原文OpenML: Machine Learning as a community
由于不能够插入jupyter因此代码都截图展示,但是都贴出了链接可以清晰查看
文章目录
社区共享式的机器学习
近年来机器学习吸引了很多人的注意,并且有很多甚至过剩的工具可用。然而大量的机器学习实验仍然在自己造轮子——缺乏共享的社区精神。OpenML是一个免费的机器学习实验数据库,它保存了各个数据库和相关的实验结果——每个人都能够免费获取这些数据库和实验结果。
本文尝试用尽量简短的语言来对OpenML进行介绍——OpenML概况及其对机器学习实验的有益之处。
下面我们用一个简单的机器学习例子来开始。简单起见,本文使用使用Iris dataset(鸢尾花数据库)。下面我们从scikit-learn中读取iris dataset并使用是折交叉验证来评估具有十棵树的随机森林——听起来很繁琐但实际上只需要不到不到十行程序。

原jupyter
通过上面这个简单的脚本我们得到了**95.33%**的平均准确率。很明显通过ML工具我们可以很简单的开始进行机器学习,这导致成千上万的人都在开发ML工具——不可避免地使得轮子被不断制造。事实上每个ML从业人员执行的任务通常都有很多重叠,可以通过重用社区中其他人人已经完成的工作来简化。在这个例子里,我们并没有从头开始建立一个随机森林模型,而是重用了来自社区地程序员编写的代码。
协同合作对人类族群是极其重要的——集体合作产生的智慧远超个体所能达到的极限。那么为什么不对ML做同样的事情?于Iris数据集而言,我们是否可以查看其他机器学习从业者做的相关工作呢?
回答这个问题是本文的目标之一。下文我们将在OpenML的帮助下探索是否可以做到这一点。首先,我们简要熟悉一些术语,并了解如何将前面的示例拆分为模块化组件。
OpenML组件(Components)

Dataset:OpenML拥有超过2000个可用数据集用于回归、分类、聚类、生存分析(survival analysis)、流处理任务(stream processing tasks)等等。任何人都可以将自己的数据库上传,上传后服务器会统计数据集的基本情况——包括类别数量、缺失值、特征数量等等。在之前的示例中,下面一行代码等价于从OpenML中获取数据集:
X, y=datasets.load_iris(return_X_y=True)
Task:机器学习任务于特定的数据集相联系,它定义了目标变量。同时也制定了评估方法如准确率和AUC(ROC曲线下于坐标轴围成的面积)等等。此外还制定了评估的流程(estimation procedure)如n折交叉验证 、n%的保留集(holdout set)等等。在上文示例中,下面这行代码中的函数参数描述了Task:
scores = cross_val_score(clf, X, y, cv=5, scoring=‘accuracy’)
Flow:描述了要执行的建模类型,可以是流程或一系列步骤,即scikit学习管道(scikit-learn pipeline)。示例使用了简单的随机森林模型,即Flow的组成部分:
clf = RandomForestClassifier(n_estimators=10, max_depth=2)
Run:将Flow和Task配对。Run得到用于评估的预测,实例中等价于Run的一行为:
scores = cross_val_score(clf, X, y, cv=5, scoring=‘accuracy’)
我们试图划分一个可以正常工作的简单的10行代码,这似乎有点令人困惑。但是,如果我们花几秒钟来审视上面介绍的4个组件,则可以认识到我们将一个简单的机器学习过程拆分成了一系列模块化任务。模块是计算机科学中的一个基本概念。如同乐高积木,模块是可以即插即用的。下面的代码段尝试使用所描述的OpenML组件的思想来重写先前的示例,以使我们了解到我们在实验中可能获得的收益。


清晰可见,将机器学习实验可以被拆分成各种不同的Task和Flow,然后Run将Task和Flow配对。这种方法可以帮助我们一次性定义组件,并且可以将其扩展到任意数据集、模型、评价指标。如果整个ML社区都定义了类似的Tasks以及用于实践的从简单到复杂的Flows,我们就可以构建个性化的ML管道(build custom working ML pipline),并能够将自己的工作与其他相同Tasks的工作相比较——OpenML正是为此而设计。在本文的下一部分中,我们将从头开始研究OpenML,看看OpenML对实验的拆分和对应的检索这些拆分后的部分。
使用OpenML
OpenML-Python可以通过pip和clone这个git库来安装现有的版本。那么OpenML是否值得我们安装呢?将代码拆分成了上文所说的代码段是有益的。一个整理过的具有这些代码段的例子可以从这里查看(呈现为一个Jupyter notebook)
接下来我们将从OpenML获取鸢尾花数据集,我们可以从OpenML官网来获取它——这是一个简单的办法,下文将用编程的方式来做到这些。OpenML Python API可以从这里找到。
从OpenML中检索Iris
在下面的例子中,我们将列出所有OpenML可用的数据集。输出格式可以定制,为了清晰和整洁,下文将以表格的形式来呈现检索过程(pandas DataFrame)

