前言
文章内容输出来源:拉勾教育Java高薪训练营;
mybatis 占据 ORM 框架的半壁江山,我们是不仅要做到会使用,还得做到知其然更知其所以然。
mybatis 缓存分为一级缓存和二级缓存,那这两级缓存是怎么实现的呢?他们的存储结构,作用范围,失效场景你都了解吗?这里带领大家一起探索 mybatis 缓存实现的奥秘。
您将了解到:
- mybatis 一级缓存,二级缓存的概念
- mybatis 一级缓存源码剖实现以及特点
- mybatis 二级缓存源码实现以及特点
- 在自定义持久层框架中增加 缓存实现
- mybatis 整合 redis 实现分布式环境下缓存
- 源码学习资料
概念
在在 mybatis 缓存之前,我们先来说说什么是缓存?
缓存 这个词我们经常听到,甚至我们在工作的时候也都用到。那他到底是个什么东西?大家能说出来嘛?
在百度词条上是这样解释的。
我们就不深究,只要明白缓存为什么存在?是为了提高访问效率,怎样提高访问效率,因为计算机从内存中读取比从磁盘中读取数据快很多。相当于走路与火箭的速度差吧哈哈。所以一般都会是用内存做缓存。
那我们再来看看 mybatis 缓存。一样的它的存在就是为了提查询的效率,避免每次查询都要访问数据库而设计的。那为什么 mybatis 要设计两级缓存呢?分别有什么作用的呢?
这里我们先来说下一级缓存,mybatis 一级缓存 是基于SqlSession 中的,每个用户在执行查操作的时候都会通过一个 SqlSession 类来查找。那这个用户进行了多次相同的查询,每次都从数据库中取的话就会效率很低,所以 mybatis 在这种情况下就设计了一级缓存,只有当用户的第一次查询会从数据库从查询数据,然后会查询出的数据保存在缓存中,后续的重复查询就不会查询数据库了,而是会从缓存中取的。
那我们很容易就想到另外一个场景,当有多个用户都执行想通的查询操作呢?这样一级缓存就没有办法实现,每个SqlSession 都会去数据库中查询然后返回,所以这个时候 mybatis 就设计出了二级缓存,多个用户在查询的时候,只要一个SqlSession 拿到了数据就会放入缓存中,其他的SqlSession 不会从数据库中取数据了,而是从缓存中读取,从而提高查询效率。
一级缓存
上面我们看了一些概念性的东西,我们接下来先看看一级缓存的效果,然后在带着问题看源码,看看 mybatis 一级缓存是怎实现的呢。
一级缓存的效果
我们创建一个maven 项目,引入依赖。做好简单的准备工作。这里我就不贴了。感兴趣的可以自己搭建一个demo .我这里直接上测试方法。
@org.junit.Test
public void Test1() throws Exception{
InputStream inputStream= Resources.getResourceAsStream("SqlMapConfig.xml");
SqlSession sqlSession = new SqlSessionFactoryBuilder().build(inputStream).openSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
System.out.println("第一次:");
List<User> users = mapper.selectAll();
System.out.println(users.get(0));
System.out.println("第二次:");
List<User> users2 = mapper.selectAll();
System.out.println(users2.get(0));
System.out.println("两对象是否一致");
System.out.println(users.equals(users2));
}
通过Resource加载SqlMapConfig.xml 配置文件,然后通过SqlSessionFactoryBUilder 来获取一个SqlSession.
