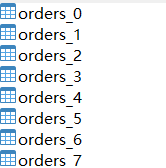
一、sqoop导入脚本
#!/bin/bash
#coding=UTF-8
sqoop=/data/cloudera/parcels/CDH-5.14.4-1.cdh5.14.4.p0.3/bin/sqoop
$sqoop import \
-Dhadoop.security.credential.provider.path=jceks://hdfs/nameservice1/conf/ps/dev181ps \
--connect jdbc:mysql://ip:3306/mall_order0 \
--table orders_0 \
--username root \
--password-alias dev181ps \
--delete-target-dir \
--target-dir /warehouse/malls/ods/ods_mall_order
注:这里有用到sqoop密码加密,参考sqoop密码明文问题解决
二、sqoop分库分表全量导入脚本
这里的hive表是已经创建好了的
#!/bin/bash
#coding=UTF-8
MysqlDB=mall_order
sqoop=/data/cloudera/parcels/CDH-5.14.4-1.cdh5.14.4.p0.3/bin/sqoop
for((i=0; i<=3; i++)); do
con_jdbc=jdbc:mysql://ip:3306/mall_order$i
echo -$con_jdbc
for((j=0; j<=7; j++)); do
$sqoop import \
-Dhadoop.security.credential.provider.path=jceks://hdfs/nameservice1/conf/ps/dev181ps \
--connect $con_jdbc \
--table orders_$j \
--username root \
--password-alias dev181ps \
--hive-import \
--hive-database malls\
--hive-table tmp_ods_mall_order \
--fields-terminated-by '\001'
done
done
三、sqoop导入参数详解
当然这里只是举了一个简单的例子,你可以根据你的业务分库分表规则去自定义shell脚本的传入参数与分库分表规则,因为每个规则都不同所以这里不做态度阐述,但是会详细列出sqoop导入hive的参数含义
--hive-import 插入数据到hive当中,使用hive的默认分隔符
--hive-overwrite 重写插入
--create-hive-table 建表,如果表已经存在,该操作会报错!
--hive-table [table] 设置到hive当中的表名
--hive-drop-import-delims 导入到hive时删除 \n, \r, and \01
--hive-delims-replacement 导入到hive时用自定义的字符替换掉 \n, \r, and \01
--hive-partition-key hive分区的key
--hive-partition-value hive分区的值
--map-column-hive 类型匹配,sql类型对应到hive类型
--direct 是为了利用某些数据库本身提供的快速导入导出数据的工具,比如mysql的mysqldump
性能比jdbc更好,但是不知大对象的列,使用的时候,那些快速导入的工具的客户端必须的shell脚本的目录下
--columns <列名> 指定列
-z, –compress 打开压缩功能
–compression-codec < c > 使用Hadoop的压缩,默认为gzip压缩
–fetch-size < n > 从数据库一次性读入的记录数
–as-avrodatafile 导入数据格式为avro
–as-sequencefile 导入数据格式为sqeuqncefile
–as-textfile 导入数据格式为textfile
--as-parquetfile 导入数据格式为parquet
--query 'select * from test_table where id>10 and $CONDITIONS' \ ($CONDITIONS必须要加上就相当于一个配置参数,sql语句用单引号,用了SQL查询就不能加参数--table )
--target-dir /sqoop/emp/test/ \ (指定导入的目录,若不指定就会导入默认的HDFS存储路径:/user/root/XXX.)
--delete-target-dir (如果指定目录存在就删除它,一般都是用在全量导入,增量导入的时候加该参数会报错)
--fields-terminated-by '\n' \ (指定字段分割符为',')
--null-string '\\N' \ (string类型空值的替换符(Hive中Null用\n表示))
--null-non-string '\\N' \ (非string类型空值的替换符)
--split-by id \ (根据id字段来切分工作单元实现哈希分片,从而将不同分片的数据分发到不同 map 任务上去跑,避免数据倾斜。)
-m 3 (使用3个mapper任务,即进程,并发导入)
一般RDBMS的导出速度控制在60~80MB/s,每个 map 任务的处理速度5~10MB/s 估算,即 -m 参数一般设置4~8,表示启动 4~8 个map 任务并发抽取。