原jupyter
表格中的每一列都是数据集的一个属性,共有3125个数据集可用。接下来我们在列name中检索Iris并使用column列来排序结果。
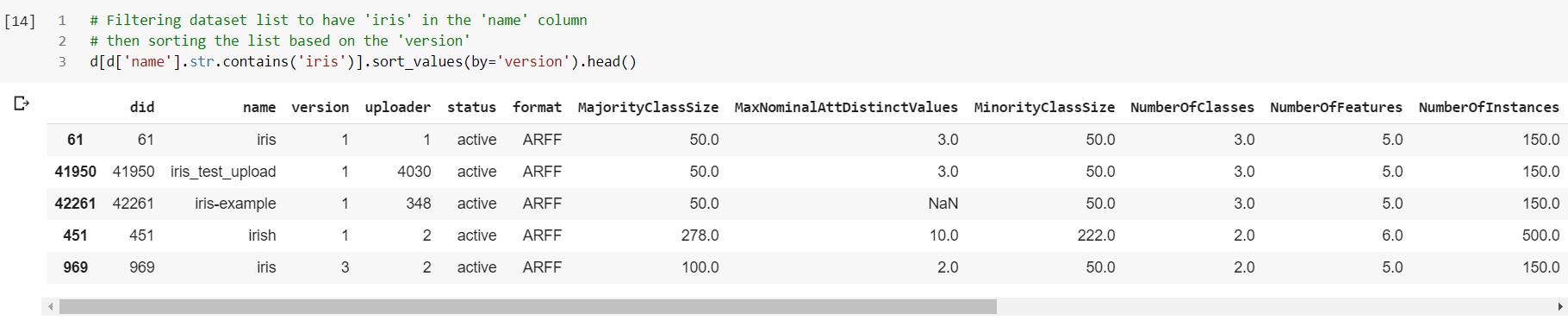
原jupyter
由上表我们知道鸢尾花数据集的第一个版本的ID是6,通过查看ID为61的数据集网址可以验证这一点。可以看到最初版本的鸢尾花数据集正是我们最常使用的——三类每一类50个样本共150个样本,每个样本有四个数值特征。当然我们可以通过程式化的方式来得到相同的信息。
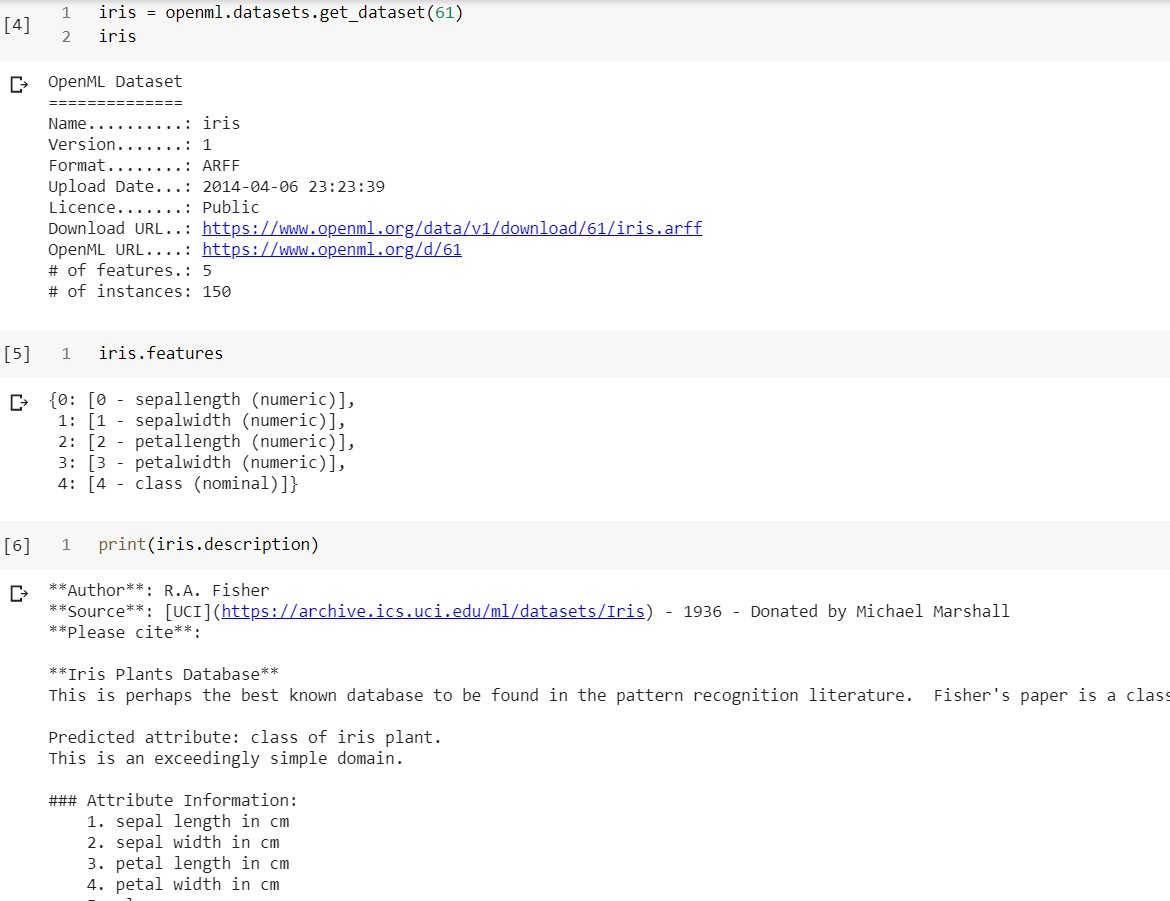
原jupyter
有了合适的可用数据集,让我们回顾一下上文所讨论的部分:数据集、任务、流程、运行。现在为止我们只使用了数据集部分,数据集组件与任务组件紧密联系。重申一下:任务描述数据集如何被使用。