这里我们使用mapper 的通用代理方法。获取到我们对应的UserMapper 接口。我们这里就调用selectAll() 方法。
先后调了两次,这就满足我们前面说的一级缓存的场景。好我们现在来执行看下结果。
可以看到第一次的时候会创建数据库连接,从数据库查询数据,但是第二次,就没有走数据库了,而是从缓存中获取数据。并且和一看到两个对象是一样的。这说明什么问题?说明一级缓存缓存的整个对象对吧。
源码解读
我们接下来就看看一级缓存是怎么实现的。
我们对SqlSession.getMapper() 方法了解吗?这里就不多讲,涉及到JDK的动态代理实现。有兴趣的可以看下,主要是MapperProxy的invoke()方法。
我们只要知道最终也是调用 SqlSession 中的对应的 select 或者其他方法。所以我们直接来看select 方法。来到SqlSession 的实现类 DefaultSqlSession 类看到 select 方法最终都是调用 selectList 方法。
这个方法中可以发现直接把请求交给executor 执行器来执行了。我们接下来看看这个 query 方法。
到这大伙是不是就发现一个关于 cache 的字眼啦,没错就是它。我们先对整体说下,BoundSql 是用来保存动态SQL 解析的内容的。而这个 createCacheKey() 就是创建一个cacheKey 对象。我们可以看下这个方法。
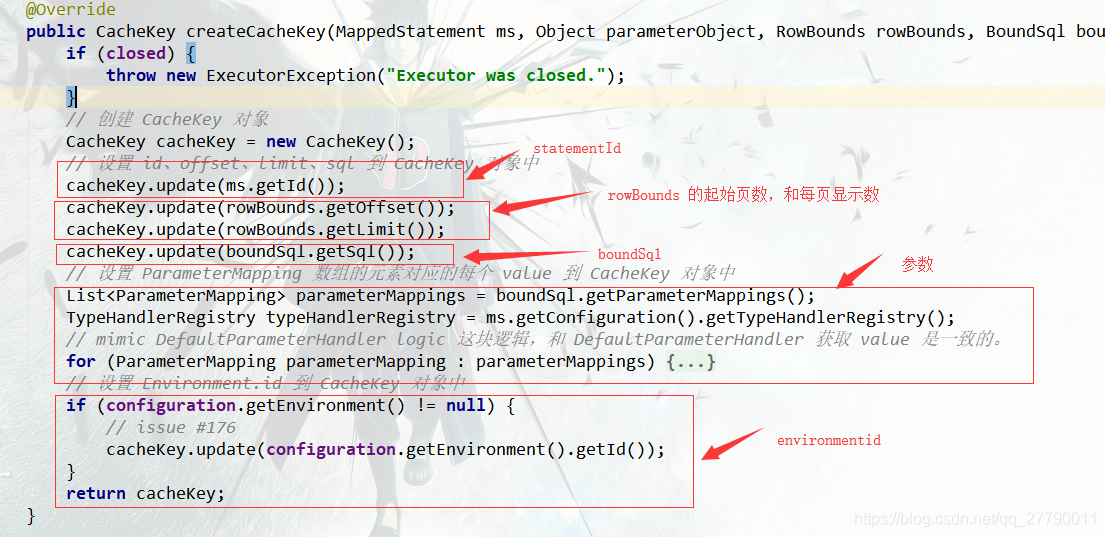
可以看到 cacheKey 由environmentid,mappedStatement.id,参数param ,boundSql,rowSql 组成。所以在这里要就可以知道为什么一级缓存是基于SqlSession 的了,因为每个SqlSession 的mappedStatement.id 是不一样的。
然后我们再回到query 方法,发现它调了同名的方法。这个方法可以看到是从 localCache 中判断这个cacheKey 是否存在,存在的话就从缓存中获取,不存在的话就从数据库查询数据并保存到缓存中。
我们先来看下localCache 是什么
LocalCache是一个PerpetualCache 缓存对象,基于HashMap实现了cache 。所以mybatis 的一级缓存是存放在HashMap 中的。
到这基本上一级缓存的的实现就清楚了,总结一下: mybatis 一级缓存是基于SqlSession 的。每个SqlSession 会通过environmentid,mappedStatement.id,参数param ,boundSql,rowSql 创建一个cacheKey ,然后查询的时候先判断localCache 中是否含有这个cacheKey ,如果有就从缓存中读取数据。如果没有就从数据库中查询数据并将查询出的对象放入缓存中。
一级缓存的失效场景
我们前面知道了一级缓存的存储结构以及作用范围,那么一级缓存什么时候会失效呢?
