“未加入LDPC码的VBLAST协作MIMO与加入LDPC码的协作MIMO性能比较”图,
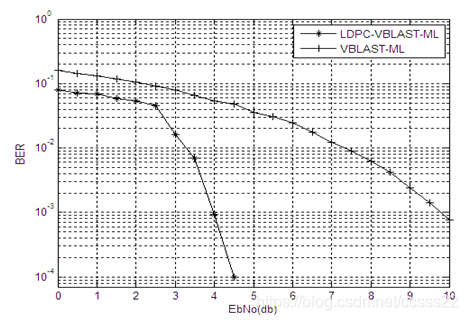
因为老板指出引入LDPC码,显然会产生系统性能增益,增强系统的可靠性,与未编码系统对比,意义不大;建议该系统应与其他信道编码(如卷积码、Turbo码)-VBLAST协作MIMO系统进行对比,来体现所采用系统的优势;
所以要补充的内容是在之前的系统模型的基础上

把LDPC码分别换成卷积码和TURBO码,将三个码的误码率曲线放在一个图上来比较LDPC码系统优劣,所以要做卷积码的中继协作,接收端迭代检测,和TURBO码的中继编码协作,接收端也采用迭代检测。(仍然采用2发送2中继2接收的协作MIMO系统)
要求画出三种不同码的结合VBALST结构的协作MIMO误码率曲线比较图
需要提供你仿真时LDPC码、卷积码和TURBO的详细相关参数(以免后续又有很多疑问)(关于卷积码的编码协作原理和TURBO编码的协作原理可参考文献1)
参数说明和仿真结果对比说明
> 基于LDPC的系统
参数指标:
|
|
|
|
| 1 |
R:码率 |
0.5 |
| 2 |
M,N:编码稀疏校验矩阵 |
512,256 |
| 3 |
系统内部迭代次数 |
40 |
| 4 |
系统外部迭代次数 |
4 |
| 5 |
调制方式 |
BPSK |
| 6 |
发送天线数目 |
2 |
| 7 |
接收天线数目 |
2 |
LDPC(512,256)的误码率曲线如下所示:

基于LDPC的系统的误码率曲线如下所示:

> 基于卷积编码的系统
首先,根据你所提供的参考论文中的:
> 基于卷积编码的系统
首先,根据你所提供的参考论文中的:

这个就是基于卷积编码的协作方式,这里,我们将根据这个结构,来设计卷积编码和维特比译码。
从上面的结构可知,整个卷积编码的结构可由CRC校验,卷积编码,打孔组成,其中打孔的作用就是讲卷积编码后的码率变为所需要的码率进行发送。
这里,我们采用如下的数据帧方式进行:
|
首先,每次发送的数据长度为:221,进行CRC校验之后为253,然后通过卷积编码之后的长度为512,注意,这里对于213卷积编码,需要将编码前的数据自动加3个0进行补偿。
|
||
|
这里,我们使用卷积编码的参数为213系统,编码码率为1/2,所以这里就不需要打孔了。
所以整个卷积编码的结构为校验,编码,译码,校验,四个部分构成。
参数指标:
|
|
|
|
| 1 |
R:码率 |
0.5 |
| 2 |
卷积编码 |
2,1,3 |
| 3 |
系统内部 |
这里没有设置该参数,因为这里采用的是213,参数比较简单,内部直接做判断,即搜索到最佳路径位置,即迭代次数写死了。 |
| 4 |
系统外部迭代次数 |
4 |
| 5 |
调制方式 |
BPSK |
| 6 |
发送天线数目 |
2 |
| 7 |
接收天线数目 |
2 |
最后的误码率曲线:

213+CRC校验的卷积编码误码率曲线。

> 基于Turbo编码的系统
参数指标:
首先,根据你所提供的参考论文中的:
这个就是基于卷积编码的协作方式,这里,我们将根据这个结构,来设计卷积编码和维特比译码。
从上面的结构可知,整个卷积编码的结构可由CRC校验,卷积编码,打孔组成,其中打孔的作用就是讲卷积编码后的码率变为所需要的码率进行发送。
这里,我们采用如下的数据帧方式进行:
|
首先,每次发送的数据长度为:221,进行CRC校验之后为253,然后通过卷积编码之后的长度为512,注意,这里对于213卷积编码,需要将编码前的数据自动加3个0进行补偿。
|
||
|
这里,我们使用卷积编码的参数为213系统,编码码率为1/2,所以这里就不需要打孔了。
所以整个卷积编码的结构为校验,编码,译码,校验,四个部分构成。
参数指标:
|
|
|
|
| 1 |
R:码率 |
等效码率为167/510 发送的时候补偿2个零,使其满足512一帧的帧长 |
| 2 |
初始生成多项式 |
1 0 1 1和 1 1 0 1 这两个作为两个RSC编码的多项式输入和多项式的输出相乘多项式 |
| 3 |
帧长 |
256 |
| 4 |
译码方式 |
Log map算法 |
| 5 |
系统外部迭代次数 |
4 |
| 6 |
调制方式 |
BPSK |
| 7 |
发送天线数目 |
2 |
| 8 |
接收天线数目 |
2 |
最后的误码率曲线:

单独的turbo仿真图:
完整的系统仿真结果如下所示:

通过对比,可知如下的仿真结果:
从单独的三种信道编译码可知,在SNR<2.5的时候,turbo性能优于卷积优于LDPC,但是当SNR > 2.5的时候,LDPC编译码性能快速上升,成为最优。
这三种编译码在系统中,系统的性能如下所示:

从整个系统的仿真结果可知,当SNR > 4的时候,LDPC性能最优。优于LDPC的编译码是基于校验位的,所以在实际中,如果信道对校验产生较大的干扰,那么会或多或少影响LDPC性能的发挥。因此,在SNR较小的时候,LDPC性能并不优于其他两种编码。
但是,如果我们增加LDPC的稀疏校验矩阵,并做到完美的去四环,那么其性能可以进一步提升。这里的LDPC参数为512,256.在LDPC中 属于短码类型的,其性能并不是LDPC一族中最优的,而Turbo码,在这里,我们采用了两个RSC编码的方式进行处理,其性能基本属于Turbo中的最优者,而卷积编码,我们在译码中,使用的是软判决处理,其性能也是最优者,此外,卷积编码从213扩展为217,其性能提升有限,而LDPC,做好完美的校验矩阵,其性能可以大幅提高,总的来讲,LDPC在这几组仿真中,其性能是最优的。

(这里再额外说明一下,由于LDPC仿真耗时间非常非常久,这里只能仿真短码,如果你需要仿真长码,我们只能单独对LDPC进行仿真,而对于LDPC长码在系统中的仿真,基本服务器也得仿真1~2天)