从OpenML中检索Tasks
我们首先检索所有和鸢尾花数据集相关的机器学习任务。需要注意的是,我们仅仅认为该数据集与监督学习中的分类问题相关。下面我们来检索ID61的鸢尾花数据集相关的监督学习分类任务:
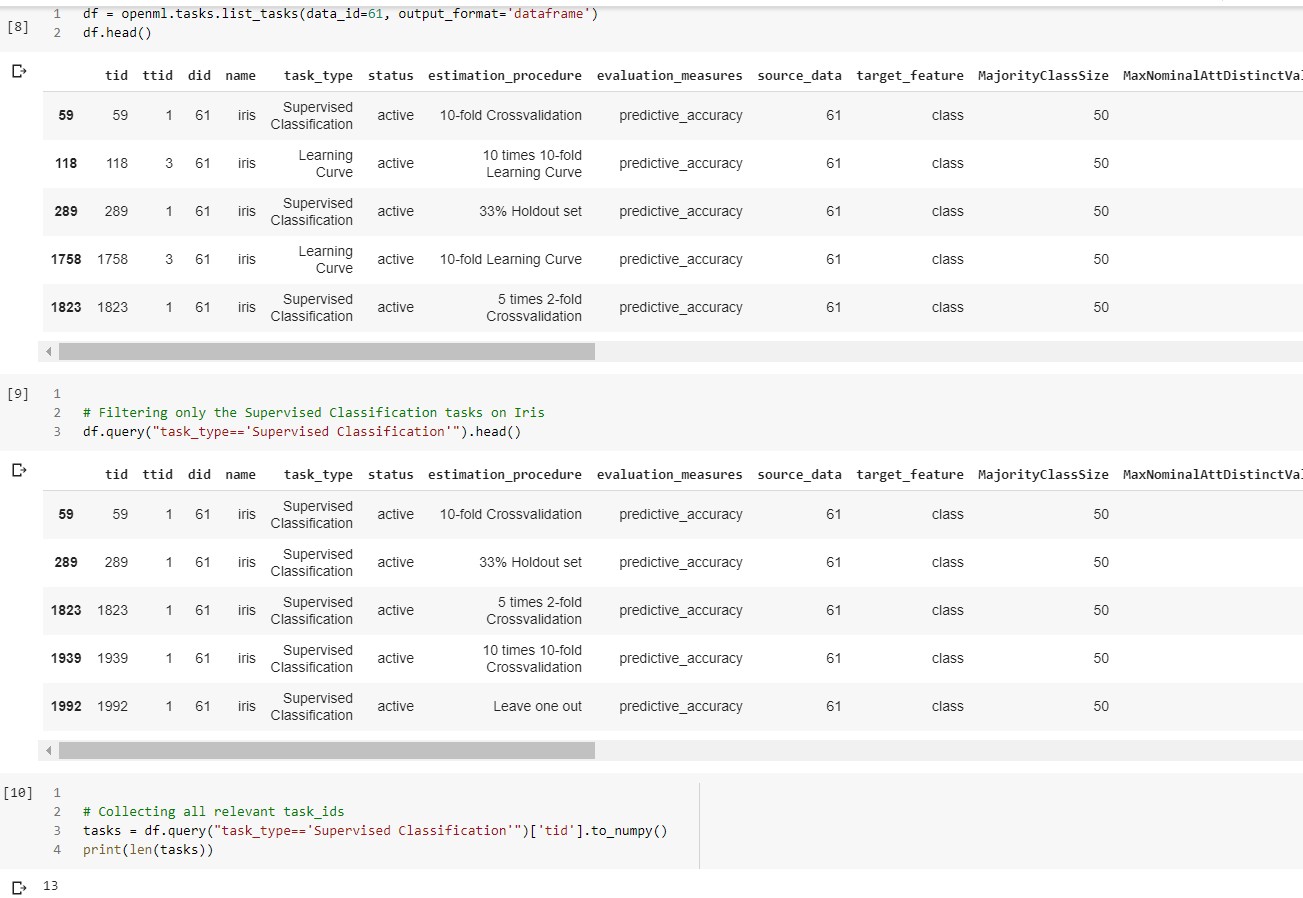
原jupyter
请仔细观察对于一个数据集(61),我们如何获得了13个我们感兴趣的任务ID。这说明数据集和任务之间具有的一对多关系。现在为止我们还有2个要探索的组件:流程,运行。
下面的代码段完成了:
- 筛选上面13个任务(数据集61的监督学习分类任务)相关的使用了精度指标的实验集合。
- 从上一步得到的集合中筛选最常见的基于scikit-learn的任务
- 从上一步得到的集合中筛选任务ID为59的任务
- 从上一步得到的集合中筛选含有“RandomForest”的条目