在这之前我们先来想一个问题,SqlSession 在第一次查询之后,将结果保存的缓存中,接着又修改了数据,然后在取数据是从缓存中取还是从数据库中取?
直觉告诉我们肯定是从数据库取对不对,因为如果从缓存中取,那数据修改了,读到的数据就和实际的不一致了。
我们来简单验证下:还是这个测试,我们中间加一个修改的操作。这里还是把完整的测试代码贴出来。
@org.junit.Test
public void Test1() throws Exception{
InputStream inputStream= Resources.getResourceAsStream("SqlMapConfig.xml");
SqlSession sqlSession = new SqlSessionFactoryBuilder().build(inputStream).openSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
System.out.println("第一次:");
List<User> users = mapper.selectAll();
System.out.println(users.get(0));
System.out.println("修改操作");
User user=new User();
user.setUsername("程序员爱酸奶");
user.setId(1);
mapper.update(user);
sqlSession.commit();
System.out.println("第二次:");
List<User> users2 = mapper.selectAll();
System.out.println(users2.get(0));
System.out.println("两对象是否一致");
System.out.println(users.equals(users2));
}
这里大家注意一下SqlSession 默认是不提交事物的,所以修改之后我们需要手动提交。或者在开始创建SqlSession 时。openSession(true)表示自动提交事物。如果我们没有自动提交事物,第二次获取的数据改变了吗?
答案是改变了,有兴趣的同学可以试试。之所以改变了,是因为在执行update 的时候,会清除缓存,然会在查询是从数据库读取的。因为这个查询-修改-查询三步操作一起组成了事物。所以所以我们第三次取到的数据是修改后的数据,但是其实这个时候事物还没哟提交。所以在数据库中没有改变的。这里就和缓存没关系了。所以我们这里还是设置提交事物。然后来看看:
可以发现缓存是失效的,从新查询了数据库。源码也很简单,在BaseExecutor 中执行update 方法,之前会先清除缓存。
所以在执行了update /insert/delete 等操作后,mybatis 一级缓存就会失效。
二级缓存
前面一级缓存说了那么多,其实二级缓存和一级缓存的实现是一样的,只是作用范围不一样。
原理
mybatis 二级缓存也是通过PerpetualCache 缓存对象存储的,所以存储结构也是基于HashMap的。
二级缓存是基于mapper文件的namespace 的。也就是说多个SqlSession 可以共享一个mapper 中的二级缓存区域。
一个sqlSession 的会将执行的结果保存到二级缓存区,其他的SqlSession在获取的时候,不会从数据库获取数据,而是从缓存中获取数据。但是最终得到的对象是不相等的,因为二级缓存中缓存的是数据,而不是对象。
当其中有一个SqlSession 执行了事物提交操作,就会清空二级缓存,导致二级缓存失效,其他的SqlSession 想要获取数据,需要从新从数据库取。
我们先不开启二级缓存,然后使用两个SqlSession 来执行相同的操作。测试代码如下:
@org.junit.Test
public void Test2() throws Exception{
InputStream inputStream= Resources.getResourceAsStream("SqlMapConfig.xml");
SqlSessionFactory build = new SqlSessionFactoryBuilder().build(inputStream);
SqlSession sqlSession = build.openSession();
SqlSession sqlSession1 = build.openSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
UserMapper mapper1 = sqlSession1.getMapper(UserMapper.class);
System.out.println("第一次:");
List<User> users = mapper.selectAll();
System.out.println(users.get(0));
sqlSession.close();
System.out.println("第二次:");
List<User> users2 = mapper1.selectAll();
System.out.println(users2.get(0));
System.out.println("两对象是否一致");
System.out.println(users.equals(users2));
}
这里我们注意一下,在第二次操作前,要先将第一次的SqlSession 关闭掉。知道为什么吗?因为事物的特性,大家可以试验下嘿嘿。
开启二级缓存
可以看到两个SqlSession 分别从数据库读取数据,并且两个对象是不一样的。我们现在开启二级缓存
<settings>
<setting name="cacheEnabled" value="true" />
</settings>
在mapper.xml 文件中开启
<!--开启二级缓存-->
<cache ></cache>
在实体类对象中需要序列化对象,因为二级缓存不一定是放在内存中,也可能放在磁盘中。当然我们这里是否序列化都没有关系。
接下来就可以测试了,还是上面的代码,但是执行结果却不同了。
可以看到第一次是从数据库读取的,但是第二次就没有从数据库读取,而是从缓存中读取的数据这个0.5 表示命中率。说明不同的 SqlSession 是可以共享数据的。但是我们也会发现虽然第二次事从缓存中读取的,但是两个对象却不相等,这是为什么呢?因为二级缓存,存储的仅仅是数据,而不是对象,在其他Sqlsession 从缓存中取数据的时候,创建一个新的对象返回。而一级缓存是保存的对象,所以是相同的。
手动实现一级缓存。
我们就不用考虑太复杂,手动实现以下只是为了我们更熟悉核心思想。每个SqlSession 一个缓存,缓存是使用的存储格式,以及失效生效场景。
引入cache 的相关类
我们首先借用 mybatis 中这几个类。CacheKey 主要是存储key的。而PerpetualCache 是实现缓存的实现类。
这里面主要就是重写 equals 方法和 hashCode 方法。所以这四个部分代码就不贴了。
SimpleExecutor 的具体实现
我们直接来看Executor 类中我们怎么实现。
1、首先初始化 localCache 对象,这样不同的SqlSession 就是不同的缓存了。限制作用域。
2、query 方法,创建一个cacheKey ,判断 localCache 中是否存在这个 cacheKey ,存在直接从缓存中取出返回,不存在就从数据库中查询。
3、createCacheKey 方法,这里我们就把mapper.id ,boundSql,以及参数作为key 的关键信息。这里如果对代码有些看不明白的可以先参考我的另一篇文章,自己定义一个持久层框架。我们这里增加缓存的功能就是在这个框架上修改的。
public CacheKey createCacheKey(Mapper mapper, BoundSql boundSql, Object... parameter) throws Exception{
// 创建 CacheKey 对象
CacheKey cacheKey = new CacheKey();
// 设置 id
cacheKey.update(mapper.getId());
// 设置 ParameterMapping 数组的元素对应的每个 value 到 CacheKey 对象中
List<ParameterMapping> parameterMappingList = boundSql.getParameterMappingList();
Class<?> parmType = mapper.getParmType();
for (int i = 0; i < parameterMappingList.size(); i++) {
Object value=getValue(parmType,parameterMappingList.get(i),parameter);
cacheKey.update(value);
}
return cacheKey;
}
private Object getValue(Class<?> parmType,ParameterMapping parameterMapping, Object... parameter) throws Exception {
Object value=null;
String content = parameterMapping.getContent();
if (isJavaType(parmType)) {
value=parameter[0];
}else {
Field declaredField = parmType.getDeclaredField(content);
declaredField.setAccessible(true);
value = declaredField.get(parameter[0]);
}
return value;
}
4、queryFromDatabase 方法,从数据库查询操作,会将结果保存到缓存中。
// 从数据库中读取操作
private <E> List<E> queryFromDatabase(Configuration configuration,Mapper mapper,CacheKey key, BoundSql boundSql,Object parameter) throws Exception {
List<E> list;
try {
// 执行读操作
list = doQuery(configuration,mapper, boundSql,parameter);
} finally {
localCache.removeObject(key);
}
// 添加到缓存中
localCache.putObject(key, list);
return list;
}
5、update ()方法,需要增加清除缓存操作。
到这里我们就基本上实现了一级缓存的效果。这里我贴出 SimpleExecutor 类完整代码吧。都是在这个类中实现的。感兴趣的可以看下,不感兴趣的直接跳过吧。
public class SimpleExecuter implements Executer{
private Connection connection;
protected PerpetualCache localCache;
public SimpleExecuter(){
this.localCache = new PerpetualCache("LocalCache");
}
public <E> List<E> query(Configuration configuration, Mapper mapper, Object... parameter) throws Exception {
BoundSql boundSql=getBoundSql(mapper.getSql());
CacheKey key = createCacheKey(mapper,boundSql,parameter);
// 先从缓存中获取
List<E> list=(List<E>) localCache.getObject(key);
if (list != null) {
return list;
} else {
// 获得不到,则从数据库中查询
list = queryFromDatabase(configuration,mapper, key, boundSql,parameter);
}
return list;
}
// 从数据库中读取操作
private <E> List<E> queryFromDatabase(Configuration configuration,Mapper mapper,CacheKey key, BoundSql boundSql,Object parameter) throws Exception {
List<E> list;
try {
// 执行读操作
list = doQuery(configuration,mapper, boundSql,parameter);