检索精确度最高的模型
机器学习从业者致力于获得最好的成绩(本文而言即精度),如果不能取得最好的成绩或者比拟现有的最好成绩,实验是不值得付出精力的。因此下文我们将根据精度对上述的筛选出的——数据集ID为61、监督学习、分类任务、精度指标、基于scikit-learn、任务ID为59、使用了“RandomForest”的实验进行排序。排序后获取精度最高的实验模型,即flowID为2629,runID为523926的模型

原jupyter
我们暂停一下并重新审视一下我们的例子。来自全球的多个用户(已将其实验结果上传到OpenML)在Iris上进行随机森林的实验,迄今为止看到的最高分是96.67%。这比我们的95.33%的简单模型要好。我们使用了基本的10倍交叉验证来评估包含10棵树(最大深度2)的随机森林。让我们看最佳的实验在什么地方与我们不同。
原jupyter
显而易见,我们的基础方法在两个层面上与得到的最佳表现不同:没有为交叉验证采用分层抽样(stratified sampling),此外随机森林的超参数也略有不同(max_depth = None)。
更进一步,不应该将方法局限于随即森林——我们的目标是获得最高的精度。考虑到OpenML用户的数量,一定有人会在其他模型上获得更好的Iris数据集精度。我们以编程方式检索该数据集的精度排序。
简而言之,我们现在将根据task_id = 59的任务对Iris数据集上所有基于scikit学习的模型的性能进行排序。

原jupyter
最高精度为98.67%,使用了SVC的变体。但是,如果我们检查相应的Flow描述,就会发现它使用了旧的scikit-learn版本(0.18.1),因此可能无法复制准确的结果。下面我们通过OpenML尝试一下使用NuSVC提高我们的精度。
在所需Task上运行最佳的Flow

原jupyter
我们通过使用相同的参数达到了相同的更高精度。即使我们从未尝试过NuSVC,并且会一直停留在“随机森林”的调参过程。这一发现无疑是有益的。
结尾部分
使用下面的命令能够将我们的运行结果上传到OpenML:
r.publish
这需要登录到https://www.openml.org/并生成自己的apikey。上传后每个人都可以查看你的结果,也许你可以在Iris数据集中获得的有史以来最好的性能而得名!
这篇文章绝非想成为OpenML的全部指南,其主要目标是帮助您熟悉OpenML术语,介绍API,建立与通用ML实践的联系,并简要了解作为社区合作的潜在好处。
为了更好地理解OpenML,请浏览OpenML文档。如果希望继续本文中给出的示例并进一步进行探索,请参考OpenML API。
OpenML-Python是一个开源项目,大家可以通过提交issue和Pull Requests的形式做出贡献。实际上,对OpenML社区的贡献不仅限于代码贡献。每个用户都可以使用OpenML通过共享数据,实验,结果来使社区变得更加丰富。
作为ML的从业者,我们可能依赖工具来完成任务。但是,作为一个整体,我们可以在更大程度上发掘其潜力。 Let us together, make ML more transparent, more democratic!
本文翻译自medium
作者:Neeratyoy Mallik
链接:OpenML: Machine Learning as a community
译文仅用于学习、研究和交流目的。转载请注明出处、译者等的完整链接。