} finally {
localCache.removeObject(key);
}
// 添加到缓存中
localCache.putObject(key, list);
return list;
}
public <E> List<E> doQuery(Configuration configuration, Mapper mapper,BoundSql boundSql, Object... parameter) throws Exception{
PreparedStatement preparedStatement=preHandle(configuration,mapper,boundSql,parameter);
//执行sql
ResultSet resultSet = preparedStatement.executeQuery();
return resultHandle(mapper,resultSet);
}
@Override
public int update(Configuration configuration, Mapper mapper, Object... parameter) throws Exception {
// 清空本地缓存
clearLocalCache();
BoundSql boundSql=getBoundSql(mapper.getSql());
// 执行写操作
PreparedStatement preparedStatement=preHandle(configuration,mapper,boundSql,parameter);
return preparedStatement.executeUpdate();
}
public void clearLocalCache() {
// 清理 localCache
localCache.clear();
}
/**
* 创建cacheKey
* @param mapper
* @param boundSql
* @param parameter
* @return
* @throws Exception
*/
public CacheKey createCacheKey(Mapper mapper, BoundSql boundSql, Object... parameter) throws Exception{
// 创建 CacheKey 对象
CacheKey cacheKey = new CacheKey();
// 设置 id
cacheKey.update(mapper.getId());
// 设置 ParameterMapping 数组的元素对应的每个 value 到 CacheKey 对象中
List<ParameterMapping> parameterMappingList = boundSql.getParameterMappingList();
Class<?> parmType = mapper.getParmType();
for (int i = 0; i < parameterMappingList.size(); i++) {
Object value=getValue(parmType,parameterMappingList.get(i),parameter);
cacheKey.update(value);
}
return cacheKey;
}
/**
* 准备工作
* 连接数数据库
* 解析sql
* 替换占位符
* @param configuration
* @param mapper
* @param parameter
* @return
* @throws Exception
*/
private PreparedStatement preHandle(Configuration configuration, Mapper mapper,BoundSql boundSql, Object... parameter)throws Exception{
String sql=boundSql.getSqlText();
List<ParameterMapping> parameterMappingList = boundSql.getParameterMappingList();
//获取连接
connection=configuration.getDataSource().getConnection();
//获取preparedStatement,并传递参数值
PreparedStatement preparedStatement=connection.prepareStatement(sql);
Class<?> parmType = mapper.getParmType();
for (int i = 0; i < parameterMappingList.size(); i++) {
Object value=getValue(parmType,parameterMappingList.get(i),parameter);
preparedStatement.setObject(i+1,value);
}
System.out.println(sql);
return preparedStatement;
}
/**
* 获取参数对应的值
* @param parmType
* @param parameterMapping
* @param parameter
* @return
* @throws Exception
*/
private Object getValue(Class<?> parmType,ParameterMapping parameterMapping, Object... parameter) throws Exception {
Object value=null;
String content = parameterMapping.getContent();
if (isJavaType(parmType)) {
value=parameter[0];
}else {
Field declaredField = parmType.getDeclaredField(content);
declaredField.setAccessible(true);
value = declaredField.get(parameter[0]);
}
return value;
}
private boolean isJavaType(Class<?> parmType){
String s = parmType.getSimpleName().toUpperCase();
return s.equals("INTEGER")|| s.equals("STRING")|| s.equals("LONG");
}
/**
* 封装结果集
* @param mapper
* @param resultSet
* @param <E>
* @return
* @throws Exception
*/
private <E> List<E> resultHandle(Mapper mapper,ResultSet resultSet) throws Exception{
ArrayList<E> list=new ArrayList<>();
//封装结果集
Class<?> resultType = mapper.getResultType();
while (resultSet.next()) {
ResultSetMetaData metaData = resultSet.getMetaData();
Object o = resultType.newInstance();
int columnCount = metaData.getColumnCount();
for (int i = 1; i <= columnCount; i++) {
//属性名
String columnName = metaData.getColumnName(i);
//属性值
Object value = resultSet.getObject(columnName);
//创建属性描述器,为属性生成读写方法
PropertyDescriptor propertyDescriptor = new PropertyDescriptor(columnName,resultType);
Method writeMethod = propertyDescriptor.getWriteMethod();
writeMethod.invoke(o,value);
}
list.add((E) o);
}
return list;
}
/**
* 解析自定义占位符
* @param sql
* @return
*/
private BoundSql getBoundSql(String sql){
ParameterMappingTokenHandler parameterMappingTokenHandler = new ParameterMappingTokenHandler();
GenericTokenParser genericTokenParser = new GenericTokenParser("#{","}",parameterMappingTokenHandler);
String parse = genericTokenParser.parse(sql);
return new BoundSql(parse,parameterMappingTokenHandler.getParameterMappings());
}
public void close() throws Exception {
connection.close();
}
@Override
public void commit() throws Exception{
connection.commit();
}
}
测试
我们一样的来写一个测试类
@org.junit.Test
public void Test11() throws Exception{
InputStream inputStream= Resources.getResources("SqlMapperConfig.xml");
SqlSession sqlSession = new SqlSessionFactoryBuilder().build(inputStream).openSqlSession();
UserDao mapper = sqlSession.getMapper(UserDao.class);
System.out.println("第一次:");
List<User> users = mapper.selectAll();
System.out.println(users.get(0));
System.out.println("第二次:");
List<User> users2 = mapper.selectAll();
System.out.println(users2.get(0));
System.out.println("两对象是否一致");
System.out.println(users.equals(users2));
}
下面是执行结果
可以明显的看到,第二次是走的缓存,并且返回的对象是相同的。
我们接下来,在两次查询中间,增加一次修改操作。
@org.junit.Test
public void Test11() throws Exception{
InputStream inputStream= Resources.getResources("SqlMapperConfig.xml");
SqlSession sqlSession = new SqlSessionFactoryBuilder().build(inputStream).openSqlSession();
UserDao mapper = sqlSession.getMapper(UserDao.class);
System.out.println("第一次:");
List<User> users = mapper.selectAll();
System.out.println(users.get(0));
System.out.println("修改操作");
User user=new User();
user.setUsername("张三");
user.setId(1);
mapper.update(user);
System.out.println("第二次:");
List<User> users2 = mapper.selectAll();
System.out.println(users2.get(0));
System.out.println("两对象是否一致");
System.out.println(users.equals(users2));
}
结果如下:
可以看到这个时候第二次就没有从缓存中读取了,而是从数据库中读取的。
我们再来看看两个SqlSession 的能公用一级缓存不能。
@org.junit.Test
public void Test12() throws Exception{
InputStream inputStream= Resources.getResources("SqlMapperConfig.xml");
SqlSessionFactory build = new SqlSessionFactoryBuilder().build(inputStream);
SqlSession sqlSession = build.openSqlSession();
SqlSession sqlSession1 = build.openSqlSession();
UserDao mapper = sqlSession.getMapper(UserDao.class);
UserDao mapper1 = sqlSession1.getMapper(UserDao.class);
System.out.println("第一次:");
List<User> users = mapper.selectAll();
System.out.println(users.get(0));
System.out.println("第二次:");
List<User> users2 = mapper1.selectAll();
System.out.println(users2.get(0));
System.out.println("两对象是否一致");
System.out.println(users.equals(users2));
}
结果如下:
说明是没有公用了,那么到这里我们就验证了我们自定义的一级缓存,和 mybatis 的一级缓存的效果是一样的。这也是 mybatis 一级缓存的核心实现了。有兴趣的小伙伴可以是试试,并且可以试试怎么实现二级缓存啊哈哈。
二级缓存整合 redis
上面我们说二级缓存在分布式环境下存在问题。比喻说一个用户请求了这台服务,在这台服务上有缓存,但是另外一个用户请求了另一台服务,导致没有从缓存中获取,而是从数据库获取的。这就存在问题啦。
所以解决上述问题,我们很容易就想到使用 redis 做二级缓存,不管那台服务都会先从 redis 中查询,没有查到才会到数据库中查询,并包结果保存到缓存中。
配置
你想到的事情,人家也想到了哈哈,所以有现成的实现工具,我们直接来使用试试。
1、增加依赖
<!-- mybatis 整合Redis 实现二级缓存-->
<dependency>
<groupId>org.mybatis.caches</groupId>
<artifactId>mybatis-redis</artifactId>
<version>1.0.0-beta2</version>
</dependency>
2、mapper.xml 中type 指向我们的缓存
<!-- 开启二级缓存-->
<cache type="org.mybatis.caches.redis.RedisCache"></cache>
3、增加redis.properties 配置
redis.host=localhost
redis.port=6379
redis.connectionTimeout=5000
redis.password=
redis.database=0
上面这样就配置好了一个基于redis 的二级缓存啦。
测试
我们这里简单测试一下,只要测试redis 缓存生效没有就可以了。
测试方法还是和上面一样:
@org.junit.Test
public void Test3() throws Exception{
InputStream inputStream= Resources.getResourceAsStream("SqlMapConfig.xml");
SqlSessionFactory build = new SqlSessionFactoryBuilder().build(inputStream);
SqlSession sqlSession = build.openSession();
SqlSession sqlSession1 = build.openSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
UserMapper mapper1 = sqlSession1.getMapper(UserMapper.class);
System.out.println("第一次:");
List<User> users = mapper.selectAll();
System.out.println(users.get(0));
sqlSession.close();
System.out.println("第二次:");
List<User> users2 = mapper1.selectAll();
System.out.println(users2.get(0));
System.out.println("两对象是否一致");
System.out.println(users.equals(users2));
}
结果:
可以看到第二次是走缓存的,那我们再看下 redis 。发现是有数据的,并且key是永久生效的。
说明整合Redis 实现二级缓存是成功的,有兴趣的可以自己在研究下。
源码解析
我们上面知道了使用,接下来我们看看是怎么实现的,可以从我们mapper 中配置的开启二级缓存来入手,这里 type 指向的RedisCache 类,我们来看下。
可以发现,RedisCache 是继承 mybatis 中的Cache 实现的,并且可以发现整个jar 就这几个类。
在 RedisCache 主要就是初始化的过程,先获取配置文件的信息,然后创建一个 Jedis 连接池。
获取配置文件并解析就是通过 RedisConfigurationBuilder 类来完成的。并且把信息保存在 RedisConfig 对象中。可以看到是带有默认配置的。
主要的方法就是两个,存缓存,取缓存。当然还有清除缓存这些肯定有的。
整体流程就是:初始化阶段,先解析配置文件 将配置信息读取到redisConfig 中,然后就和 mybatis 自带的 PerpetualCache 是一样的。只是 putObject 方法和 getObject 方法不一样而已。
总结
上面说了这么多,大家要知道 mybatis 的一二级缓存的实现,存储结构,生命周期以及失效场景。这篇文章希望对大家有帮助。
如果您觉得好看,记得给我点个赞喔!!!
如果您觉得好看,记得给我点个赞喔!!!
如果您觉得好看,记得给我点个赞喔!!!
源码 我放到了码云上,感兴趣的小伙伴可以自行下载研究喔。